For the formation of adequate models of objects of statistical research, with the possible high cost of a measuring experiment or the process of obtaining data, fast and “correct” identification (recognition) of the probability distribution density (PDD) based on the construction of simple histogram estimates is required. The requirement for rapid identification can be considered equivalent to having a limited and small amount of data. The article proposes a theoretically substantiated method for constructing a histogram filter (HF), which is a linear combination of the amount of data in adjacent intervals with constant weight coefficients, which can be expressed in terms of a single coefficient k -the smoothing parameter. The estimation of the smoothing coefficient is based on the minimization of the modified chi-square test. The theorem given in the article establishes that the value of the mathematical expectation of the chisquare test, after applying the HF, decreases by k times compared to the standard mathematical expectation of the criterion with a unit inclusion function.
Реферат- Для формирования адекватных моделей объектов статистических исследований, при возможной высокой стоимости измерительного эксперимента или процесса получения данных, требуется быстрая и «правильная идентификация (распознавания) плотности распределения вероятности (ПРВ) на основе построения простых гистограммных оценок. Требование быстрой идентификации можно считать эквивалентным наличию ограниченного и малого объема данных. В статье предлагается теоретически обоснованная методика построения гистограммного фильтра $( \Gamma \Phi )$,представляющего собой линейную комбинацию количества данных на соседних интервалах с постоянными весовыми коэффициентами, которые могут быть выражены через один коэффициент $k -$ параметр сглаживания. Оценка кооффициента сглаживания осуществляется на основе минимизации модифицированного критерия хи-квадрат. Приведенная в статье теорема устанавливает, что значение математического ожидания критерия хи-квадрат, после применения ГФ, уменьшается в краз по сравнению со стандартным математическим ожиданием критерия с единичной функцией включения. Коэффициент сглаживания определяется сложной зависимостью числа данных, параметров идентифицируемой ПРВ (информационные коэфициенты Фишера первого и второго порядка) и ГФ (количество и ширина интервалов групирования). В статье показано,что взаимосвязь между числом данных, количеством и шириной интервалов группирования является нелинейной и имет только численное решение. Рассмотренные примеры моделирования работы ГФ характеризуют эфективность идентификации ПРВ, целесообразность его применения в научных и прикладных статистических исследованиях.
## I. Введение
роблематика гистограммных оценок плотности распределения вероятности (ПРВ) хорошо известна: отсутствие единых взглядов на определение числа интервалов группирования данных (ГОСТ Р 50.1.033- 2001 Прикладная статистика) и сильная изрезанность гистограммы при относительно малом числе наблюдений [1,2].
Особую важность и актуальность точные гистограммные оценки закона распределения приобретают в случае требований его быстрой идентификации (распознавания), возможной высокой стоимости измерительного эксперимента или процесса получения данных. Требование быстрой идентификации (распознавания) закона распределения в данном случае можно считать эквивалентным малому объему данных.
Устранение проблем изрезанности гистограммы заключается в применении гистограммных фильтров (ГФ), например, усредняющего, медианного, гауссовского и др. [1,3-5]. В то же время, их применение эмпирически
интуитивно и исходит, в основном, из практических соображений. В работе предлагается теоретически обоснованная методика реализации ГФ, работающего на небольшом количестве данных, устраняющего изрезанность гистограммы, дающего «правильную» идентификацию закона распределения, ослабляющего зависимость «правильной» идентификации от числа интервалов группирования данных.
В работе развиваются идеи, предложенные в [6]. Прежде всего, предполагается отказаться от единичной функции включения данных в интервал группирования: данные могут находиться вблизи границ интервала и при изменении числа интервалов оказаться в соседнем интервале; для относительно небольшого количества данных, устранение эффекта изрезанности гистограммы может быть осуществлено сглаживанием данных на нескольких соседних интервалах.
В этом случае целесообразно заменить единичную функцию включения взвешенной функцией, учитывающей возможный вес «ошибочно» попавших в соседние интервалы данных. Физический смысл такой функции может быть охарактеризован нечеткой принадлежностью данных конкретному интервалу группирования.
Наиболее простой, с точки зренияреализации, весовой функцией удобно выбрать ступенчатую функцию.Тогдаматематическая модель гистограммного фильтра может быть представлена в виде: $u _ { j } = \alpha _ { j } \nu _ { j - 1 } + k _ { j } \nu _ { j } + \beta _ { j } \nu _ { j + 1 }$, $\mathbf { a } _ { j } + \boldsymbol { k } _ { j } + \boldsymbol { \beta } _ { j } = 1$, где $\nu _ { j }$ - число данных попавших в $j$ тый интервал группирования, $\{ \mathfrak { a } _ { j }; k _ { j }; \beta _ { j } \}.$ весовые коэффициенты интервалов (параметры сглаживания. В простейшем случае весовые коэффициенты являются постояными величинами и могут быть выражены через один коэффициент $k -$ параметр сглаживания.
Введение весовых коэффициентов для малых объемов данных позволяет перегруппировать эти данные так, чтобы обеспечить меньшую изрезанность гистограммы, увеличив при этом ее слаженность и быструю идентификацию.
Вычисление параметра сглаживания, очевидно, требует некоторой априорной информации о идентифицируемой ПРВ. В работе предполагается, что такая идентификация проводится с помощью критерия согласия хи-квадрат, использование которого также основано на предположении о возможном виде идентифицируемой ПРВ. Таким образом, априорная информациявляется естественным и необходимым элементом построения $\Gamma \Phi$.
Цель работы состоит в реализации гистограммного фильтра с настройкой параметра сглаживания на основе минимизации критерия хи квадрат с учетом априорной информации об идентифицируемой ПРВ.
