This article explores how criminal risk-need assessment algorithms (e.g., COMPAS) and financial scoring systems (e.g., FICO) create feedback loops that perpetuate systemic biases, disproportionately affecting already financially marginalized groups. It examines the intersection of these tools, particularly how factors like place of residence, financial instability, and access to resources influence both systems. Using a theoretical critique, this study indirectly analyzes (1) criminological theories, (2) algorithmic design principles, and (3) evidentiary standards. The criminological theories considered-including Social Class and Crime, Strain Theory, Subcultural Perspectives, Labeling and Marxist/ Conflict Theories, Control Theories, and Differential Association Theory-share a consensus that environmental factors contribute to crime. While this research does not aim to verify their conclusions, it investigates how algorithmic models incorporate personal financial data and place of residence. It also examines the relevance of these to observing non-virtuous behaviors, as supported by the previously mentioned criminological theories, although the findings of these theories may differ regarding the levels of relevance of the environment to criminal occurrences. Additionally, evidentiary standards and numerical reasoning help assess how these inputs shape potentially biased and unfair scores.
### INTRODUCTION
Algorithmic decision-making has become a cornerstone of modern systems, transforming processes in both the financial and criminal justice sectors. Tools like COMPAS, used in risk-need assessments, and financial algorithms such as FICO,
This Article examines a Concerning Hypothesis: That criminal risk-need assessment algorithms and financial scoring systems are interconnected in a feedback loop, where outputs from one system reinforce low scores in the other. This cyclical relationship highlights the unintended consequences of relying on algorithms, especially for marginalized groups that are already disadvantaged by structural inequities. Consider, for example, a scenario in which an offender is serving his or her time and must change their place of residence to alter their friends and acquaintances, job, or school situation, and better integrate into society. Now consider that changing residences depends on financial resources, which in turn rely on various factors such as one's current location, social interactions, employment, educational background, and more. Finally, note that being unable to change residences, whether due to these reasons or others, may represent an environmental barrier to forming new friendships, finding jobs in different fields, and the manner in which one interacts with society and its members—not to mention the members themselves. This series of events could likely lead to consistently poor scores in both criminal and financial assessments. Such a scenario would probably worsen the financially marginalized groups, reinforcing some of the already existing social disparities.
The criminological theories, including Social Class and Crime, Strain Theory, Subcultural Perspectives, Labeling and Marxist/Conflict Theories, Control Theories, and Differential Association Theory, share a consensus that environmental factors contribute to crime. They differ, however, in the significance of the place of residence—environment—to criminality. Interesting and complex as they may be, their studies have repeatedly demonstrated its relevance, though this research article does not aim to disprove or reinforce this correctness. Suffice it to say that, regardless of the degree to which place of residence—environment—matters, it seems undeniable that all of them at least recognize its significance, which is sufficient for this research article to build the rest of its reasoning and argument.
and financial systems, as well as the subjective interpretation of concepts and/or terms used by the referred algorithms and vague legal texts. Hence, the subjective procedural legislation in Spain, Mexico, Chile, and Italy, as discussed in Ferrer Beltrán (2021: 19-21), and in Brazil as defended by Santos (2024).
These challenges have resulted in, among other efforts, the adoption of algorithms as seemingly neutral adjudicators. Yet, far from eliminating bias, these tools may actually amplify it by incorporating socio-economic factors—such as place of residence, financial instability, and access to resources—into their decision-making processes. See Angwin et al. (2016), a ProPublica study that supports the existence of racial bias in COMPAS, worsening arguably already stigmatized communities, and Dressel and Farid (2018: 1, 2), which argues that the explicit consideration of race does not significantly alter the results. One hypothesis is that racial data is implicit in other factors, making its explicit inclusion not only unnecessary but also irrelevant. Presently, the academic community still discusses the existence of bias in COMPAS and similar algorithms.
Findings suggest that low scores in one system exacerbate low scores in the other, creating a cyclical disadvantage. This reinforces economic and social inequities, calling for greater scrutiny, transparency, and fairness in algorithmic design and application. Ignoring these issues risks deepening poverty, restricting credit access, and increasing incarceration rates among financially marginalized communities. By highlighting these feedback loops, this study aims to inform academic research and policy reforms to mitigate algorithmic bias and its far-reaching consequences.
## I. RISK ASSESSMENT
Risk-need assessment instruments, particularly computer-based algorithms, are examples of ways to combat mass incarceration, reduce the prison population, and, to some extent, address the movements toward penalization and criminalization. They also respond to the increasing demands for public accountability, security, and non-subjective judicial decisions, particularly evidence-based ones.
While there is considerable variation in the application of these tools within criminal justice settings, many international jurisdictions are increasingly using risk instruments to structure, inform, and determine a wider range of correction-management practices. These practices include arrest, diversion, bail, pre-sentence reports, sentencing, prison classification, and parole decisions. (Hannah-Moffat, 2013: 270) As noted in Angwin et al. (2016), the idea of using risk assessment tools does not focus only on punitive measures like sentencing but also on assisting at even more important stages, such as decisions about preventive measures, the application of intermediate
sanctions and the choose of adequate social programs based on the likelihood of offenders recidivating. Hence the original purpose of the algorithm COMPAS there explained.
