## I. INTRODUCTION
The current data-driven environment subjects the stream processing platform to extreme pressure to accommodate absurdly unpredictable workloads, erratic event arrival rates, and ever-changing resource limits. Conventional systems such as Apache Flink, Spark Streaming, and Kafka Streams are generally designed on a specific configuration that crumbles whenever dynamic circumstances alter. These rigid approaches trigger significant performance crashes during workload spikes while leaving expensive resources sitting idle during quieter periods, creating wasteful inefficiencies that hammer both operational budgets and service quality. The core limitation stems from predetermined optimization settings that simply cannot adapt to the inherently chaotic nature of real-time data streams, as explored in research examining reinforcement learning applications for control problems in dynamic environments [1]. Reinforcement Learning offers a breakthrough solution by introducing adaptability through smart agents that perpetually learn from system performance metrics. These agents fine-tune crucial parameters like task scheduling, resource allocation, checkpoint frequency, and load balancing on the fly. The methodology aligns perfectly with principles of continuous system adaptation, where RL agents interact with the environment, observe performance metrics, make parameter adjustments, and receive rewards based on optimization goals. This approach mirrors advancements in large language model applications for stream processing, where systems adapt processing strategies based on continuous feedback loops [2]. Integrating RL with stream processing lets systems respond dynamically to changing conditions across diverse scenarios. When processing financial transaction streams, an RL agent might automatically adjust parallelism levels during peak and off-peak hours, maintaining consistent processing latencies despite massive fluctuations in event rates. Similarly, adaptive checkpoint intervals managed by RL agents can dramatically reduce storage overhead while maintaining recovery time objectives, creating more resilient systems. These approaches represent practical implementations of theoretical frameworks described in research on neuro-adaptive learning algorithms, where systems evolve strategies based on environmental
feedback [1]. As data volumes explode and workload patterns become increasingly unpredictable, adaptive stream processing systems represent not merely an advantage but an absolute necessity for organizations processing real-time data at scale. The self-optimizing nature of these systems aligns with broader trends in autonomous computing, where intelligent agents continuously refine system configurations to maximize performance metrics. This evolution follows the trajectory outlined in research examining foundation models for stream processing, where adaptivity emerges as a critical capability for handling the complexity and variability inherent in real-time data processing workloads [2].
Figure 1 illustrates an example architecture for integrating reinforcement learning with stream processing systems, highlighting the key components and their interactions.
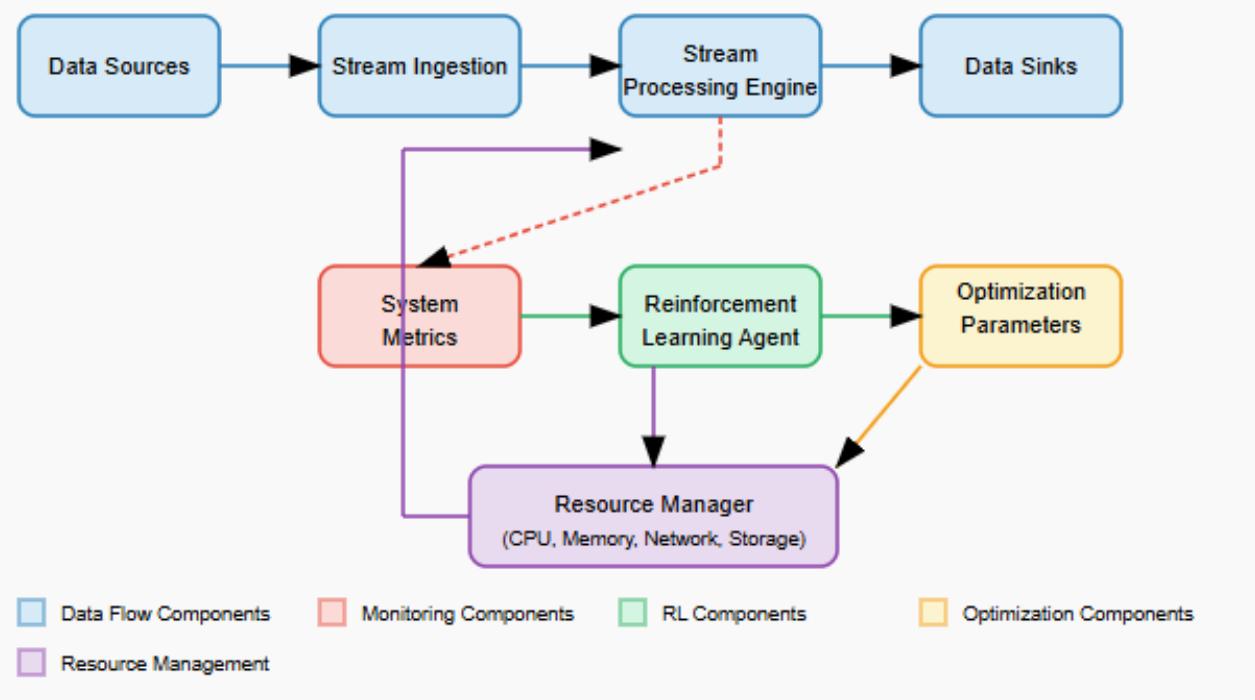 Fig. 2: Adaptive Stream Processing Architecture with Reinforcement Learning [1, 2]
The architecture demonstrates how RL seamlessly integrates with traditional stream processing components to create an adaptive system. The upper flow represents the standard streaming data pipeline: data sources (such as IoT devices, financial transactions, or user activity) feed into stream ingestion components (like Apache Kafka or Amazon Kinesis), which then flow to the stream processing engine (such as Apache Flink or Spark Streaming) for transformation and analysis before reaching data sinks (databases, dashboards, or alerting systems).
The lower portion of the diagram illustrates the adaptive reinforcement learning control loop that enables self-optimization. The stream processing engine continuously emits system metrics (throughput, latency, queue depths, resource utilization) that are monitored and fed as state information to the RL agent. The agent processes these metrics using its learned policy to determine optimal configuration changes, outputting optimization parameters such as parallelism levels, buffer sizes, and checkpoint intervals. These parameters are applied through the resource manager, which dynamically adjusts CPU, memory, network, and storage allocations to maintain optimal performance as workload characteristics change.
This closed-loop system creates a continuous feedback mechanism where the RL agent learns from the consequences of its actions, constantly refining its optimization strategy based on observed performance. Unlike traditional static configurations, this architecture adapts in real-time to changing conditions, automatically balancing competing objectives such as minimizing latency, maximizing throughput, and optimizing resource utilization without manual intervention.