## II. Определение коэффициента сглаживания гистограммного фильтра
Пусть имеется выборка случайных данных $\{ x _ { i } \}. i = { \overline { { 1, n } } }$ и определено разбиение числовой прямой на т непересекающихся и примыкающих друг к другу интервалов $A _ { j }$, j=1,m равной длины $\Delta _ { x } = X _ { j + 1 } - X _ { j } = R / m. X _ { m + 1 } = x _ { \operatorname* { m a x } } = \operatorname* { m a x } _ { i } x _ { i }. X _ { 1 } = x _ { \operatorname* { m i n } } = \operatorname* { m i n } _ { i } x _ { i }.$ где $X _ { j ^ { - } }$ границы интервалов, $R = x _ { \operatorname* { m a x } } - x _ { \operatorname* { m i n } } = m \Delta _ { { x } ^ { - } }$ размах дназона даных.Заменим обычную индикатрную фунцию, используемую при стандартном способе построение гистограммы,весовой ступенчатой функцией $\mu _ { j } ( x _ { i } )$, $0 \leq \mu _ { j } \leq 1$,c областью определения $\Delta _ { \mathrm { * } } = 3 \Delta _ { \it { x } }$ и которая будет характеризовать принадлежность данных интервалу группирования $A _ { j }$.При этом выбор весовой функции должен осуществляться с учетом условий нормировки:
$$
\left\{ \begin{array}{l} \sum_{t = j - 1}^{j + 1} \mu_{j, t} = 1, \quad j, t = \overline{2, m - 1}, \\\sum_{t}^{(t - m)(m - 3)/(m - 1) + (m - 1)} \mu_{j, t} = 1, \quad j, t = 1, m. \end{array} \tag{1}
$$
Положимвесовые значения $\mu _ { j, t }$ постоянными, не зависящими от индекса номера интервала:
$$
\left\{ \begin{array}{l} \mu_ {j} (x) = \left\{k \text{ДИА} A _ {j}; \alpha = (1 - k) / 2 \text{ДИА} A _ {j - 1} \text{II} A _ {j + 1} \right\}, \quad j = \overline{{2 , m - 1}}, \\\mu_ {j} (x) = \left\{(1 - \alpha) \text{ДИА} A _ {j}; \alpha \text{ДИА} A _ {(j - m) (m - 3) / (m - 1) + (m - 1)} \right\}, \quad j = 1, m, \end{array} \tag{2}
$$
где параметр $k -$ коэффициент сглаживания. Условия нормировки (1) при этом выполняются автоматически. Тогда уравнение, реализующее алгоритм ГФ имеет вид
$$
\left\{ \begin{array}{l} u _ {j} = \alpha v _ {j - 1} + k v _ {j} + \alpha v _ {j + 1}, \quad j = \overline {{2 , m - 1}} \\u _ {j} = (1 - \alpha) v _ {j} + \alpha v _ {(j - m) (m - 3) / (m - 1) + (m - 1)}, \quad j = 1, m, \\\alpha = (1 - k) / 2. \end{array} \right. \tag {3}
$$
Таким образом, задача построения адаптивного ГФ сводится к вычислению коэффициента сглаживания по информации о числе данных и априорной информации об идентифицируемой ПРВ..
Используя в качестве критерия оценки коэффициента сглаживания критерий хи-квадрат и заменив число
$$
v _ {j} \quad_ {\mathrm{B}} \quad_ {\mathrm{K p h T e r p h i n}} \quad \chi^ {2} (v) \quad_ {\mathrm{H a}} \quad_ {\mathrm{q u e c l o}} \quad u _ {j} = \alpha v _ {j - 1} + k v _ {j} + \alpha v _ {j + 1} \quad_ {\mathrm{D I P I}} \quad j = \overline{{2 , m - 1}} \quad_ {\mathrm{H}}
$$
$$
u _ {j} = (1 - \alpha) v _ {j} + \alpha v _ {(j - m) (m - 3) / (m - 1) + (m - 1)} \text{ДЛЯ} j = 1, m, \text{ПОЛУЧИМ}
$$
$$
\chi_ {\mathrm{r}\Phi} ^ {2} (u) = \sum_ {j = 1} ^ {m} \left[ u _ {j} - n p _ {j} \right] ^ {2} / n p _ {j} \rightarrow \min _ {k} \tag{4}
$$
Решение оптимизационной задачи (4) приводит к выражению для коэффициента сглаживания по выборке данных
$$
\begin{array}{l} k _ {\mathrm {B b l 6}} = 1 + 2 \left[ \sum_ {j = 1} ^ {m} U _ {j} ^ {2} / n p _ {j} \right] ^ {- 1} \sum_ {j = 1} ^ {m} \left(v _ {j} - n p _ {j}\right) U _ {j} / n p _ {j} = \tag {5} \\= 1 + 2 \left[ \sum_ {j = 1} ^ {m} U _ {j} ^ {2} / n p _ {j} ^ {1} \right] - \sum_ {j = 1} ^ {m} v _ {j} U _ {j} / n p _ {j}, \\\end{array}
$$
где $U _ { j } = \nu _ { { } _ { j - 1 } } - 2 \nu _ { { } _ { j } } + \nu _ { { } _ { j + 1 } }$ - конечная разность второго порядка для индексов $j = { \overline { { 2, m - 1 } } };$ U j = −vj + Vij−m)(m−3)(m−1)+(m−1) для индексов $\begin{array} { r } { j = 1, m; \sum _ { j = 1 } ^ { m } U _ { j } = 0; p _ { j } } \end{array}$ - гипотетические вероятности.
Статистическая конкретизация формулы (5) приводит к соотношению
$$
k_{0}=1-\frac{1}{1,5+0,5(\Delta_{x}^{2}I_{1}+0,25\Delta_{x}^{4}I_{2})+0,25\Delta_{x}^{4}I_{2}n(m-1)^{-1}}
$$
где = (f / f )2 fdx, 12 = f(f " / f )2 fdx -нфомационыекофициеты пPB, R R
эквивалентные информаци Фишера ерво и второгопорка [7] $f = \operatorname* { l i m } _ { m \to \infty, \Delta _ { x } \to 0 } \left[ p _ { j } / \Delta _ { x } \right].$ гипотетческяаяй
ПРВ, $f^* = \lim_{m\to\infty,\Delta_x\to 0} \left[ \nu_j / n\Delta_x \right] - \int_R f dx = \gamma$ - доверительная вероятность.