Using risk assessment tools aims to achieve unbiased evidence-based decisions. As Hannah-Moffat (2013: 270) noted, Etienne (2009) describes it as smart evidence-based sentencing, and Andrews and Dowden (2008) refer to it as crime prevention jurisprudence, all intended to enhance public safety. In line with this, Heilbrun (2009), MacKenzie (2001), Marcus (2009a) and (2009b), Warren (2007), and Wolfe (2008) cited in Hannah-Moffat (2013: 270).
If, on the one hand, a major goal of these risk assessment tools is to diminish the likelihood of recidivism by providing evidence-based decisions, on the other hand, another goal is to allocate public resources and correctional program spaces using an empirically supported method. In line with this, Bonta and Andrews (2024), Etienne (2009), and Hannah-Moffat (2013).
Risk-need assessment tools are justified on the premise that the decision-making process relies on aggregate statistics to categorize offenses and offenders, as well as to determine appropriate governmental responses. Meanwhile, traditional methods depend on subjective professional or clinical knowledge. This aligns with the works of Hannah-Moffat (2005) and (2013) as well as Bonta and Andrews (2024).
The comparatively discretionary and arguably arbitrary nature of those in positions to adjudicate is the main reason why risk-need assessments began to be used in the 1970s. The later adoption of sentencing guidelines in 1999 aimed to 1) reduce judicial disparity, 2) promote consistent sentencing, 3) prioritize and allocate correctional resources, 4) adjust punishments for certain categories of offenders, 5) reduce prison overcrowding, and 6) encourage the use of non-incarceration sanctions (Hannah-Moffat, 2013: 271) and Bonta and Andrews (2024: 202-210).
### a) Risk Assessment Generations
## i. First-generation Risk Assessment
The first generation was based on clinical prediction, whereas the subsequent generations rely on quantitative methods. Since this generation depends on practitioners' skill sets, it is considered subjective, unempirical, and with lower predictive accuracy. Therefore, using actuarial instruments remains necessary to achieve higher accuracy levels, as relying solely on what can be termed in evidentiary reasoning as intuitive maxim or experimental presumption is deemed incorrect, according to Hannah-Moffat (2013: 271) and Bonta and Andrews (2024: 202-210) and from a judicial perspective in Ferrer Beltrán (2007), (2021), as well as Santos (2024).
## ii. Second-generation Risk Assessment
The first generation relied on subjective and personal analysis, but in the 1970s, a new objective numerical form emerged. The second generation adopts an evidence-based approach, relying on quantitative risk scores from large population studies, as noted by AEGisdóttier et al. (2006), Hannah-Moffat (2013: 271), and Bonta and Andrews (2024: 202-210).
According to these scholars, this generation uses static historical factors, marked as present (1) or absent (0), for predictions. Examples include age, gender, and criminal history. By relying solely on static factors, they fail to capture potential improvements of offenders undergoing their sentences, whether through intermediate sanctions or custodial terms. Consequently, this generation, although numerically based—and therefore considered to have enhanced accuracy—struggles to adapt alongside offenders undergoing their sentences.
## iii. Third-generation Risk Assessment
One of the most fundamental principles of criminal law is the conviction that sanctions cannot simply be a form of vendetta. In other words, if a sentence is intended to be retributive—serving as punishment—it must also incapacitate—by implementing security measures—and deter—through general and specific prevention. Therefore, if a sentence is likely to prove itself as ineffective in incapacitating and deterring, it would, by definition, be nothing more than a governmental tool for personal or social vendetta.
The flip side of this expectation of failure is the belief that offenders can change over time. This indicates a shift in their personal characteristics and circumstances that the previous generations did not fully acknowledge. The second generation, for example, relies solely on static factors, overlooking dynamic personal aspects that can vary while offenders are serving their sentences.
While static factors remain crucial, incorporating dynamic risk factors or criminogenic need factors enhances the effectiveness of correctional treatments. Examples of these factors include employment status (employed/unemployed), friendships, and family relationships, considering their roles as either supportive or unsupportive. See Bonta and Andrews (2024: 202-210) apud Hannah-Moffat (2013: 275).
While previous generations used the term risk assessment, the current generations refer to these tools as risk-need assessments, emphasizing the importance of offenders' needs in risk prediction. The criticism arises from the fact that these needs are not considered individually but are categorized as 'proven' to be relevant to the observation of criminal behavior.
Thus, there is a clear distinction between criminogenic needs—social challenges addressed by public policies to reduce criminal tendencies—and non- criminogenic needs—equally important social challenges that are not seen as relevant by the government due to their lack of direct and immediate connection to criminal behavior. By focusing solely on those needs that increase the likelihood of criminal activity, the state tacitly establishes its priorities. For more, see Bonta and Andrews (2024: 202-210) apud Hannah-Moffat (2013: 275).
## iv. Fourth-generation Risk Assessment
According to Bonta and Andrews (2024: 202-210) and Hannah-Moffat (2013: 279), the fourth generation of risk-need technologies still has dynamic risk and criminogenic needs at its core. The authors call attention to the Risk-Needs Responsivity Model (RNR), which is crucial for assessing, controlling, and reducing the likelihood of non-virtuous behavior.
The RNR model uses the risk principle to prevent new offenses—recidivism—and to wisely allocate public resources. The risk principle prioritizes preventive measures over retributive ones, assigning different interventions to different offenders based on their levels of risk.
The mentioned authors argue that dynamic factors also consider risk scores that fluctuate throughout undergoing sentences. If the risks and their needs change over time, interventions should be adaptable to reflect offenders' updated risk scores for greater effectiveness. In other words, this corresponds to the responsivity principle.