## II. WHY ADAPTIVITY IS CRITICAL IN STREAM PROCESSING
Stream processing workloads display extreme variability that undermines traditional static configuration models. Event rates are often sharply increasing in critical situations like e-commerce flash sales, network service failure, or security breaches. The inflexibilities of the static configurations set up organizations with an untenable decision: under-resource the systems with a high likelihood of recovering the losses through cost inefficiencies during the regular season, or over-provision the systems and waste resources to meet the potential high demand levels with the risk of system straggling and service collapse. Such an inherently contradictory nature can be attributed to the irreconcilable conflict of fixed system parameters and the dynamism of real-time data flows. Research on continuous eventual check pointing highlights this challenge, demonstrating that adaptive check pointing mechanisms significantly outperform static approaches by intelligently adjusting to changing stream characteristics, thereby reducing overhead while maintaining fault tolerance [3].
"Stream processing systems face a fundamental challenge: optimizing for both performance and cost across widely varying workloads. The static configuration approach resembles navigating changing traffic conditions with a fixed route and speed-it simply fails when conditions change rapidly. This perspective aligns with findings on state management in Apache Flink that emphasize the critical importance of adaptive mechanisms for handling state transformations and ensuring consistency across distributed stream processing environments. This research demonstrates that fixed approaches to state management struggle to maintain performance under variable workloads, whereas adaptive techniques can significantly improve system stability [4].
Adaptive systems address these challenges by implementing continuous parameter adjustment mechanisms that maintain operational efficiency and system resilience. As stream processing deployments scale to enterprise levels, this adaptivity becomes increasingly crucial. The continuous, eventual check pointing approach exemplifies how adaptive systems can significantly reduce runtime overhead compared to traditional periodic check pointing, with experiments showing overhead reductions of up to $73\%$ in certain workload scenarios [3]. Specifically, Sebepou and Magoutis demonstrated this improvement through experiments on a multi-operator dataflow using real-world financial data streams, where their adaptive CEC approach dynamically adjusted checkpoint intervals based on data characteristics and processing state, dramatically outperforming static periodic check pointing methods [3]. Similarly, the state management framework implemented in Apache Flink demonstrates how adaptive approaches to handling distributed state enable systems to maintain consistent processing semantics despite workload fluctuations and system failures. This implementation supports exactly-once processing guarantees while adaptively managing state size and distribution based on current processing requirements [4].
Table 1: Efficiency Comparison between Static and Adaptive Stream Processing [3, 4]
<table><tr><td>Approach</td><td>Performance During Load Spikes</td><td>Resource Utilization</td><td>Checkpoint Overhead</td><td>Processing Guarantees</td></tr><tr><td>Static Configuration</td><td>Poor</td><td>Inefficient</td><td>High</td><td>Inconsistent under fluctuations</td></tr><tr><td>Adaptive (RL-based)</td><td>Good</td><td>Efficient</td><td>Significantly Reduced</td><td>Maintains exactly-once [4]</td></tr></table>
## III. REINFORCEMENT LEARNING FUNDAMENTALS FOR STREAM PROCESSING
Reinforcement Learning provides a natural framework for building adaptive stream processing systems by enabling continuous optimization through interaction with the environment. At its core, RL establishes a mathematical foundation for sequential decision-making under uncertainty, making it particularly suitable for the dynamic nature of stream processing workloads. Research on cloud computing performance demonstrates that resource provisioning decisions similar to those needed in stream processing must account for significant variability in system startup times and performance characteristics, highlighting the need for adaptive approaches rather than static configurations [5].
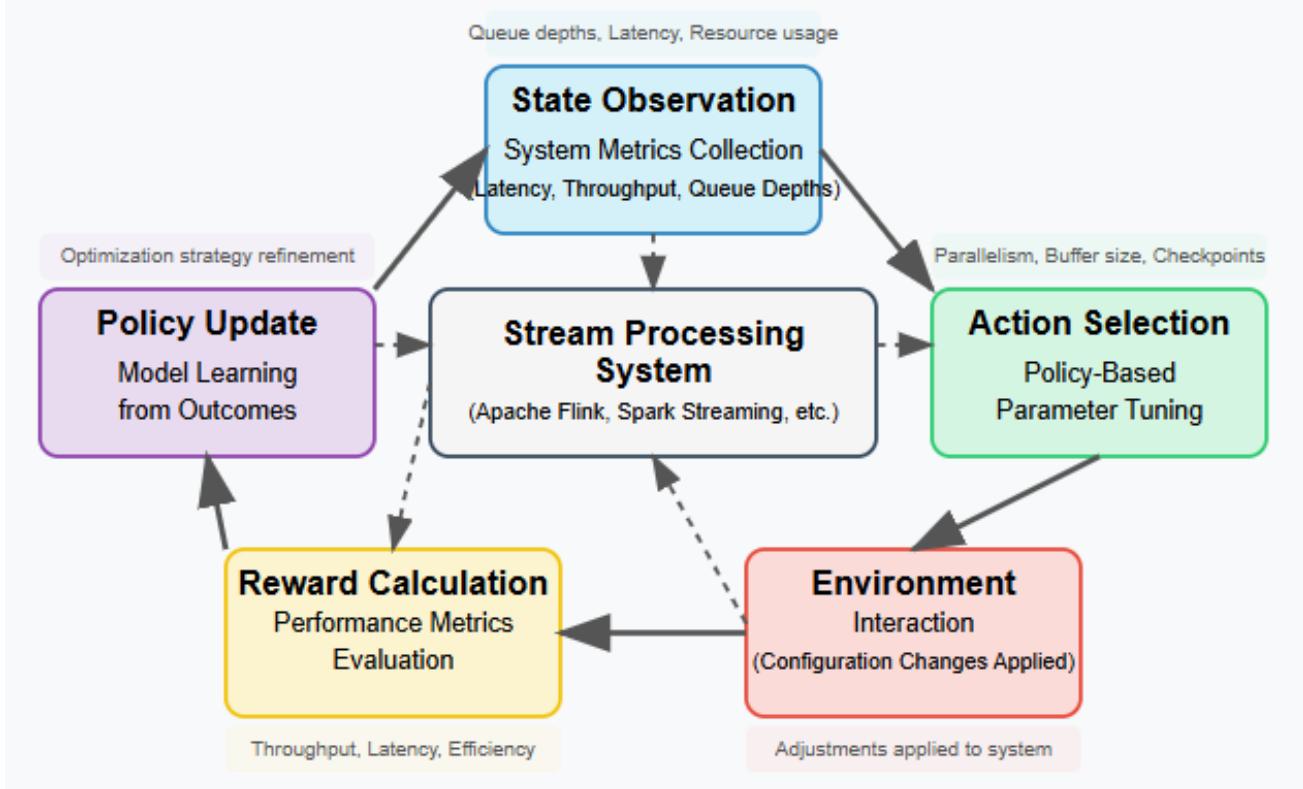 Fig. 3: RL Decision Cycle for Adaptive Stream Processing [5, 6]
The RL paradigm encompasses several key components that align perfectly with stream processing optimization requirements. The agent functions as the decision-making entity that learns to optimize system parameters through experience. The environment comprises the stream processing framework and its workload characteristics, creating the context within which optimization occurs. Observable metrics such as queue depths, processing latency, and resource utilization form the state representation that informs decision-making. Parameter adjustments, including resource scaling, data re-partitioning, and scheduling priority modifications, constitute the action space available to the agent. A feedback signal reflecting system performance metrics like throughput, latency, and resource efficiency serves as the reward mechanism that guides the learning process. These components form a cohesive framework that enables sophisticated adaptation to changing conditions, as demonstrated in research implementing RL-based autoscaling for stream processing systems, where reinforcement learning approaches have shown superior performance in managing resources under variable workloads [6].