Проведем упрощённое обоснование формулы (6), для чего последовательно рассмотрим компоненты, входящие в (5). Совокупность статистическо-экспериментального метода, инженерного подхода и практических представлений приводит к следующим выражениям:
$$
\lim_{\substack{m\to \infty \\\Delta_{x}\to 0}}\sum_{j = 1}^{m}U_{j} / np_{j} = (R / m)\int \limits_{R}(f^{\prime \prime^{*}} / f)dx,
$$
$$
\mathbf{M}\left(\sum_{j=1}^{m}\frac{v_{j}U_{j}}{n p_{j}}\right) = -2(n + m - 1) + \mathbf{M}\left(\sum_{j=2}^{m-1}\frac{(v_{j-1}+v_{j+1})v_{j}}{n p_{j}} + \frac{v_{1}U_{1}}{n p_{1}} + \frac{v_{m}U_{m}}{n p_{m}}\right) = -2(m - 1)\tag{7}
$$
$$
a = \left(\frac{f_{j-1}^{*}}{f_{j}^{*}}\right) = \left(1 - \frac{f^{\prime *}}{f^{*}} \Delta_{x} + \frac{1}{2} \frac{f^{\prime \prime *}}{f^{*}} \Delta_{x}^{2}\right) \quad b = \left(\frac{f_{j+1}^{*}}{f_{j}^{*}}\right) = \left(1 + \frac{f^{\prime *}}{f^{*}} \Delta_{x} + \frac{1}{2} \frac{f^{\prime \prime *}}{f^{*}} \Delta_{x}^{2}\right), \lim_{\substack{m \to \infty \\\Delta_{x} \to 0}} \mathbf{M} \left(\sum_{j=1}^{m} \frac{U_{j}^{2}}{n p_{j}}\right) = \lim_{\substack{m \to \infty \\\Delta_{x} \to 0}} \mathbf{M} \left(\sum_{j=2}^{m-1} \frac{v_{j-1}^{2} + 4 v_{j}^{2} + v_{j+1}^{2}}{n p_{j}}\right) - \\-2\lim_{\substack{m\to \infty \\\Delta_{x}\to 0}}\mathbf{M}\Bigg(\sum_{j = 2}^{m - 1}\frac{2\nu_{j - 1}v_{j} - v_{j - 1}v_{j + 1} + 2\nu_{j}v_{j + 1}}{np_{j}}\Bigg) + \lim_{\substack{m\to \infty \\\Delta_{x}\to 0}}\mathbf{M}\Bigg(\frac{(-v_{1} + v_{2})^{2}}{np_{1}} +\frac{(-v_{m} + v_{m - 1})^{2}}{np_{m}}\Bigg)\approx \\\approx \left[ 4 + M \left(a^{2} + b^{2}\right) \right] (n + m - 1) + \left[ 2 M (a b) - 8 \right] n = \\= 6 (m - 1) + 2 \Delta_{x}^{2} I_{1}^{*} (m - 1) + 0,5 \Delta_{x}^{4} I_{2}^{*} (m - 1) + \Delta_{x}^{4} I_{2}^{*} n
$$
Далее, подставляя выражения (7) и (8) в (5), получим непосредственно формулу (6).
Формула (6) позволяет сделать ряд важных выводов.
Во-первых, при неограниченно возрастающем числе данных $n \to \infty$, очевидно, коэффициент сглаживания должен стремиться к единице, что и следует из формулы (6). В этом случае целесообразность применения ΓФ исчезает. При значении компоненты знаменателя $\delta = 0, 5 ( \Delta _ { x } ^ { 2 } I _ { 1 } ^ { * } + 0, 2 5 \Delta _ { x } ^ { 4 } I _ { 2 } ^ { * } ) + 0, 2 5 \Delta _ { x } ^ { 4 } I _ { 2 } ^ { * } n ( m - 1 ) ^ { - 1 }$ меньше единицы ИЛИ δ 0 коэфициент сглаживания стремиться к 1/3. Такое значение коэффициента сглаживания отвечает случаю сильной изрезанности гистограммы, возможно вследствие неправильно выбранного (относительно большого) значения количества интервалов при относительно небольшом количестве данных. $\Gamma \Phi$,в этом случае, преобразуется в обычный усредняющий фильтр. Таким образом, диапазон изменения значений коэффициента сглаживания лежит в пределах $1 / 3 { \le } k { \le } 1$.
Во-вторых, подставляя значение коэффициента сглаживания (5) в формулу (4) для критерия согласия хи- квадрат получаемвыражение $\chi _ { \mathrm { { r } \Phi } } ^ { 2 } ( u ) = \chi ^ { 2 } ( \nu ) - \left( \sum _ { j = 1 } ^ { m } U _ { j } ^ { \ 2 } / n p _ { j } \right) ^ { - 1 } \left( \sum _ { j = 1 } ^ { m } \nu _ { j } U _ { j } / n p _ { j } \right) ^ { 2 }$, из которого следует сооношение между матемаичекии ожиданиями китерия хиквадрат: $\mathbf { M } \left( \chi _ { \mathrm { r } \Phi } ^ { 2 } \right) = k \mathbf { M } \left( \chi ^ { 2 } \right)$, $\mathbf { M } \left( \chi ^ { 2 } \right) = m - 1.$
Таким образом, применение $\Gamma \Phi$ позволяет уменьшить значение стандартного критерия согласия в $k$ pa3. Соотношение входящих в коэффициент параметров характеризует целесообразность применения и эффективность идентификации $\Gamma \Phi$.Так, при небольших значениях компоненты знаменателя $\delta < 1$,значение критерия хи-квадрат после применения $\boldsymbol { \Phi }$ ильтра практически уменьшается в 3 раза, в противном случае при $n \to \infty ( k \to 1 )$ значение критерия хиквадат стремтсяк стандартному $\mathbf { M } \Big ( \mathbb { X } _ { \mathrm { r Phi } } ^ { 2 } \Big ) \to ( m - 1 )$ и применение $\Gamma \Phi$ нецелесобразно.