The criminogenic need factors, or dynamic risk factors, explored by Bonta and Andrews (2024: 46), are: 1) Criminal History; 2) Procriminal Attitudes; 3) Procriminal Associates; 4) Antisocial Personality Pattern; 5) Family/Marital; 6) School/Work; 7) Substance Misuse; 8) Leisure/Recreation Activities.
### b) Risk-Need Assessment Difficulties
## i. Categorization vs. Principle of Individualized Justice
Risk assessment tools, whether they consider only static factors or also dynamic ones, challenge some of the most fundamental principles in criminal law, such as individualized sentencing and personalized justice. These principles, though necessary, are not part of the scope of this article and imply that personal characteristics must be considered for true justice to occur. Therefore, categorizing and scoring offenders using Boolean Logic - 0 vs. 1 - requires standardization of procedures and outcomes, de-individualization (legal context), deindividuation (psychological context), and a false homogenization masked by an illusion of stability and coherence in the rule of law.
In this scenario, the offender would be evaluated not as an individual but based on assumptions about their group or categories that scholars previously flagged as of criminological relevance. See Bonta and Andrews (2024: 202-210) and Hannah-Moffat (2013: 279).
## ii. Enough to be Considered Proven by Chance
The sole purpose of the proof—as a judicial tool—is to ensure that what is deemed proven aligns with the tout court truth as closely as possible. Otherwise, the correctness or incorrectness of a decision—such as those made statistically—would be determined by chance, or as one might say in Portuguese, na sorte (Santos, 2024), and in Spanish, al azar (Ferrer Beltran, 2021).
Denying the perfection of these risk-need assessment tools leads to admitting their fallibility. If that's the case, this statistical justice, or justice by numbers, is achieved through likelihood or probability. If that is the case, the challenge lies in determining how likely something must be to be categorized as 1 vs. 0—an either/or reasoning—when scoring individuals.
## iii. Risk of Error Acceptance Levels
The risk of error in risk-need tools refers to the level of error in the decision-making process that society is willing to accept, raising important questions about their compatibility with the standards of proof used in the rule of law. In simple terms, standards of proof are the criteria used to determine what must be present for a set of evidence to be considered proven, or, using risk-need assessment terminology, present. For example, they provide justificatory interpretive criteria for the parties, that is, previously agreed levels of what should be regarded as sufficient and, therefore, elements that could logically support and justify decisions. See Laudan (2016: 103).
It is understood that, among other things, the presence of clear standards of proof results in the establishment and allocation of the risk of error between the parties. This means determining how many false positives—convicting an innocent person or finding liability where none exists—and false negatives—acquitting a guilty person or dismissing a valid claim—should be considered acceptable and inevitable errors by society and their adjudicators. See Ferrer Beltrán (2021: 115–138), Laudan (2016: 103) and Santos (2024).
In the terminology of risk-need assessment, false positives refer to acknowledging the presence of elements or an offender's membership in a group when such elements or membership do not actually exist; false negatives refer to failing to identify the presence of elements or the offender's membership in a group when they do exist.
Thus, while the primary function of standards of proof is not to allocate the risk of error between the parties, their existence unintentionally does this.
To summarize, what levels of false positives and negatives do risk-need assessment tools accept? How are these levels established so that rational—rather than psychological—controllability and appealability remain possible?
## iv. Numbers Trustworthiness
Treating offenders based on their mathematical scores is, per se, appealing to society. This notion arises from the misguided belief that relying on numbers and statistics are sufficient conditions to ensure objectivity, fairness, and suitability rather than subjective, unequal, disproportionate, and human-biased decisions.
Non-experts often prefer predictions and decisions made by algorithms, while experts are more inclined to dismiss algorithmic advice. Loog et al. (2019) introduced the term algorithm appreciation to describe the favorable perception of algorithms, contrasting it with the idea of algorithm aversion outlined by Dietvorst, Simmons, and Massey (2015). This aversion reflects how individuals tend to avoid algorithms after observing their errors. Loog et al. firmly asserted that their findings contradicted the conclusions of previous researchers.
Understanding the concepts and their implications is essential for evaluating the efficiency and fairness of mathematical justice. That said, probability serves as a framework for quantifying uncertainty and making predictions, categorized mainly into two types: the probability of events and the probability of propositions, each focusing on different aspects of uncertainty and truth.
The probability of events refers to the statistical likelihood of occurrences and is closely linked to mathematical calculations. This approach highlights the objective occurrence of an event over countless trials. For example, the chance of a coin landing heads or tails is generally $50\%$. Such evaluations rely on observable frequencies and are unaffected by personal mental states. This objective[^1] view of probability is essential in fields that rely on empirical data, like the natural sciences and statistical modeling.
Conversely, the probability of propositions examines the likelihood of a statement or hypothesis being true. This concept has a strong epistemological basis, aiming to assess knowledge about the world rather than merely counting event frequencies. This category includes two subtypes: logical (or inductive) probability and subjective probability.
Logical probability, or inductive probability, considers the extent to which one proposition supports another. It involves gradual and partial logical implications, with the probability of facts or hypotheses depending on the linguistic content, structure, and coherence of the propositions. This type is often applied in reasoning processes, such as drawing conclusions from available evidence at hand. This notion is somewhat obvious and intuitive in judicial reasoning processes. See Ferrer Beltrán (2021: 115–138), Laudan (2016: 103), Santos (2024), Savage (1954).