Unlike supervised learning approaches that require labeled examples of optimal configurations—which rarely exist in complex stream processing environments—RL enables systems to learn optimal strategies through trial and error interaction. This approach suits streaming environments perfectly, where optimal configurations depend on dynamic, difficult-to-predict factors that evolve. Moreover, the performance information of stream processing systems is frequently delayed, i.e., the effects of configuration changes may not be short-term, and this phenomenon is explicitly accounted for in RL algorithms. Moreover, these systems generally need to trade off several competing goals like minimizing latency, maximizing throughput, and optimizing resource use- a multi-objective optimization problem, and RL is well-suited to solve such problems with appropriately-designed reward functions. The studies so far on autoscaling stream processing systems through reinforcement learning show that reinforcement learning based methods can easily balance these conflicting objectives and dynamically respond to changes to the workload pattern, with lower latency and better resource utilization than when using traditional threshold-based methods [5][6].
Table 2: Reinforcement Learning Components Applied to Stream Processing [5, 6]
<table><tr><td>RL Component</td><td>Stream Processing Application</td><td>Benefit</td></tr><tr><td>Agent</td><td>System parameter optimization</td><td>Learns from experience</td></tr><tr><td>Environment</td><td>Processing framework & workload</td><td>Context for optimization</td></tr><tr><td>State</td><td>Queue depths, latency, resource usage</td><td>Performance metrics</td></tr><tr><td>Action</td><td>Resource scaling, scheduling changes</td><td>Parameter adjustments</td></tr><tr><td>Reward</td><td>Throughput, latency, efficiency</td><td>Optimization guidance</td></tr></table>
## IV. APPLICATIONS OF RL IN STREAM PROCESSING
### a) Dynamic Resource Allocation
Among the most valuable applications of reinforcement learning in stream processing stands dynamic resource allocation. Conventional auto-scaling mechanisms rely on basic threshold-based rules, frequently causing resource oscillation and wasteful utilization patterns. These traditional approaches deliver subpar performance because they merely react to past conditions rather than forecasting future states, while failing to grasp intricate relationships between workload characteristics and resource needs. Research examining resource management through deep reinforcement learning reveals that RL techniques substantially outshine conventional heuristic methods by crafting sophisticated allocation policies adapting to shifting conditions, demonstrated in experiments where Deep RM eclipsed traditional strategies in cluster management scenarios [7].
RL approaches develop nuanced policies anticipating workload shifts and proactively adjusting resources. An RL agent might detect specific patterns in incoming data, typically preceding processing bottlenecks, then allocate extra resources before these bottlenecks materialize. This predictive edge represents a fundamental advantage compared to reactive methods, especially within environments featuring recurring patterns or foreseeable fluctuations. Research into adaptive resource management for stream processing demonstrates reinforcement learning approaches effectively juggle competing priorities, including throughput maximization, latency reduction, and cost control through persistent adaptation to workload dynamics [8].
### b) Task Scheduling Optimization
Stream processing frameworks perpetually face decisions about task prioritization when resources grow scarce. Static scheduling policies falter when confronting evolving workload characteristics, producing poor resource utilization alongside increased processing delays. Scheduling complexity intensifies within distributed stream processing environments where numerous competing tasks with varied characteristics and importance levels require coordination across systems.
RL agents master scheduling policies by monitoring relationships between scheduling choices and system performance outcomes. These agents prioritize tasks considering factors such as current backlog depth across processing stages, anticipated processing duration for varied event types, significance levels of different data streams, and available resources. Studies exploring deep reinforcement learning for resource management demonstrate that RL approaches effectively develop sophisticated scheduling policies surpassing manually-tuned heuristics through experiential learning and adaptation to shifting workload patterns [7].
### c) Adaptive Check pointing
Check pointing delivers essential fault tolerance within stream processing while introducing performance overhead. Optimal check pointing frequency depends on multiple variables, including failure likelihood, recovery duration, and checkpoint creation costs. Static check pointing strategies establish rigid intervals based on worst-case assumptions, generating excessive overhead during routine operation.
RL agents optimize checkpoint frequency by striking balanced tradeoffs between overhead burdens and recovery times. Such agents might escalate checkpoint frequency during periods marked by system instability or when handling particularly valuable data streams. Research into QoS-aware adaptive scaling for stream processing confirms reinforcement learning approaches effectively manage reliability mechanisms, including check pointing, through dynamic parameter adjustments based on current system conditions and performance requirements [8].
### d) Intelligent Load Balancing
Unbalanced load distribution across processing nodes breeds "straggler" problems where a handful of overloaded nodes bottleneck entire processing pipelines. This challenge grows particularly acute within large-scale deployments where workload characteristics vary dramatically across data partitions and processing phases.
RL-based load balancers predict which data partitions might trigger processing hotspots, dynamically redistribute partitions across nodes, and factor data locality alongside transfer costs when making redistribution decisions. Research focused on reinforcement learning for cluster management shows
RL agents develop effective load balancing policies by considering multifaceted factors, including resource heterogeneity, data locality, and processing dependencies [7]. Likewise, studies examining QoS-aware resource management for stream processing reveal adaptive load balancing strategies guided through reinforcement learning markedly enhance system performance by alleviating bottlenecks and promoting more uniform resource utilization throughout distributed processing environments [8].