Следовательно,эффективность $\Gamma \Phi$ можно оценивать величиной обратной значению коэффициента сглаживания: $\mathfrak { I } _ { \mathrm { r } \Phi } = k ^ { - 1 }$.
В-третьих, предположив высокую апостериорную точность оценки ПРВ, плотность $f ^ { * }$ в информационных коэффициентах формально можно заменить гипотетической и, следовательно, величины $I _ { 1 } ^ { * } { \bf{ \Pi } } _ { \bf{ u } }$ $I _ { 2 } ^ { * }$ будут совпадать с вычисляемыми теоретически информацией Фишера первого и второго порядка $I _ { 1 } ^ { * } = I _ { 1 \gamma }$, $\boldsymbol{ I } _ { 2 } ^ { * } = \boldsymbol{ I } _ { 2 \gamma }$ для диапазона $R ( { \mathrm{ T a } } { \bar{ 0 } } { \mathrm{ { J H H I a } } } \ 1 )$. В этом случае, формула (6) становится полностью определенной. Замечаем, что вычисление коэффициентов $I _ { 1 \gamma }, I _ { 2 \gamma }$ требует существование первой и второй производной ПРВ. Однако, если такой производной не существует, следует воспользоваться инженерными соображениями практической реализации. В частности, для равномерной ПРВ можно принять $f ^ { \prime } = 0, f ^ { \prime \prime } = 0$ $\mathrm{ ~ } _ { \mathrm{ H } }$ следовательно, $I _ { { \scriptscriptstyle 1 } \gamma } = I _ { { \scriptscriptstyle 2 } \gamma } = 0$. Тогда численное значение коэффициента сглаживания будет равно $1 / 3$ $\mathrm{ ~ u ~ } \Gamma \Phi$ преобразуется в обычный усредняющий фильтр, что в случае идентифицируемой равномерной ПРВ вполне очевидно.
В таблице 1 приведены также теоретические значения информационных коэффициентов $I _ { 1 }, I _ { 2 }$, вычисленных по области определения аргумента ПРВ.
Таблица 1: Значения информационных коэффициентов
<table><tr><td></td><td>№1. Гаussовская плOTноctrь: e-2D / √2πD</td></tr><tr><td>I1</td><td>D-1</td></tr><tr><td>I1γ</td><td>Erf[ Erf-1(γ)/√D] - 2e-Erf-1(γ)2/D Erf-1(γ) / D3/2√π</td></tr><tr><td>I2</td><td>D-2</td></tr><tr><td>I2γ</td><td>2Erf[ Erf-1(γ)/√D] - 2e-Erf-1(γ)2/D Erf-1(γ)(D+2Erf-1(γ)2) / D7/2√π</td></tr><tr><td></td><td>№2. Л�имасьдяплOTноctrь: λe-λ|x| / 2</td></tr><tr><td>I1</td><td>λ2</td></tr><tr><td>I1γ</td><td>-(-1+(1-γ)λ)λ2</td></tr><tr><td>I2</td><td>λ4</td></tr><tr><td>I2γ</td><td>-(-1+(1-γ)λ)λ4</td></tr></table>
Продолжение Таблицы 1. Значения информационных коэффициентов
№3. Логистическая плотность: \alpha\operatorname{sech}^2(\alpha x)/2
<table><tr><td>I</td><td>№3. Логistically可以使用αsech2(αx)/2</td></tr><tr><td>I1</td><td>4α2/3</td></tr><tr><td>I1γ</td><td>4/3 α2 tanh[2√3αArcTanh[γ]/π]3</td></tr><tr><td>I2</td><td>16α4/5</td></tr><tr><td>I2γ</td><td>1/5 α4 Sech[2√3αArcTanh[γ]/π]5×
(30sinh[2√3αArcTanh[γ]/π]-5sinh[6√3αArcTanh[γ]/π]+\sinh[10√3αArcTanh[γ]/π])</td></tr><tr><td></td><td>№4. Кoinн пioлстов: s(s2+x2)-1/π</td></tr><tr><td>I1</td><td>0,5s-2</td></tr><tr><td>I1γ</td><td>4arctan[ tan[πγ]/2]-sin[2πγ]/4πs2</td></tr><tr><td>I2</td><td>s-4</td></tr><tr><td>I2γ</td><td>48 arctan[ tan[πγ]/2]+24sin[πγ]+6sin[2πγ]+8sin[3πγ]+3sin[4πγ]/24πs4</td></tr></table>
## II. Соотношения между числом данных, числом интервалов группирования и их шириной
Показатель эффективности ГФ может быть использован в целях нахождения оптимального соотношения между числом данных, числом интервалов групирования и шириной этих интервалов. Зафиксировав некоторое желаемое зачение эфективности фильтра ${ \sf 3 } _ { \mathrm { r } \Phi } ^ { 0 }$ 30, на основании() получим
$$
\Delta_{x}^{2} I_{1} + 0,25\Delta_{x}^{4} I_{2} + 0,5\Delta_{x}^{4} I_{2} n (m - 1)^{-1} = K^{0},
$$
$$
\mathrm{r} _ {\text{Ine}} \Delta_ {x} = R / m, K ^ {0} = \left(\exists_ {\mathrm{r} \phi} ^ {0} - 1\right) ^ {- 1} \left(3 - \exists_ {\mathrm{r} \phi} ^ {0}\right). \exists_ {\mathrm{r} \phi} ^ {0} = k _ {0} ^ {- 1}
$$
В приведенную формулувходят точные теоретические значения информационных коэффициентов по всей области определения аргумента, однако для практических расчетов следует использовать значения с учетом реального диапазона данных $R$ T.e. $I _ { 1 \gamma } ^ { \mathrm { ~ \bf ~ u ~ } } I _ { 2 \gamma }$.