In contrast, subjective probability is based on personal belief. It reflects an individual's assessment of a proposition being true based on available evidence. Unlike objective calculations related to the likelihood of events, subjective probability includes personal judgments and contextual factors, which makes it especially significant in decision-making processes where empirical data might not suffice or even exist.
By distinguishing between event-based and proposition-based probabilities, this framework provides a comprehensive understanding of how uncertainty and truth are assessed across various knowledge areas.
As shown above, there are different ways of conceiving the concept of probability. To this matter Ferrer Beltrán (2007: 94, footnote 63)
Kaye (1988, pp. 3-5) distinguishes up to seven types of probability, although, as he himself oddly acknowledges, it is neither an exhaustive nor an exclusive classification. Other classifications, among the many that exist, can also be found in Barnett (1973, pp. 64-95), Mackie (1973, pp. 154-188), and Good (1983, pp. 70-71). The classification presented in the text is based primarily on the one developed by Savage (1954), although he referred to statistical probability as objective, subjective probability as personalist, and logical probability as necessary.
### a. Probability Applied to Propositions
The concept of probability applied to propositions indicates that it measures our level of knowledge about the world. In this context, it represents an epistemological notion of probability, which evaluates the likelihood that a specific proposition is true.
This notion of probability has scholars supporting two different conceptions:
#### 1. Logical Probability or Inductive Probability
According to Ferrer Beltran (2007: 95), Keynes and Freys pioneered this theory, which was later developed by Carnap (1950). The central idea is that the extent to which $e^2$ confirms $h^3$ does not rely on empirical data but rather on the linguistic content of $e$ and $h$. While empirical information is necessary to determine if $e$ occurs in reality, once this is verified, the shift from $e$ to $h$ depends exclusively on linguistic rules.
Carnap states that probabilistic statements align with the Pascalian model, enabling numerical probability calculations (Ferrer Beltrán, 2007: 95). In contrast, Keynes argues that probability cannot always be strictly measured; it can only be measured through comparisons.
#### 2. Subjectivist Conceptions or Subjective Probability
The probability assigned to a proposition reflects the individual's rational belief in its truth based on a specific element of judgment. Ramsey began this theory, which was further developed by de Finetti, and
Savage (1954), in this order. In line with Ferrer Beltrán (2007: 95-96)
### b. Statistical Probability and Its Problems
A parenthesis seems relevant. Although the material the authors present and the ideas quoted in this paper have not been idealized having risk-need assessment tools as their disquietudes, their contributions to other fields that rely on reasoning techniques are certainly important.
The arguments against using statistical probability to reason proofs and evidence in court cases can similarly be applied to question whether its use presents a problem in risk-need assessment tools.
In Ferrer Beltran (2007: 98), the author points out that many legal scholars contend that frequentist or statistical probability is inadequate for explaining the reasoning behind legal evidence because it neglects individual facts that are critical to the process. Statistical probability only informs about the relative frequencies of specific events occurring in a given context.
To illustrate, paraphrasing Ferrer Beltrán's example, consider a situation where Jane Doe is Richard Roe's sister, and he has killed her. When interpreting this act in numerical terms, it is legally relevant whether he holds a college degree, is over 60 years old, single or married, etc. That is, the frequency with which authors with those characteristics are subject to similar circumstances is relevant. However, while these factors may be measurable, what truly matters is whether Richard Roe killed Jane Doe, not the observable secondary characteristics, no matter whether they can ultimately be quantified. In other terms, although there may be data about these other secondary characteristics, their presence does not guarantee the occurrence of the crime itself. In fact, their presence is, for those who criticize this reasoning technique, irrelevant.
Two cases illustrate how reasoning based on statistical probability can often be, at best, dangerous.
$1^{st}$ example: In a real case from the Supreme Judicial Court of Massachusetts, a woman was struck by a bus at night. The only detail she could remember was that the bus was blue. In that area, only red or blue buses operated, owned by two companies: the blue company and the red company. The blue company possessed $80\%$ of the blue buses, while the red company owned $80\%$ of the red buses and $20\%$ of the blue buses. Consequently, the blue buses were distributed between the two companies in an $80\%$ to $20\%$ ratio. Therefore, the likelihood that the bus that hit the woman belonged to the company with $80\%$ of the blue buses is higher. In simpler terms, statistical reasoning indicates that this may provide sufficient grounds to convict the company with the larger share of blue buses.
$2^{nd}$ example: The "paradox of the gatecrasher" describes a situation at a rodeo event where only 499 tickets were sold, but it was revealed that 1,000 people entered, with 501 of them having done so without paying (illegally). In probabilistic terms, the likelihood that an attendee did not pay is 0.501, while the probability that they did pay is 0.499. According to the theory under analysis, if a viewer were to face a lawsuit, since the probability of not having paid is higher, they should be convicted. Moreover, if all 1,000 attendees were to face lawsuits using the same probabilistic reasoning—ceteris paribus and disregarding the concept of unjust enrichment—then all should be convicted.
In this context, scholars have identified three primary challenges or arguments against using statistical evidence in judicial reasoning[^4].
Minimizing the risks or minimizing the miscarriages of justice is the first challenge. The primary purpose of the judicial proof system, if one can call it that, is to verify the absolute truth—tout court—as much as possible. Adhering to the rule of law requires assigning judicial consequences only when the appropriate factual conditions are met. In other words, penalties should apply solely to those found to have violated the law. Therefore, the epistemological aim of this proof system must focus on minimizing errors.