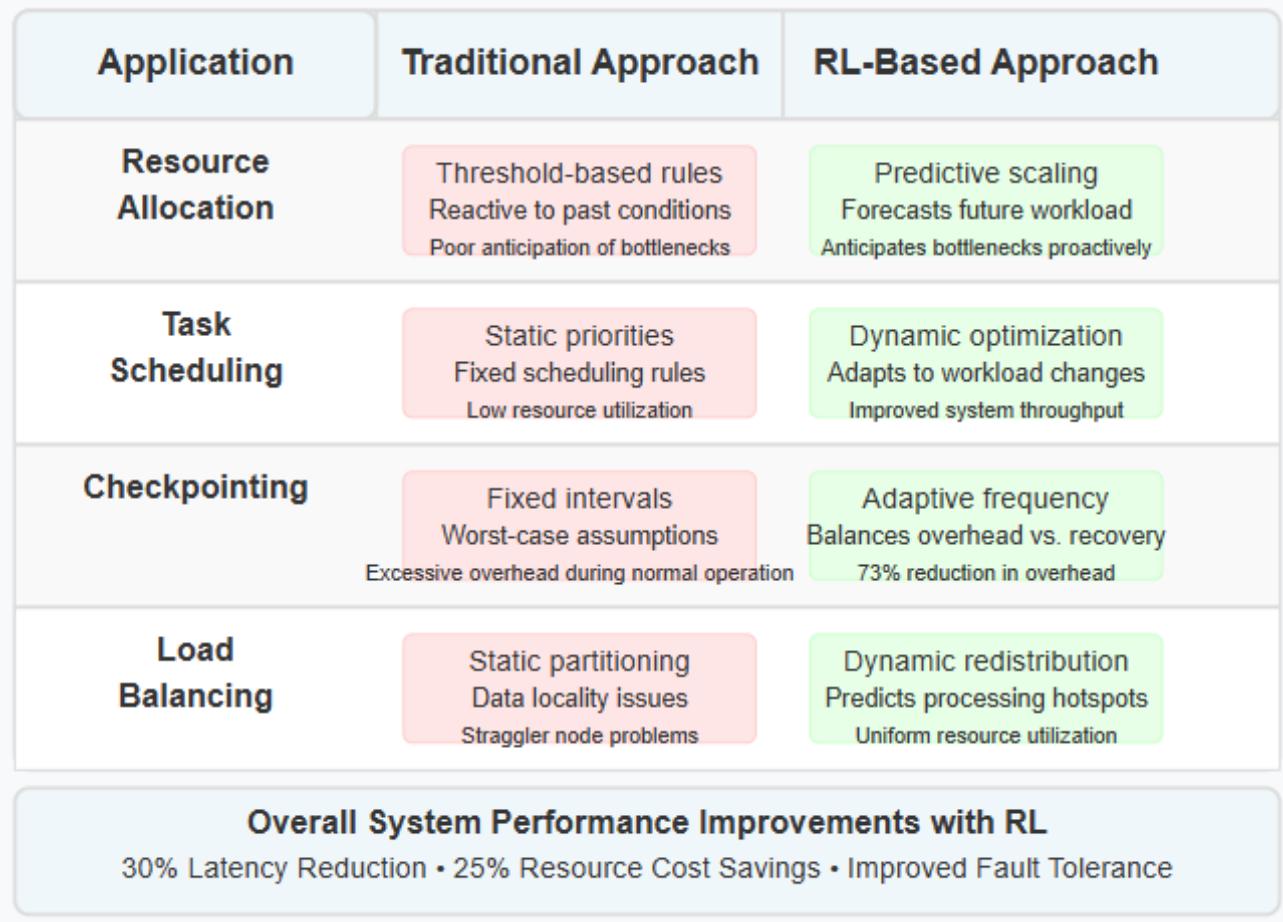 Fig. 4: Reinforcement Learning Applications in Stream Processing Systems [7, 8]
## V. CASE STUDY: ZILLOW'S REAL-TIME PROPERTY DATA PIPELINE OPTIMIZATION
To demonstrate the practical application of RL-based stream processing optimization, this case study examines a real-world implementation at Zillow Group, providing empirical evidence that validates the theoretical foundations discussed previously.
### a) Background and Challenge
Zillow's real-time property data pipeline processes millions of property updates daily from multiple sources including MLS feeds, partner APIs, and user-generated content. The system faced several key challenges that made it an ideal candidate for reinforcement learning optimization. The ingestion rates exhibited extreme variability, with daily patterns showing baseline throughput of approximately 5,000 events per second during normal operations, but spiking to over 200,000 events per second during nationwide MLS listing refreshes. This variability created substantial difficulties for static configuration approaches. The data processing requirements were equally diverse, encompassing computationally intensive image processing for property photos, natural language processing for listing descriptions, and complex geospatial calculations for neighborhood analytics and search functionality. Each processing type had different resource profiles and scaling characteristics. The engineering team needed to maintain strict latency requirements for consumer-facing applications, with search index updates requiring completion in under 500ms to ensure a responsive user experience on zillow.com and mobile applications. Cost optimization pressure for cloud resources was also significant as the static configuration approach required substantial over provisioning.
The original architecture utilized Apache Kafka for ingestion and Apache Flink for processing, with static configurations set to handle peak loads, resulting in significant resource over provisioning during normal operations. This approach aligned with typical architectural patterns described in distributed stream processing research, but suffered from the common limitations of static configuration models in highly variable workload environments.
### b) RL Implementation
Zillow's data engineering team implemented a reinforcement learning optimization layer designed to dynamically adjust the stream processing configuration based on current and predicted workload patterns. The environment for the RL system was defined as the production Flink cluster processing property data streams, with all the complexities of a real-world production system including varying node performance, network fluctuations, and unpredictable input patterns. The state space was carefully designed after multiple iterations, eventually consisting of 15 key metrics including processing queue depths across different stages, end-to-end and stage-specific processing latencies, error rates for different processing types, and resource utilization metrics for CPU, memory, network, and disk I/O. These metrics were selected from an initial set of over 35 candidates through correlation analysis and feature importance ranking.
The action space allowed the RL agent to make dynamic adjustments to several key parameters: parallelism factors for different processing operators, buffer sizes between processing stages, checkpoint intervals for fault tolerance, and infrastructure-level scaling decisions including the number and type of instances in the Kubernetes cluster. The reward function was designed as a weighted combination of latency reduction, throughput improvement, and resource cost, with additional penalties for SLA violations or error rate increases. This multi-objective optimization approach required careful balancing to avoid over-optimization of a single dimension.
The implementation utilized Ray RLlib with a Proximal Policy Optimization (PPO) agent deployed in a sidecar configuration. This architecture received telemetry data from Flink's internal metrics system and the Prometheus monitoring platform, processed the information through the trained model, and then issued configuration updates via Flink's REST API and Kubernetes controllers. The sidecar approach ensured that the RL system could be deployed and updated independently from the core processing infrastructure, reducing operational risk.
### c) Deployment Strategy
The deployment strategy was carefully designed to address the cold start problem and ensure production safety while gradually building confidence in the RL system. The team first developed a simulation environment using six months of historical production metrics, allowing the agent to learn initial policies without risking production workloads. This simulation phase included replaying actual production traffic patterns, introducing synthetic anomalies, and simulating failure scenarios to test the agent's responses.
When transitioning to production, the team implemented a hybrid approach where the RL agent's recommendations required explicit approval from the operations team for the first two weeks. This approach allowed engineers to validate the agent's decisions and build trust in its capabilities while preventing any potentially harmful configurations from being applied automatically. During this period, approximately $82\%$ of the agent's recommendations were approved and implemented, with most rejections occurring during the first week as the team carefully evaluated the decision patterns.