Уравнения (9) нелинейное, требующие численных методов решения в общем случае.
Анализ уравнения (9) показываетсложную взаимозависимость параметров идентифицируемой ПРВ и ГФ. Это, в частности, объясняет большое количество работ, посвященных тематике взимосвязи этих параметров и рассматривающих проблему их выбора с тех или иных позиций.В этом смысле данная работа расширят подход [9,10], учитывая информацию Фишера первого и второго порядка относительно идентифицируемой ПРВ.
В некоторых частных случаях, с целью получения простых аналитических выражений взаимосвязи параметров ПРВ и ГФ, уравнение (9) возможно упростить.
Во-первых, если выполняется соотношение между информационными коэффициентами $I _ { 2 } = c I _ { 1 } ^ { 2 }$, $c =$ сопst и число интервалов группирования значительно больше единицы, то обозначив $x = \Delta _ { x } ^ { 2 } I _ { 1 }$, уравнения (9) можно записать в виде
$$
a (n) x ^ {5 / 2} + b x ^ {2} + x - K ^ {0} = 0, b = 0, 2 5 c, a (n) = 2 b \left(R \sqrt {I _ {1}}\right) ^ {- 1} n \tag {10}
$$
Уравнение (10) компактно и позволяет получать семейства зависимостей связывающих параметры идентифицируемой ПРВ и ГФ.
Во-вторых, анализируя вклад компонент знаменателя (6) в коэффициент сглаживания замечаем, что с увеличением числа данных возрастает влияние компоненты, содержащей параметр п. Тогда уравнение (9) можем преобразовать к виду
$$
\frac {n}{m ^ {4} (m - 1)} = \frac {2 K ^ {0}}{R ^ {4} I _ {2}} \tag {11}
$$
Для случая $m > > 1$ возможно приближенное аналитическое решение нелинейного уравнения (11): $m = \sqrt [ 5 ] { n R ^ { 4 } I _ { 2 } / 2 K ^ { 0 } }$.Последняя формула близка к выражениям вида $m \sim n ^ { 0, 2 }$, приведенным в [1,8] с коэффициентом пропорциональности зависящим от параметров ПРВ и априорных установок $\Gamma \Phi$ по его эффективности ${ \sf 3 } _ { \mathrm { r } \Phi } ^ { 0 }$
В-третьих, перераспределение части данных между соседними интервалами, не только уменьшает изрезанность гистограммы, но и способствует ослаблению требований к выбору числа интервалов групирования. Фикеируя еторую нижною граниу значения эфетивноти ГФ( $9 _ { \mathrm { r } \Phi } ^ { 0 } \cdot$ можем определить значение чиела интервалов группирования по формулам (11) из условия $m ^ { 4 } \left( m - 1 \right) \geq 0, 5 n R ^ { 4 } I _ { 2 } / K ^ { 0 }.$
## IV. Рекомендации по реализации гистограммного фильтра
Полученные теоретические результаты показывают целесообразность применения $\Gamma \Phi$ с целью эффективной и быстрой (на малых объемах данных) идентификации изменяющихся законов распределения в описательной статистике, при обработке гистограмм изображений. Программная реализация Гф легко встраивается в существующие открытые алгоритмы построения гистограмм, например, в функции his, histit платформы Мatlab. Структура алгоритма идентификации (распознавания) ПРВ следующая.
1. Получение выборки данных, объемом п, определение размаха выборки R.
2. На оснований предположений о идентифицируемой ПРВ, вычисление информационных коэффициентов $I _ { 1 \gamma }$ $I _ { 2 \gamma }$
3. На основании выбранного числа интервалов группирования данных, размаха выборки, объема данных, информационных коэффициентов вычисляется значение коэффициента сглаживания (6).
4. Применение $\Gamma \Phi$ (3).
5. Вычисление критерия согласия хи-квадрат. На основании заданного уровня значимости принятие решения о идентификации.
Заметим, процедуру идентификации ПРВ можно сделать многоканальной, где каждый канал будет ориентирован на определенный заранее возможный вид ПРВ. Принятие решения о идентификации в этом случае может быть реализовано различными методами, например, простым или взвешенным голосованием.
## V. Моделирование гистограммного фильтра
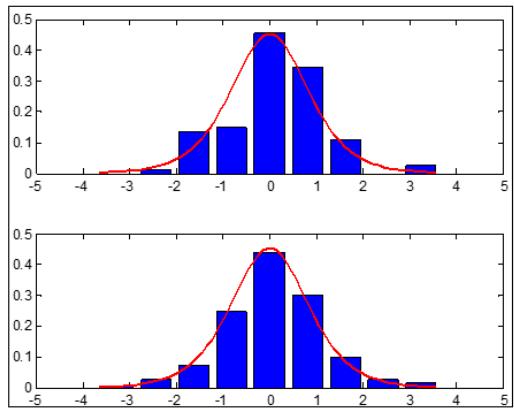
Ha puc.1 $n = 1 0 0, m = 9$, количество серий экспериментов 100) приведены примеры работы $\Gamma \Phi$ длЯ ПРВ: нормальной(рис.1,а, $k _ { _ \mathrm { B b I } 6 } = 0. 6 4$, $\Theta _ { \mathrm { B b I } 6 } = 1, 5 6$, логистической (ис.1,6,, $k _ { _ \mathrm { B b I 6 } } = 0. 7 4$, $\Theta _ { \mathrm { B b I } 6 } = 1, 3 5$ ), экспоненциальной (рис.1,в, $k _ { _ \mathrm { B b I 6 } } = 0. 5 3$, $\Theta _ { \mathrm { B b I } 6 } = 1, 8 9$ ), равномерной (рис.1,г, $k _ { _ \mathrm { B b I } 6 } = 0, 3 6$, $\Theta _ { _ \mathrm { B b I 6 } } = 2, 7 8$ ). На рис.1 верхняя часть соответствует обычной гистограмме, нижняя – результат обработки ГФ. Во всех
привдехн и учая се $\chi _ { \mathrm { r \Phi } } ^ { 2 } < \chi _ { \mathrm { \scriptscriptstyle { k p } } } ^ { 2 } \le \chi ^ { 2 }$, гле $\chi _ { \mathrm { \scriptscriptstyle K p } } ^ { 2 }$ - критичское ссия критерия согласия при заданном уровне значимости (0,05). Результаты моделирования, наглядно подтверждают идею применения ГФ. Эффективность применения ГФ на отмеченных плотностях указывает на существенное его превосходство перед стандартной гистограммной оценкой.