Given this context, consider the gatecrasher paradox and the situation when a case undergoes judicial analysis. An adjudicator using statistical analysis would, ipso facto, conclude that ruling against 499 carries a lower risk of miscarrying justice. This hypothetical decision, therefore, would not be made based on epistemological values—in other words, by controllable and appealable reasoning techniques aimed at verifying factual occurrences—but rather on numerical data. For the buses, if the statistics were sufficient, an $80\%$ to $20\%$ ratio makes things even clearer.
In this regard, Ferrer Beltrán (2007: 100-101) emphasizes that a decision's justification has two components: substantive and procedural. Even if the procedural aspect is satisfied, the substantive aspect requires that a decision be based on available judicial evidence. In other words, a decision made without considering factual elements—relying solely on statistics—is one made, regardless of what the numbers indicate, by chance. Summarizing, although minimizing errors is undoubtedly important, its achievement through statistics affronts other aspects of the rule of law.
The second challenge concerns the principle of expected value, also known as mathematical expectation. This principle states that the expected value is calculated by multiplying the values of consequences by their probabilities of occurrence. By doing so, the adjudicators would not consider something as having happened or not having happened; it would create a kind of partial or fractional belief in the simultaneous occurrence and non-occurrence of events or facts. The issue with this is that decisions, which rely on proofs and reasoning, are governed by either/or choices. Either something is regarded as having happened, or it is not. They cannot coexist, as many cases correspond to conflicting narratives. See Ferrer Beltrán (2007: 103-106).
Lastly, the argument is about generalizations, or, as it is also referred to, overgeneralizations. Beyond discussing how they can lead to prejudices, the issue lies in the conflict between generalizations conceptualized as non-universal, non-spurious, nonerroneous, or even non-misleading—rooted in empirical data—and individual facts. In other words, reasoning about the occurrence of individual facts based solely on generalizations—of secondary characteristics—defies logic. See Ferrer Beltrán (2007: 106-108), Savage (1954), and Laudan (2016).
## II. CRIMINOGENIC RISK FACTORS: AN OVERVIEW
This academic article proposes that criminal risk-need assessment algorithms influence the financial algorithms used to evaluate and score customers. Furthermore, these algorithms not only interfere with one another but also create a feedback loop. Specifically, they serve as both a cause—though not the only one—and a consequence of the low scores assigned to individuals' assessed rates.
It is implied that low scores in criminal risk-need assessment algorithms contribute to low scores in the financial algorithms employed by banks for credit approvals, and vice versa.
If this is indeed the case, it is essential to acknowledge that having superior financial scores is important, if not indispensable, for obtaining grants, securing loans, purchasing homes, and similar endeavors. Thus, the hypothesis to be tested is whether low financial scores, resulting in less access to essential resources, influence criminal assessment algorithms and whether the outcomes of this assessment affect future financial algorithmic reevaluations in a continuous feedback loop.
To substantiate this hypothesis, the first aspect that requires verification is whether the place of residence is pertinent to the assessment of criminal risk-need tools.
Bonta and Andrews (2024: 46) delineate eight distinct categories in their publication, titled The Psychology of Criminal Conduct, which are recognized as influencing criminological issues. The categories, as previously enumerated in this article, are: 1) Criminal History, 2) Procriminal Attitudes, 3) Procriminal Associates, 4) Antisocial Personality Pattern, 5) Family/Marital, 6) School/Work, 7) Substance Misuse, and 8) Leisure/Recreation. To clarify these concepts, a brief overview of the eight risk-need factors recognized by most scholars is provided below. For a comprehensive read, refer to Bonta and Andrews (2024).
The first category is criminal history. An analysis of historical patterns in criminal behavior, both domestically and internationally, identifies it as a significant risk factor, highlighting the crucial role of the home environment in this study.
Assessing pro-criminal attitudes—the second risk-need factor—requires examining cognitive-emotional states like irritation, resentment, and defiance. These attitudes encompass negative views of the legal system and justice, beliefs that criminal behavior is beneficial, and rationalizations that minimize the harm caused to victims or trivialize their experiences.
The influence of pro-criminal associates—the third risk-need factor—is assessed by investigating the depth and strength of connections with individuals who endorse criminal activities and the degree of isolation from positive social influences.
Certain personality traits—the fourth risk-need factor—contribute to the development of an antisocial personality pattern, which may include impulsivity, a tendency for adventure, a desire for pleasure, the ability to inflict significant harm on multiple victims, restlessness, aggression, and a lack of empathy for others. The study conducted by Sorge et al. (2022) in an Italian context employs substantial quantitative and qualitative data to support its argument. The paper is well-supported and presents compelling arguments. Despite criticisms regarding its social representativeness due to its case study methodology, it illustrates the risk-need factors considered by risk-need assessment tools. Essentially, the article explores filicides and the characteristics typically displayed by mothers who commit such crimes, as well as how these traits are perceived through the lens of the risk-need factors considered by assessment tools.
Family and marital relationships—the fifth risk-need factor—are assessed by examining the quality of interactions and bonds within the family unit, as well as current marital dynamics. As noted by Sorge et al. (2022), the poor quality of relationships among women accused of filicide is a common concern.
The analysis of educational and occupational performance—the sixth risk-need factor—highlights levels of achievement and rewards gained, especially when these align with the individual's aspirations or expectations. See Sorge et al., 2022. This risk-need factor appears relevant not only for the risk-need assessment itself but also for the social perception of risk and criminality.