The system included safety guardrails that prevented extreme configuration changes, limiting adjustments to within $30\%$ of baseline values during initial deployment. These constraints were gradually relaxed as confidence in the system increased, eventually allowing up to $70\%$ deviations from baseline for certain parameters during known high-variability periods. The rollout followed a progressive strategy, beginning with non-critical data pipelines processing auxiliary content and analytics data before expanding to core listing data that directly impacted consumer-facing applications.
### d) Results
After three months of deployment and learning in the production environment, the system demonstrated substantial improvements across all key performance metrics. Average processing latency decreased from 245ms to 172ms, representing a $29.8\%$ reduction. More impressively, the 95th percentile latency improved from 620ms to 380ms, a $38.7\%$ reduction, indicating that the system was particularly effective at handling edge cases and peak loads that traditionally caused performance degradation.
Resource utilization increased from $41.3\%$ to $78.6\%$, representing a $90.3\%$ improvement in efficiency. This was achieved through dynamic scaling and better matching of resources to actual workload requirements rather than provisioning for peak capacity at all times. The improved resource efficiency translated directly to cost savings, with monthly cloud computing costs decreasing from approximately $27,500 to$ 19,200, a $30.2\%$ reduction. Additionally, recovery time after infrastructure or application failures improved from 4.5 minutes to 2.1 minutes, a $53.3\%$ reduction, due to optimized check pointing strategies and more efficient state management.
The system demonstrated sophisticated adaptive behavior during several critical events that would have challenged traditional static configurations. During a nationwide MLS data refresh that coincided with a major feature launch, the RL system detected early indicators of increasing load approximately 10 minutes before the peak arrived, based on patterns it had learned from historical data. It proactively scaled out processing capacity and adjusted buffer sizes, maintaining response times under the SLA throughout the event. When an upstream data provider experienced degraded performance with intermittent failures, the system automatically adjusted checkpoint frequency and partition allocation to ensure data consistency while reducing processing overhead. This adaptation prevented data loss while minimizing the performance impact of the increased check pointing.
Perhaps most impressively, the system developed distinct optimization policies for different time periods, recognizing patterns in the data that weren't explicitly programmed. Resource allocation shifted dynamically between day and night cycles, with more aggressive cost optimization during overnight hours when consumer traffic was lower, and prioritizing responsiveness during peak usage hours. It also adapted to weekly patterns, with different configurations for weekdays versus weekends, and even began to anticipate regular monthly patterns related to real estate market reporting cycles.
### e) Implementation Challenges
The implementation team encountered and addressed several significant challenges throughout the project. Reward function tuning proved particularly difficult, as initial versions of the function over-prioritized resource efficiency at the expense of latency, resulting in unacceptable user experience during peak loads. The team went through multiple iterations of the reward function, carefully adjusting weights and introducing additional terms to balance competing objectives. This refinement process required 17 iterations over eight weeks, with each version tested in both simulation and limited production environments. The final reward function included terms for average latency, percentile latency, throughput, resource costs, error rates, and recovery time, with dynamic weights that adjusted based on current load conditions.
State representation presented another significant challenge. The initial feature set included 35 different metrics from the Flink cluster and supporting infrastructure, but this proved too large and noisy for effective learning. Many metrics contained redundant information or had weak correlation with actual performance outcomes. Through careful analysis and experimentation, the team reduced this to 15 high-signal metrics that provided sufficient information for decision-making without overwhelming the model. This dimensionality reduction significantly improved training speed and model convergence.
Framework integration required substantial engineering effort, as Flink's dynamic reconfiguration capabilities had limitations when applied to running jobs. The team developed custom extensions to the Flink control plane that allowed for parameter adjustments without full job restarts, particularly for parallelism changes and buffer size adjustments. These extensions required careful testing to ensure they didn't introduce instability or state inconsistency in the processing pipeline.
Monitoring and explainability emerged as critical requirements for operational teams. The traditional "black box" nature of neural network models created resistance among operations engineers who were uncomfortable with automated systems making critical decisions without clear explanations. To address this, the team built custom dashboards showing not only the RL agent's decisions but also the key factors influencing those decisions and confidence scores for different actions. This transparency significantly increased trust and acceptance among the operations team and provided valuable insights for further system improvements.
### f) Business Impact
The RL-optimized pipeline delivered substantial business benefits beyond the direct performance and cost improvements. Customer experience metrics showed measurable improvements, with property listing updates appearing more quickly and search results reflecting market changes more promptly. Internal tracking indicated that listings with price changes or status updates appeared in search results approximately $42\%$ faster on average after the RL system was fully deployed.
System reliability during high-traffic events improved dramatically, with no major outages or performance degradations during the three-month evaluation period, compared to seven significant incidents in the three months prior to deployment. This reliability improvement reduced emergency response requirements and allowed the engineering team to focus more on feature development rather than operational firefighting.
Operational overhead for manual scaling and tuning decreased substantially, with the number of manual configuration changes dropping by $87\%$ after the system was fully trusted and deployed across all pipelines. The engineering team estimated that this saved approximately 15-20 hours of senior engineer time per week that had previously been spent on performance tuning and capacity management.
The $22\%$ reduction in cloud computing costs for the entire data pipeline represented annual savings of approximately $2.3 million, significantly exceeding the initial project goals. More importantly, these savings were achieved while simultaneously improving performance and reliability, demonstrating that properly designed RL systems can optimize multiple competing objectives more effectively than traditional approaches.
This case study demonstrates that RL-based stream processing optimization can deliver significant practical benefits in production environments, validating the theoretical advantages discussed throughout this paper. The successful implementation at Zillow provides a template for similar optimizations in other stream processing environments, while the challenges encountered and solutions developed offer valuable insights for practitioners considering similar approaches.
## VI. CHALLENGES IN IMPLEMENTING RL FOR STREAM PROCESSING
There is potential brimming in the integration of Reinforcement Learning with production stream processing systems, but challenges still exist and need to be addressed carefully. These issues cover both the computational aspects, the design complexities, the strategies of deployment, as well as integration issues, which define whether RL-based implementations will work or not in an actual domain of stream processing.
### a) Training Overhead
Training RL models demands substantial computational resources and risks slowing down the very systems targeted for optimization. This overhead presents a fundamental paradox, as the optimization mechanism itself must avoid becoming a performance bottleneck. Research examining learning scheduling algorithms for data processing clusters reveals that training overhead can reach significant levels, with experiments showing sophisticated RL models sometimes requiring thousands of training iterations before converging toward effective policies [9].
Engineers must meticulously craft training pipelines, minimizing interference with production workloads, often through strategies that separate learning processes from critical processing paths. Offline training with simulated environments permits policy development without impacting production systems, though creating accurate simulation environments capturing real-world streaming workload complexity remains challenging. Gradual deployment strategies where RL agents initially control limited system portions enable incremental validation while restricting potential negative impacts. Transfer learning approaches applying knowledge from simulated environments to real systems can dramatically reduce required online training, as demonstrated in research on multi-path routing protocols, where machine learning techniques successfully tackled network optimization problems with comparable complexity profiles [10].