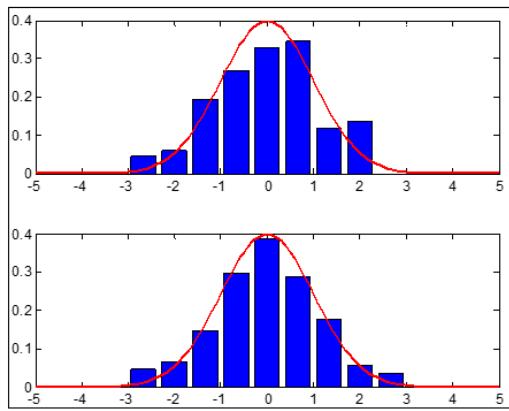
a)
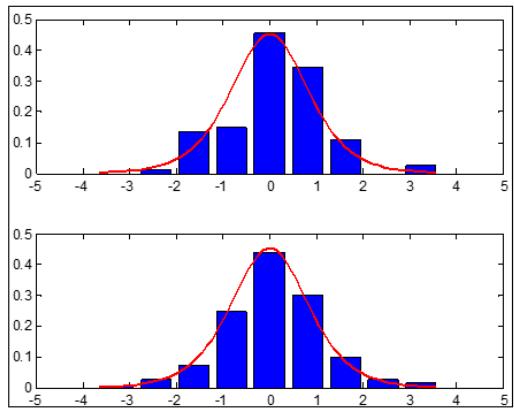
6)
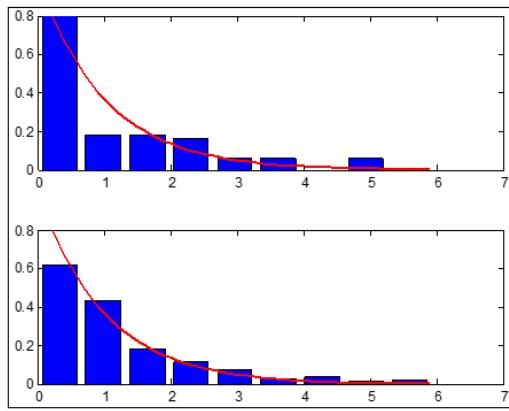
B)
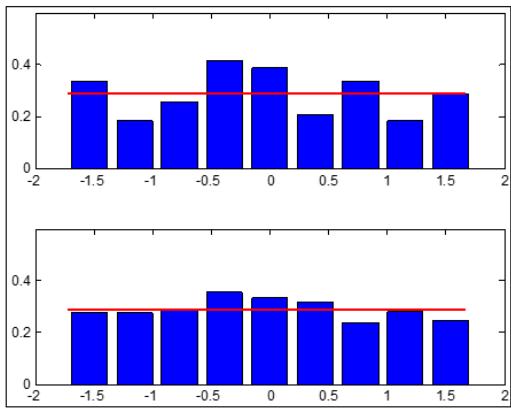
Γ) Рис.1: Результаты работы ГФ
В табл.1 (количество серий экспериментов 100) содержаться некоторые результаты моделирования работы ГФ (4) в сопоставлении с теоретическими результатами, полученными на основе формулы (6) для трех ПРВ: нормальной, логистической, лапласовской. На рис.2 приведены зависимости коэффициента сглаживания (6) от количества интервалов группирования для двух ПРВ: нормальной (кривая 1, $n = 1 0 0$; кривая 2, $n = 5 0 0$ )H лапласовской (кривая 3, $n = 1 0 0$; кривая 4, $n = 5 0 0$ ). Численные (таблица 2) и графические результаты (рис.2) позволяют сделать вывод о том,что значение коэффициента сглаживания нелинейно уменьшается с уменьшением объема данных. Это объясняется тем, что при уменьшающемся объёме данных увеличивается изрезанность обычной гистограммной оценки ПРВ и, следовательно, требуется ее большая сглаженность, стремящаяся к равномерному (усредняющему) сглаживанию ( $k \to 1 / 3$ ) при одном и том же числе интервалов группирования.
На рис.3 (количество серий экспериментов 100) на основе формулы (9) (кривые 1.1-1.3), приведены зависимости меду числом данных и числом интервалов их группирования для двух плотностей: гауссовской – рисза и логистической – рис.36 для различных значений коэфициента эфективности: $\mathfrak { G } _ { \mathtt { r } \Phi } ^ { 0 } = 1, 5$ (k0 = 0,(6))- кривая 1.1, $9 _ { \mathrm { r } \Phi } ^ { 0 } = 1, 3$ $k ^ { 0 } = 0, 7 7$ ) – кривая 1.2, $9 _ { \mathrm { r } \Phi } ^ { 0 } = 1, 1$ ( $k ^ { 0 } = 0, 9 1$ - кривая 1.3. Hа теx же рисунках приведены для сопоставления стандартно используемые формулы Старджеса $m = 1 + \log _ { _ { 2 } } n$ (кривая 2) и формулы, приведенной в [1,8] $m = C ( E _ { x } ) n ^ { 0, 4 }$ (кривая 3), где $C ( E _ { x } ) = \left( E _ { x } + 4, 5 \right) / 6, E _ { x } -$ $E _ { x } -$ коэфициент эксцесса ПРВ.