In line with this, Kanan and Pruitt (2002: 527) conducted an interesting analysis focused on victimology and the feelings of safety that those interviewed have when alone in their neighborhoods at night. The results indicate that a comparison between neighborhood integration with the perceived disorder, routine activities, socio-demographics, and victimization reveals that disorder, income, and crime prevention have the most substantial impact on fear of crime and perceived risk. Interestingly, integration variables appear to be relatively insignificant. In 2011, Brunton-Smith and Sturgis (2011) presented a similar empirical study stating similar premises; that is, structural characteristics, visual signs of disorder, recorded crime, and socioeconomic characteristics are all relevant to people's perception of criminality.
Substance misuse—the seventh risk-need factor—is examined in relation to challenges arising from drug use, excluding tobacco. While historical usage is considered less relevant, current issues associated with substance misuse are regarded as significantly more important (Sorge et al., 2022). Saladino et al. (2021), in "The Vicious Cycle: Problematic Family Relations, Substance Abuse, and Crime in Adolescence," provided a substantial review on the topic. Following the analysis of several articles, the conclusions suggested in this article indicate that adolescents with absent, justice-involved parents often perceive lower family cohesion and support, leading to poor communication. These factors, as maintained by the authors, can elevate risks of criminal behavior and substance abuse, driven by unease and a search for autonomy.
Finally, leisure and recreational activities are evaluated by exploring the extent to which an individual participates in and enjoys prosocial pursuits, with the lack of engagement in such activities recognized as a risk factor.
In summary, the earlier remarks about the eight risk-need factors used by risk-need assessment tools should not suggest the end of the many discussions that this topic deserves. Instead, the aim was simply to illustrate their relationship to the ongoing challenges faced by the judicial system daily, most, if not all of them, being impacted by environmental aspects.
### a) Example of a Reinforcing Cycle of Algorithmic Scores
Consider an individual recently released from incarceration who seeks employment and stable housing to reintegrate into society. Such an individual might be avoiding, for example, past associates viewed by the justice system as procriminal or seeking a neighborhood where typical activities are not perceived as 'bad' by algorithms assessing societal integration. Many employers and landlords rely on background checks and credit scores when making hiring and leasing decisions. A low credit score—potentially influenced by financial instability during incarceration—may reduce this individual's chances of securing a well- paying job or qualifying for a lease in a better neighborhood. Simultaneously, this individual's criminal record further limits these opportunities, as many financial institutions, landlords, and employers conduct background evaluations in their decision-making.
Because financial risk-scoring algorithms (e.g., FICO) incorporate variables such as employment history, outstanding debts, and repayment patterns, prolonged unemployment and limited access to financial services further diminish their creditworthiness. A low score may restrict access to credit, preventing them from obtaining a loan to move into a new neighborhood with better job opportunities, schools, and social networks. Conversely, living in an economically disadvantaged area, where crime rates may be statistically higher, could negatively affect criminal risk assessments (e.g., COMPAS), as these algorithms often factor in environmental risk elements in their calculations.
Moreover, many pretrial and probation decisions rely on algorithmic assessments to determine supervision levels, bail conditions, and the likelihood of recidivism. If an individual has a low financial score, this may indicate instability, which could consequently be interpreted as a higher risk of failing to appear in court or reoffending. Similarly, a high-risk score in criminal assessments can lead to stricter conditions for parole or probation, making it more challenging to maintain steady employment, ultimately contributing to financial instability.
This interplay of algorithmic assessments creates a self-perpetuating loop: financial hardship leads to poor housing conditions and limited employment, which results in unfavorable risk evaluations in both financial and criminal areas. These scores, in turn, restrict access to the very resources needed to improve one's situation, disproportionately impacting already marginalized individuals. The result is not only personal hardship but also broader social consequences, as algorithmic biases reinforce systemic inequities, making social mobility increasingly difficult for those trapped in this cycle.
In summary, by examining these feedback loops, this research highlights the urgent need for transparency and reform in algorithmic decision-making to prevent these systems from amplifying economic and social disparities.
## III. CRITICISM AND INTERSECTIONS
### a) Racial-based Criticism
An important part of this article lies in the fact that, although eventual categories are not textually present when assessing individuals, they may be indirectly computed. The following section is presented with the sole purpose of exemplifying how categories that are sometimes even forbidden by law are indirectly – and, why not, unintentionally - taken into account.
Examples of features not explicitly present but arguably considered in the analysis include the prohibition of worsened scoring due to poverty, along with employment status that COMPAS openly factors in. Even though race may not be directly included, it is often overshadowed by other factors that suggest its influence. For instance, an analysis based solely on location could reveal a site known for a higher concentration of a specific race or ethnicity.
Alternatively, filtering the analysis based on income could indirectly position Caucasian males at the upper end of the results. Similarly, poverty and financial marginalization could face analogous challenges. Lastly, the hypothesis of this research article posits that even if the place of residence is not explicitly accounted for—an argument in itself—it appears to be inferred, ultimately leading to the previously mentioned consequences.
Despite all the previous criticism, the use of judicial algorithms like COMPAS is becoming increasingly common, promising to address human bias, resource constraints, and subjectivity in decision-making.
COMPAS, developed by Northpointe in 1998 (Northpointe Inc., 2015), assesses individuals based on factors such as criminal history, demographics, and behavior. While it excludes legally protected categories like race, a research carried out by ProPublica argues that the algorithm indirectly incorporates racial disparities. An analysis of over 7,000 arrests in Broward County, Florida, revealed significant discrepancies: Black defendants were nearly twice as likely as white defendants to be incorrectly labeled as high-risk for reoffending, whereas white defendants were more frequently mislabeled as low-risk despite reoffending.