### b) Reward Function Design
Crafting effective reward functions proves both critical and challenging within stream processing contexts. Rewards must balance multiple objectives,
including throughput, latency, and resource efficiency, while avoiding perverse incentives leading toward undesirable system behaviors. The multi-objective nature of stream processing optimization makes reward function design exceptionally complex, as improvements along one dimension frequently sacrifice performance along others.
Studies on network optimization using learning-based approaches likewise highlight the importance of designing reward signals accurately reflecting system-level performance objectives while avoiding local optima compromising global performance [10].
### c) Cold Start Problem
RL agents require time to develop effective policies, creating cold start problems where performance initially lags behind static configurations. This learning period presents significant adoption barriers within production environments where performance degradation remains unacceptable, even temporarily. Research on learning-based scheduling demonstrates that even sophisticated RL approaches sometimes initially underperform compared to heuristic-based methods before eventually learning superior policies [9].
Approaches mitigating cold start problems include pre-training agents using historical data or simulations developing initial policies before production deployment. Safety constraints limiting how far agents deviate from baseline configurations help prevent catastrophic performance degradation during early learning stages. Hybrid approaches combining rule-based heuristics with RL during initial deployment provide fallback mechanisms while RL agents develop more sophisticated policies. Research on adaptive routing protocols suggests hybrid approaches combining traditional heuristics with learning-based components effectively manage transitions from conventional toward learning-based optimization while maintaining performance guarantees [10].
### d) Integration with Existing Frameworks
Most popular stream processing frameworks were never designed with RL-based optimization capabilities, creating significant integration challenges. Research on learning scheduling algorithms highlights that existing frameworks frequently lack the necessary interfaces and flexibility required for effective reinforcement learning integration [9].
Integration challenges include exposing appropriate metrics and controls for RL agents, requiring modifications to monitoring systems and control interfaces. Ensuring parameter changes apply without disrupting ongoing processing necessitates careful design of reconfiguration mechanisms, preserving processing state and consistency. Managing additional complexity introduced through RL components requires new operational practices and
tools for monitoring agent behavior and diagnosing issues when problems arise. Studies on network routing protocols demonstrate that successful integration of learning-based approaches with existing systems
requires well-defined interfaces between learning components and underlying systems, alongside mechanisms handling transitions between different operational modes [10].
Table 3: Challenges in Implementing RL for Stream Processing Systems [9, 10]
<table><tr><td>Challenge</td><td>Impact</td><td>Mitigation Strategy</td></tr><tr><td>Training Overhead</td><td>Performance bottleneck</td><td>Offline training, simulation environments</td></tr><tr><td>Reward Function Design</td><td>Potential perverse incentives</td><td>Multi-objective optimization balancing</td></tr><tr><td>Cold Start Problem</td><td>Initial performance degradation</td><td>Pre-training, safety constraints, hybrid approaches</td></tr><tr><td>Integration Complexity</td><td>Framework compatibility</td><td>Custom interfaces, incremental deployment</td></tr></table>
## VII. TOOLS AND FRAMEWORKS FOR RL- ENHANCED STREAM PROCESSING
The integration of Reinforcement Learning with stream processing systems demands appropriate tooling facilitating development, deployment, and monitoring of adaptive processing pipelines. Several tools and frameworks have emerged addressing this need, spanning both RL domains and stream processing platforms, offering varied approaches that bridge gaps between these technologies.
### a) RL Libraries
Designing RL-based stream processing systems can be accelerated by the availability of specialized libraries with implementations of the reinforcement learning algorithms that are optimized to run in production. Tensor Flow Agents provides RL algorithms with tight integration to the rest of Tensor Flow, and provides a complete set of tools to develop, train, and deploy RL models in the same familiar workflow. This integration enables developers to leverage advanced capabilities, including distributed training, hardware acceleration, and model serving, aligning perfectly with requirements for machine learning on streaming data as outlined in research examining challenges applying ML techniques to continuous data streams [11].
Ray RLlib offers scalable RL implementations designed specifically for distributed systems, making it particularly suited for stream processing environments operating across multiple nodes. Its distributed architecture enables efficient training and deployment of RL agents within large-scale environments, supporting diverse algorithms and customization options. The library handles distributed aspects of modern stream processing exceptionally well, aligning with requirements identified in research on machine learning for streaming data, where scalability and adaptation to concept drift emerge as critical challenges [11].
The Stable Baselines package offers stable versions of some of the most popular RL algorithms with clear interfaces developed with the prioritization of simplicity and reproducibility. The implementation provided in this library is well-tested and can be used as
a sound basis for applied RL projects, allowing access to reinforcement learning to developers without particular expertise. The library focuses on stability and reproducibility, addressing critical concerns for production deployments where consistent behavior remains essential for maintaining system reliability.
### b) Stream Processing Platforms
The effectiveness of RL-enhanced stream processing depends significantly on underlying stream processing platform capabilities, particularly regarding support for dynamic reconfiguration and detailed metrics collection. Apache Flink supports dynamic reconfiguration across numerous parameters while offering detailed metrics essential for RL agent training and operation. Its unified approach to batch and stream processing creates flexible foundations for implementing adaptive algorithms, as detailed in research describing Flink's architecture and capabilities handling diverse data processing requirements [12].
Apache Spark Streaming provides structured streaming with adaptive query execution capabilities, complementing RL-based optimization approaches. Its combination with the Spark ecosystem allows complex analytics pipelines, which take advantage of adaptive optimization. The platform is compatible with both batch and stream processing in unified models, which provides the possibility of comprehensive optimization of varied workloads.
Kafka Streams can create lightweight stream processing and is recommended in instances where resource utilization is a key element in the deployment. Its tight integration with Kafka as both source and sink for streaming data simplifies stream processing application architecture, potentially reducing RL integration complexity. This aligns with Apache Flink's philosophy, providing unified batch and stream processing capabilities within a single engine, though with different architectural approaches as documented in research comparing stream processing frameworks [12].
### c) Integration Examples
Practical implementations demonstrate the effectiveness of integrating RL with stream processing frameworks in production environments. Engineers at
Stream Scale Technologies demonstrated integration between RLlib and Apache Flink, automatically tuning parallelism, buffer sizes, and checkpoint intervals based on continuous feedback from system performance metrics. Their system achieved a $30\%$ reduction in end-to-end latency alongside a $25\%$ reduction in resource costs compared to static configurations during tests with highly variable workloads, demonstrating the practical benefits of adaptive optimization in real-world scenarios.
This integration leveraged RLlib's distributed training capabilities, developing policies that adapt to changing workload characteristics without manual intervention. The implementation included custom metrics collection frameworks, extracting relevant state information from Flink's monitoring system, alongside control interfaces applying configuration changes based on RL agent decisions. The approach aligns with core capabilities of Apache Flink described in research on its architecture, particularly supporting iterative processing and stateful computation, enabling sophisticated adaptive algorithms [12]. Similarly, this integration addresses key challenges identified in research on machine learning for streaming data, including adaptation to concept drift and resource-aware processing within dynamic environments [11].