Таблица 2: Коэффициенты сглаживания и эффективность ГФ, $n = 100$ \begin{table} \begin{tabular}{I^ccI^ccI^ccI^ccI^ccI^cc|} \hline \multirow{2}{*}{№} & \multirow{2}{*}{$m$} & \multicolumn{3}{c|}{Нормальная ПРВ, $A(f) = 1,73$} & \multicolumn{3}{c|}{Логистическая ПРВ, $A(f) = 2,14$} & \multicolumn{3}{c|}{Лапласовская ПРВ, $A(f) = 0,99$} \\ \cline{3-5} \cline{6-8} \cline{9-11} & & $k_{\text{выб}}$ & $k_0$ & $\mathcal{E}_{\text{гф}}$ & $k_{\text{выб}}$ & $k_0$ & $\mathcal{E}_{\text{гф}}$ & $k_{\text{выб}}$ & $k_0$ & $\mathcal{E}_{\text{гф}}$ \\ \hline 1 & 5 & 0,8 & 0,96 & 1,04 & 0,96 & 0,98 & 1,02 & 0,98 & 0,99 & 1,01 \\ \hline 2 & 7 & 0,81 & 0,81 & 1,23 & 0,90 & 0,92 & 1,09 & 0,94 & 0,97 & 1,03 \\ \hline 3 & 9 & 0,66 & 0,61 & 1,64 & 0,75 & 0,77 & 1,30 & 0,86 & 0,91 & 1,10 \\ \hline \end{tabular} \end{table}
<table> <tr> <td rowspan="2">№</td> <td rowspan="2">m</td> <td colspan="3">Нормальная ПРВ, A(f) = 1,73</td> <td colspan="3">Логистическая ПРВ, A(f) = 2,14</td> <td colspan="3">Лапласовская ПРВ, A(f) = 0,99</td> </tr> <tr> <td>k_выб</td> <td>k_0</td> <td>Э_гф</td> <td>k_выб</td> <td>k_0</td> <td>Э_гф</td> <td>k_выб</td> <td>k_0</td> <td>Э_гф</td> </tr> <tr> <td>1</td> <td>5</td> <td>0,8</td> <td>0,96</td> <td>1,04</td> <td>0,96</td> <td>0,98</td> <td>1,02</td> <td>0,98</td> <td>0,99</td> <td>1,01</td> </tr> <tr> <td>2</td> <td>7</td> <td>0,81</td> <td>0,81</td> <td>1,23</td> <td>0,90</td> <td>0,92</td> <td>1,09</td> <td>0,94</td> <td>0,97</td> <td>1,03</td> </tr> <tr> <td>3</td> <td>9</td> <td>0,66</td> <td>0,61</td> <td>1,64</td> <td>0,75</td> <td>0,77</td> <td>1,30</td> <td>0,86</td> <td>0,91</td> <td>1,10</td> </tr> </table>
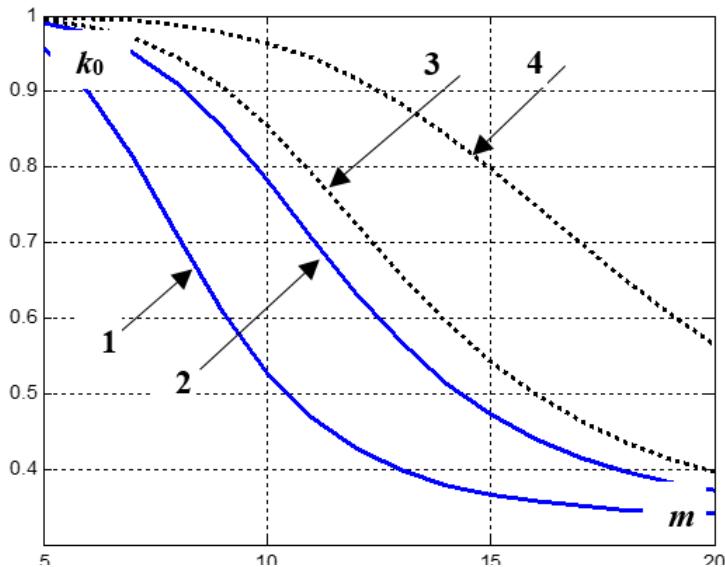
Рис.2: Коэффициенты сглаживания ГФ
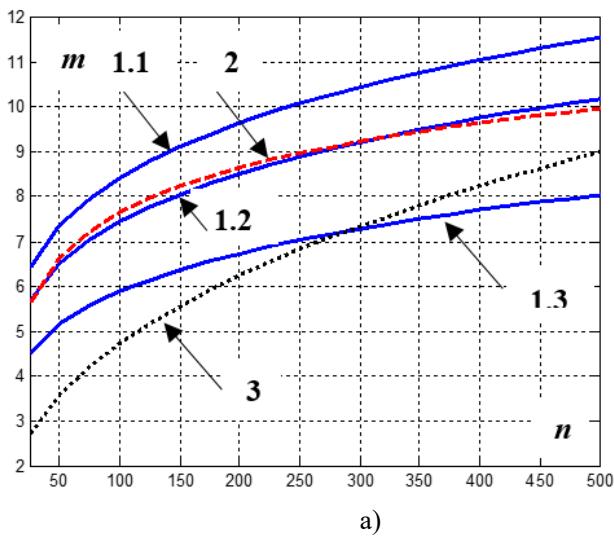
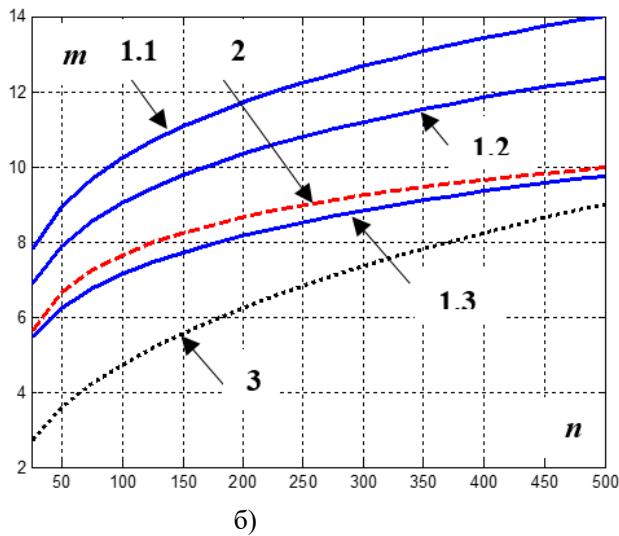
Рис.3: Зависимость числа интервалов группирования от объема данных
## VI. Выводы
Рассмотренный в статье ГФ (3) с настройкой параметра сглаживания может быть эффективно применен в задачах идентификации (распознавания) ПРВ для малых объемов данных с учетом имеющейся в наличии априорной информации о предполагаемой ПРВ.