ProPublica's findings (Angwin et al., 2016) indicate that COMPAS's accuracy for predicting recidivism within two years was $61\%$, but racial disparities remained. For example, $44.9\%$ of Black defendants labeled as high-risk did not reoffend, in contrast to $23.5\%$ of white defendants. Conversely, $47.7\%$ of white defendants designated as low-risk reoffended, compared to $28\%$ of Black defendants.
Dressel and Farid (2018: 1, 2) conducted their research using only seven features, while COMPAS employs 137. Their sample of nonexperts demonstrated results as accurate as COMPAS in predicting recidivism.
When examining fairness, their research showed similar discrepancies. Participants in their research and COMPAS "are similarly unfair to black defendants, despite the fact that race is not explicitly specified." Dressel and Farid (2018: 1, 2)
A second analysis, which included racial information to determine whether including racial data would diminish or amplify disparities, produced similar results. Essentially, including race did not significantly impact false-positive predictions.
Even though race is explicitly excluded as an input variable, COMPAS includes various socioeconomic and demographic factors that strongly correlate with racial identity, unintentionally reinforcing racial disparities. For example, the algorithm accounts for employment status, educational background, and prior arrest history—each influenced by structural inequities and historical discrimination. Moreover, place of residence, while not always a direct factor, can be inferred through related variables like employment history and past offenses, especially in regions with significant racial segregation. These correlations create a scenario where racial bias is not intentionally programmed into the model but emerges as a consequence of existing societal disparities. The consideration of socio-economic factors such as financial stability, family background, and prior interactions with law enforcement often exacerbates systemic disadvantages, particularly for historically marginalized communities. Therefore, the assertion that COMPAS is "race-neutral" ignores how algorithmic decision-making incorporates proxies for race, thus perpetuating inequities under the pretense of objectivity.
The legal and ethical implications of these findings are significant. The ongoing use of COMPAS raises urgent concerns regarding fairness in sentencing, bail decisions, and parole recommendations, especially given the algorithm's documented tendency to misclassify Black defendants as high-risk at a disproportionate rate. Legally, this challenges core principles of due process and equal protection under the law, as defendants face assessments that systematically disadvantage certain racial groups, despite the formal exclusion of race as an input. Ethically, reliance on such tools raises questions about accountability, transparency, and the legitimacy of algorithmic decision-making in judicial settings. If an algorithm perpetuates bias—even if inadvertently—should its use be reconsidered? Should there be more stringent standards for auditing and mitigating bias before deployment? These questions underscore the need for a stronger regulatory framework to ensure that predictive algorithms do not reinforce the very disparities they aim to eliminate.
b) An Intersection of Environmental Factors, Residential Location, and Criminal Risk-need Assessment Instruments
It was previously said that this paper examines the interferences and eventual existence of a feedback loop between criminal risk assessment algorithms and financial algorithms. It argues that both systems evaluate financial aspects, poverty, and place of residence—even sometimes only correlatively—in a way that reinforces negative outcomes. These elements serve as both causes and results of low scores within these algorithms, forming a self-reinforcing cycle that perpetuates low scores. The intersection of these systems reveals a troubling dynamic in which financial distress and residential instability are intensified, further pushing individuals into adverse socio-economic and judicial conditions.
Throughout history, criminological theories have tried to explain crime in various ways. Theories such as Social Class and Crime, Strain Theory, Subcultural Perspectives, Labeling and Marxist/Conflict Theories, Control Theories, and Differential Association Theory continue to be tested and refined in efforts to predict criminal activity (Bonta and Andrews, 2024: 35-42). Nevertheless, none of these theories can establish a definitive causal relationship between crime and the observable characteristics of offenders. Although these studies provide inductive strength—bringing scholars closer to useful conclusions—they do not offer absolute reasoning that is sufficient for definitive justifications. Furthermore, they are unable to identify characteristics that, through either/or reasoning, can independently result in effective crime prevention or punishment.
By analyzing whether the place of residence plays a relevant role in scoring individuals both criminally and financially, the aim is not to reach a deterministic conclusion that would establish the place of residence as a necessary, let alone sufficient, condition for poor scoring—judicially or financially. Criminal theories and their scholars have pursued this approach for decades, and the literature has shown that a causal connection between poverty and crime does not exist. Specifically, poverty, lack of opportunities, identification with subcultures, and access to mechanisms of social and financial rewards appear relevant but are not sufficient when considered in isolation, in line with Bonta and Andrews (2024) and their summarized analysis of criminological theories.
This article does not aim to reach a definitive conclusion that one's place of residence is determinative when predicting criminal behavior and an individual's financial difficulties. However, this does not stop scholars from pursuing an alternative inquiry. Specifically, if it is not determinative, is it significant at all? Moreover, to what extent does the place of residence remain relevant?
Given these disquietudes, it is important to consider the eight risk-need predictors presented by Bonta and Andrews (2024), which offer a modern framework for understanding criminological issues in risk-need assessment tools. This article's hypothesis is that they indirectly reflect the impact of financial and social conditions on criminal behavior. Furthermore, the COMPAS algorithm—of substantial social use representativeness, as seen previously—textually incorporates financial aspects and poverty into its crime predictions, highlighting the important role of economic factors in risk assessment questions.