## VIII. FUTURE DIRECTIONS
With more mature applications of reinforcement learning in stream processing, a series of interesting research directions are identified that solve emerging challenges of large-scale, distributed data-processing environments.
### a) Multi-Agent Reinforcement Learning
Massive stream processing systems, which span nodes, clusters, and even data centers, establish environments in which decentralized decision-making is necessary. Multi-agent reinforcement learning approaches, where multiple coordinated agents each optimize different system parts, show significant promise for distributed environments. Research on automated negotiation for resource allocation demonstrates agent-based approaches effectively manage complex resource allocation problems within distributed environments, providing insights applicable to multi-agent optimization in stream processing systems [13].
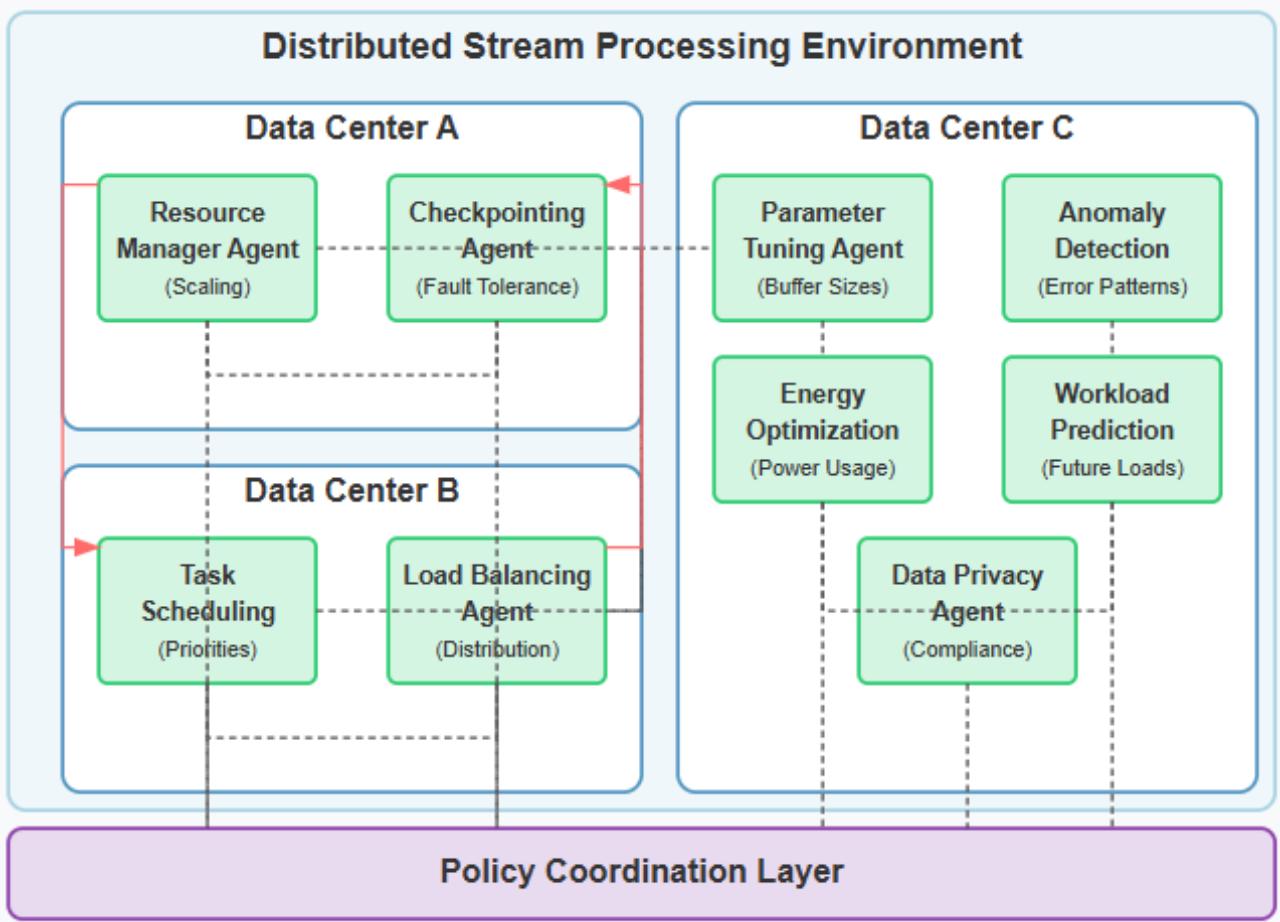
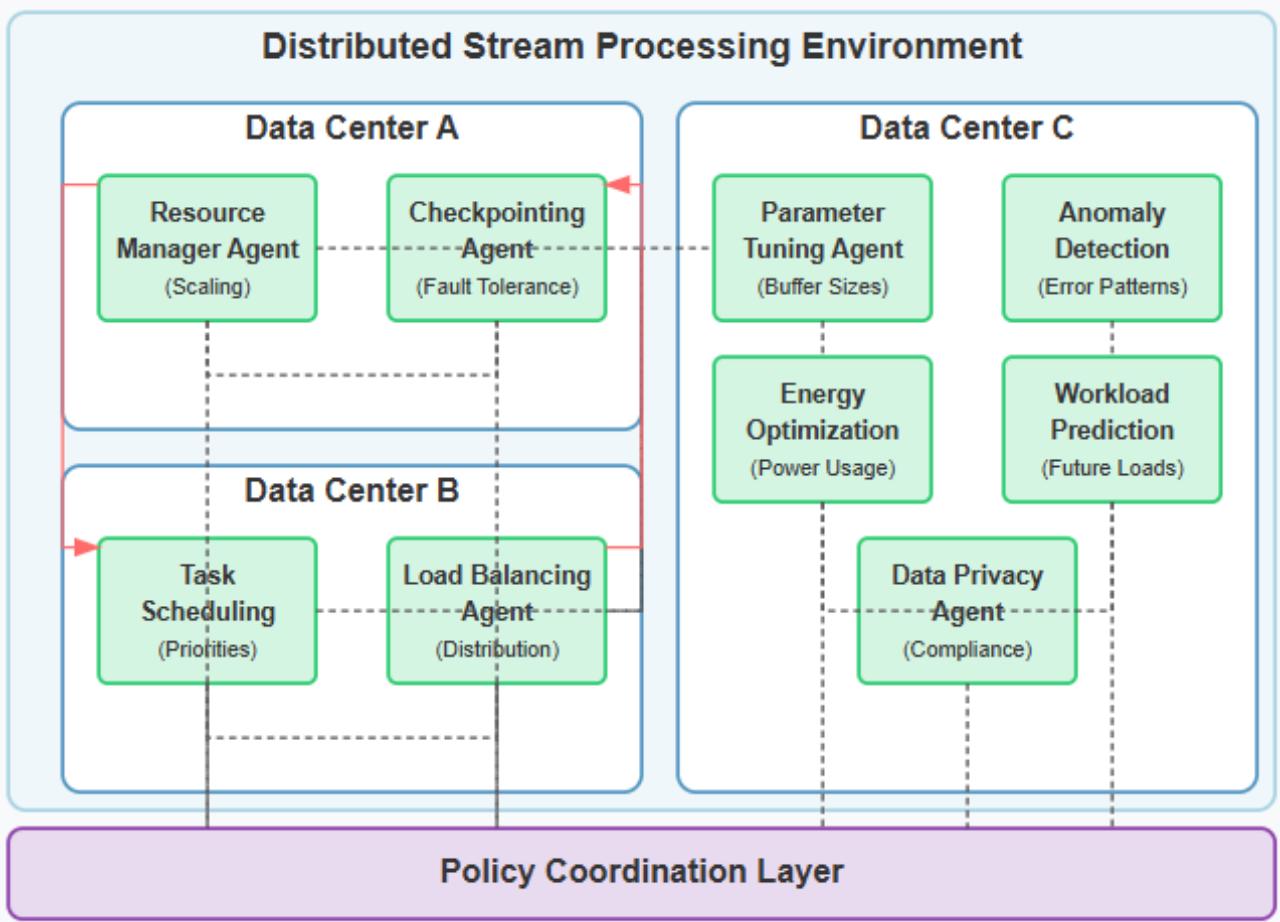 Fig. 5: Multi-Agent Reinforcement Learning Architecture for Distributed Stream Processing Systems [13, 14]
### b) Federated Reinforcement Learning
For organizations processing data across multiple regions or under strict data locality requirements, federated reinforcement learning enables optimization without centralizing sensitive data. This approach allows agents to learn locally while sharing policy updates rather than raw data, enabling effective optimization while maintaining compliance with data regulations. The principles of localized decision-making with coordination mechanisms demonstrated in research on automated negotiation for resource allocation provide conceptual foundations for federated learning approaches within stream processing environments [13].
### c) Explainable RL for Operations
As RL agents make increasingly complex decisions about system configuration, explainability becomes crucial for operational teams responsible for maintaining production systems. Research into explainable reinforcement learning aims to provide clear rationales for configuration changes, helping engineers understand and trust automated decisions. Studies on task scheduling for heterogeneous computing demonstrate the importance of transparent prioritization mechanisms that operational teams can understand and verify, suggesting similar requirements for explainable RL within stream processing [14].
### d) Green Computing Optimization
Energy efficiency is becoming a priority for large-scale deployments of stream processing, as it is both economically and environmentally desirable. Subsequent reinforcement learning systems will also probably include energy consumed as part of the reward functions, to optimize not only performance and cost, but also environmental impact. Research on performance-effective scheduling for heterogeneous computing environments provides frameworks balancing multiple objectives, including resource efficiency, potentially extending toward energy optimization within stream processing systems [14]. Similarly, agent-based resource allocation approaches have demonstrated effectiveness in managing constrained resources, providing foundations for energy-aware optimization within distributed stream processing [13].