Установлено соотношение между математическими ожиданиями согласия критерия хи-квадрат при стандартном подходе построения гистограммной оценки и с использованием ГФ. Такое соотношение определяется коэффициентом слаживания (5), (6). Численное значение коэффициента сглаживания зависит от параметров: объема данных, числа интервалов группирования, информационных характеристик ПРВ (таблица 1). Зависимость коэффициента сглаживания от указанных параметров позволяет определить взаимосвязь между количеством
интервалов групирования данных и их объемом. Эта зависимость нелинейная, не имеющая аналитического решения.
Гистограммный фильтр является простым для реализации инструментом, который легко может быть встроен в любой открытый алгоритм идентификации (распознавания) ПРВ.
## Список литературы
1. Орлов Ю,Н, Оптимальное разбиение гистограммы для оценивания выборочной плотности функции распределения нестационарного временного ряда, Препринты ИПМ им, М,В,Келдыша, 2013, № 14, 26с, URL: http://library,keldysh,ru/preprint,asp?id. 2013-14.
2. Chong Gu, Yongho Jeon and Yi Lin, Nonparametric density estimation in high-dimensions, Statistica Sinica 23 (2013), 1131-1153.
3. Devroye L. and Gyorfi L. Nonparametric Density Estimation: The L1 View. John Wiley Sons, New York. 1985/
4. Solomon C,, Breckon T,P, Fundamentals of Digital Image Processing: A Practical Approach with Examples in Matlab, - Wiley-Blackwell, 2010, ISBN 978-0470844731, DOI:10.1002/9780470689776.
5. Gonzalez Rafael, Digital image processng, New York, NY: Pearson, 2018,ISBN 978-0-13-335672- 4, OCLC 966609831.
6. Овсянников А.В., Козел В.М. Фильтрация гистограммной оценки плотности вероятности на основе нечеткой принадлежности данных интервалу группирования // Научный журнал «Доклады БГУИР Том 19, № 4 (2021). C.13-21. https://doklady.bsuir.by/jour/article/view/3103.
7. Овсянников А.В. Статистические неравенства в сверхрегулярных статистических экспериментах теории оценивания / ВестінацыянальнайакадэмінавукБеларусі. №2, 2009. Сер фіз-мат. навук. С.106-110.
8. Новицкий П.В. Зограф И.А. Оценка погрешностей результатов наблюдений. – Л.: Энергоатомиздат. Ленингр. отд-ние, 1991. – 304с.
9. Freedman D. and Diaconis P. On the histogram as a density estimatorr: L2 theory // Zeitschrift fur Wahrscheinlichkeitstheorie verw. Gebiete. 1981. Vol. 57. Pp. 453-476.
10. Scott D.W. On optimal and data-based histograms // Biometrika. 1979. V.66. P. 605-610.
Generating HTML Viewer...
References
11 Cites in Article
(null). Список литературы.
Ю Орлов,Н (2013). Оптимальное разбиение гистограммы для оценивания выборочной плотности функции распределения нестационарного временного ряда, Препринты ИПМ им.
Chong Gu,Yongho Jeon,Yi Lin (2013). Nonparametric density estimation in high-dimensions.
L Devroye,L Gyorfi (1985). Nonparametric Density Estimation: The L1 View.
Chris Solomon,Toby Breckon (2010). Fundamentals of Digital Image Processing.
Gonzalez Rafael (2018). Digital image processing.
Андрей Овсянников,Олег Барашко (2021). Гистограммный фильтр на основе нечеткой принадлежности данных интервалу группирования.
А Овсянников (2009). Статистические неравенства в сверхрегулярных статистических экспериментах теории оценивания // ВестiнацыянальнайакадэмiiнавукБеларусi.
П Новицкий,И Зограф,Оценка (1991). погрешностей результатов наблюдений.
D Freedman,P Diaconis (1981). On the histogram as a density estimatorr: L2 theory // Zeitschrift fur Wahrscheinlichkeitstheorie verw.
David Scott (1979). On optimal and data-based histograms.
No ethics committee approval was required for this article type.
Data Availability
Not applicable for this article.
How to Cite This Article
Ausiannikau Andrei V. 2026. \u201cHistogram Filter with Adjustment of the Smoothing Parameter Based on The Minimization of the Chi-Square Test\u201d. Global Journal of Research in Engineering - J: General Engineering GJRE-J Volume 22 (GJRE Volume 22 Issue J3).
Explore published articles in an immersive Augmented Reality environment. Our platform converts research papers into interactive 3D books, allowing readers to view and interact with content using AR and VR compatible devices.
Your published article is automatically converted into a realistic 3D book. Flip through pages and read research papers in a more engaging and interactive format.
Our website is actively being updated, and changes may occur frequently. Please clear your browser cache if needed. For feedback or error reporting, please email [email protected]
Thank you for connecting with us. We will respond to you shortly.