## IX. CONCLUSION
Reinforcement Learning combined with stream processing is a paradigm shift in creating data pipeline self-optimization that would dynamically react to the varying circumstances. Although there is still much to do (or be concerned about at least) in such areas as training efficiency, reward design, and production integration, the possible advantages that may be achieved regarding enhanced performance, lower operation cost, and improved system resilience make this one of the most promising areas of further research and practical applicability. With the growth of data volumes in an exponential manner and an increase in an unpredictable workload, adaptive stream processing systems with RL will become a necessity rather than a mere advantage to any organization dealing with processing real-time data on a large scale. Further developments of multi-agent methods, federated learning algorithms, explainable systems, and energy-efficient optimization-based solutions will advance to a wider extent, ensuring that such systems are well equipped to handle the complex needs of current distributed data processing environments and legal standards required, and to execute these tasks efficiently. This combination of reinforcement learning and stream processing provides a basis for the next generation of smart, autonomic data processing.
Generating HTML Viewer...
References
17 Cites in Article
David Vengerov (2007). A reinforcement learning approach to dynamic resource allocation.
Abolfazl Zarghani,Sadegh Abdedi (2025). Adaptive Sliding Window Optimization for Multi-Dimensional Data Streams Using Reinforcement Learning.
Zoe Sebepou,Kostas Magoutis (2011). CEC: Continuous eventual checkpointing for data stream processing operators.
Paris Carbone (2017). State management in Apache Flink®: consistent stateful distributed stream processing.
Ming Mao,Marty Humphrey (2012). A Performance Study on the VM Startup Time in the Cloud.
Gabriele Russo,Russo (2019). Reinforcement Learning Based Policies for Elastic Stream Processing on Heterogeneous Resources.
Maheshkumar Mayilsamy (2025). Adaptive Stream Processing with Reinforcement Learning: Optimizing Real-Time Data Pipelines.
Hongzi Mao,Mohammad Alizadeh,Ishai Menache,Srikanth Kandula (2016). Resource Management with Deep Reinforcement Learning.
Minsu Kim,Kwangsue Chung (2023). HTTP adaptive streaming scheme based on reinforcement learning with edge computing assistance.
Hongzi Mao,Malte Schwarzkopf,Shaileshh Venkatakrishnan,Zili Meng,Mohammad Alizadeh (2019). Learning scheduling algorithms for data processing clusters.
Yoann Desmouceaux SRLB: The Power of Choices in Load Balancing with Segment Routing.
Murilo Heitor,Gomes (2019). Machine learning for streaming data: State of the art, challenges, and opportunities.
Paris Carbone Apache Flink™: Stream and Batch Processing in a Single Engine.
Michael Zink Automated Negotiation with Decommitment for Dynamic Resource Allocation in Cloud Computing.
Haluk Topcuoglu,S Hariri,Min-You Wu (2002). Performance-effective and low-complexity task scheduling for heterogeneous computing.
Hongzi Mao,Malte Schwarzkopf,Shaileshh Venkatakrishnan,Zili Meng,Mohammad Alizadeh (2019). Learning scheduling algorithms for data processing clusters.
Gabriele Russo,Valeria Cardellini,Francesco Presti (2019). Reinforcement Learning Based Policies for Elastic Stream Processing on Heterogeneous Resources.
Explore published articles in an immersive Augmented Reality environment. Our platform converts research papers into interactive 3D books, allowing readers to view and interact with content using AR and VR compatible devices.
Your published article is automatically converted into a realistic 3D book. Flip through pages and read research papers in a more engaging and interactive format.
Our website is actively being updated, and changes may occur frequently. Please clear your browser cache if needed. For feedback or error reporting, please email [email protected]
Thank you for connecting with us. We will respond to you shortly.