In such a situation, it is crucial to determine whether an individual's place of residence can influence the eight risk-need factors previously outlined. Furthermore, based on this analysis's findings, a subsequent question arises: Can this hypothetical influence affect financial scoring tools?
Thus, consider the first risk-need factor: Criminal History. This factor will not be addressed right now, as it is the very question this article aims to answer. It includes all discussions about one's past, and the article plans to offer value not just from a punitive viewpoint but also from a preventive one, focusing on present and future endeavors.
The second risk-need factor is Criminal Attitudes, which reflect an individual's beliefs, values, and emotions about crime. These attitudes are shaped by the place of residence, as the surrounding environment influences values and beliefs. Although the extent to which residence contributes to shaping these attitudes is not entirely clear, it is undeniably relevant and worthy of further exploration.
The third risk-need factor to analyze is Procriminal Associates. According to Bonta and Andrews (2024), this factor is shaped by one's associations with or isolation from procriminal or prosocial individuals. Neighbors, friends, and acquaintances are often drawn from the environments where people live, work, study, or spend their leisure time. This geographic factor influences social exposure and thus significantly impacts associations.
The fourth risk-need factor, Antisocial Personality Pattern, includes traits such as impulsivity, aggressiveness, and disregard for others. These personality characteristics are influenced by one's environment, including their place of residence. If these traits are formed—or at least influenced—by learning and social interactions, it is reasonable to conclude that the environment plays a crucial role in their development.
The fifth factor, Family/Marital, pertains to the quality of interpersonal relationships. The place of residence may indirectly shape these relationships by influencing access to potential partners and the environment in which family dynamics develop. While questioning whether one's relationships would differ in another location may lead to philosophical reflections[^5], a more practical consideration is how residence impacts partnerships, parenting, and family life. Relationships are affected by the quality of one's surroundings, which, in turn, influences offspring and their development, potentially creating a feedback loop of environmental influence.
The sixth risk-need factor, School/Work, focuses on performance, engagement, and satisfaction in educational and professional environments. Residency often influences where individuals study or work, as location plays a critical role in these decisions[^6]. This means that residence impacts access to schools and job opportunities, shaping the social and professional contexts individuals encounter. These contexts, in turn, affect aspirations, perceptions of success, and overall outcomes.
The seventh factor, Substance Misuse, explores challenges related to alcohol and drug use (excluding tobacco), focusing on current use over past behavior. The environment, including where one lives, is crucial for understanding substance misuse, as it influences exposure, accessibility, and social norms surrounding these behaviors.
Finally, Leisure and Recreation assess involvement and satisfaction in prosocial recreational activities. The types of activities individuals participate in often depend on the opportunities available in their environment, such as soccer, chess clubs, boxing, and basketball at local public courts. A person's place of residence affects access to leisure activities, whether they be sports, clubs, or other recreational options. This filtering effect influences social interactions and associations, shaping the extent to which individuals connect with prosocial or procriminal peers.
A thorough review of criminological theories could help explore possible connections between the eight factors mentioned earlier and the causes of the difficulties discussed. However, the main argument remains: the environment is important. But stating that the environment matters is hardly a new idea—it's a widely accepted belief. The real question, using the transitive property of mathematics, is this: if the environment plays a clear role in understanding crime, does the place of residence influence that environment and, consequently, the occurrence of crime?
If the evidence suggests this is the case, the next question is: to what extent does it matter? More importantly, can this relevance be observed in criminal risk-need assessment scoring tools? If so, one must consider whether the place of residence is 1) relevant in this context, though only indirectly important in financial or banking scoring systems, or 2) directly significant, acting as a clear filter or category explicitly included in financial scoring systems.
### c) An Intersection of Environmental Factors, Residential Locations, and Financial Scoring Systems
While these are relevant questions related to criminal risk-need scoring systems, they are not the focus of this article. Specifically, this article aims to address whether the environment influences scoring systems, but rather whether place of residence influences both scoring systems—criminal and financial—and whether their scoring systems produce output data used by one another in a feedback loop, propelling a never-ending cycle.
The previous part was dedicated to establishing, though argumentatively, the relevance of the place of residence to a broader concept, that is, the environment. This is dedicated to evaluating if the same logic - a place of residence as a species of the environment as a genus -is relevant to financial scoring systems.
In this regard, the FICO algorithm[78]—developed by the Fair Isaac Corporation—is said to consider the client's payment history, the credit utilization ratio (which compares the total amount of credit in use to the credit limits), the age of credit accounts, the diversity of credit types—including revolving credit like credit cards and installment credit such as car loans and mortgages—and the presence of too many recently opened accounts and recent credit inquiries, among other factors.
The Equal Credit Opportunity Act (ECOA)[^9], which governs credit transactions in the U.S., prohibits discrimination based on race or color, religion, national origin, sex, marital status, age, and other factors. Although it does not specifically address discrimination based on place of residence, it can still be considered, albeit subtly.
Some situations where place of residence is relevant include: 1) analyzing neighborhood metrics, such as average income levels, property values, or economic stability in the area where a customer lives; 2) fraud prevention by examining changes in residence that may indicate potential financial instability or fraud; 3) assessing loan pricing and offers, where the environment can represent higher perceived risks, ultimately raising prices; 4) negotiating insurance, where location naturally plays a significant role. In these situations, environment, addresses, and place of residence are once again established as relevant features when scoring individuals, this time in a financial context.
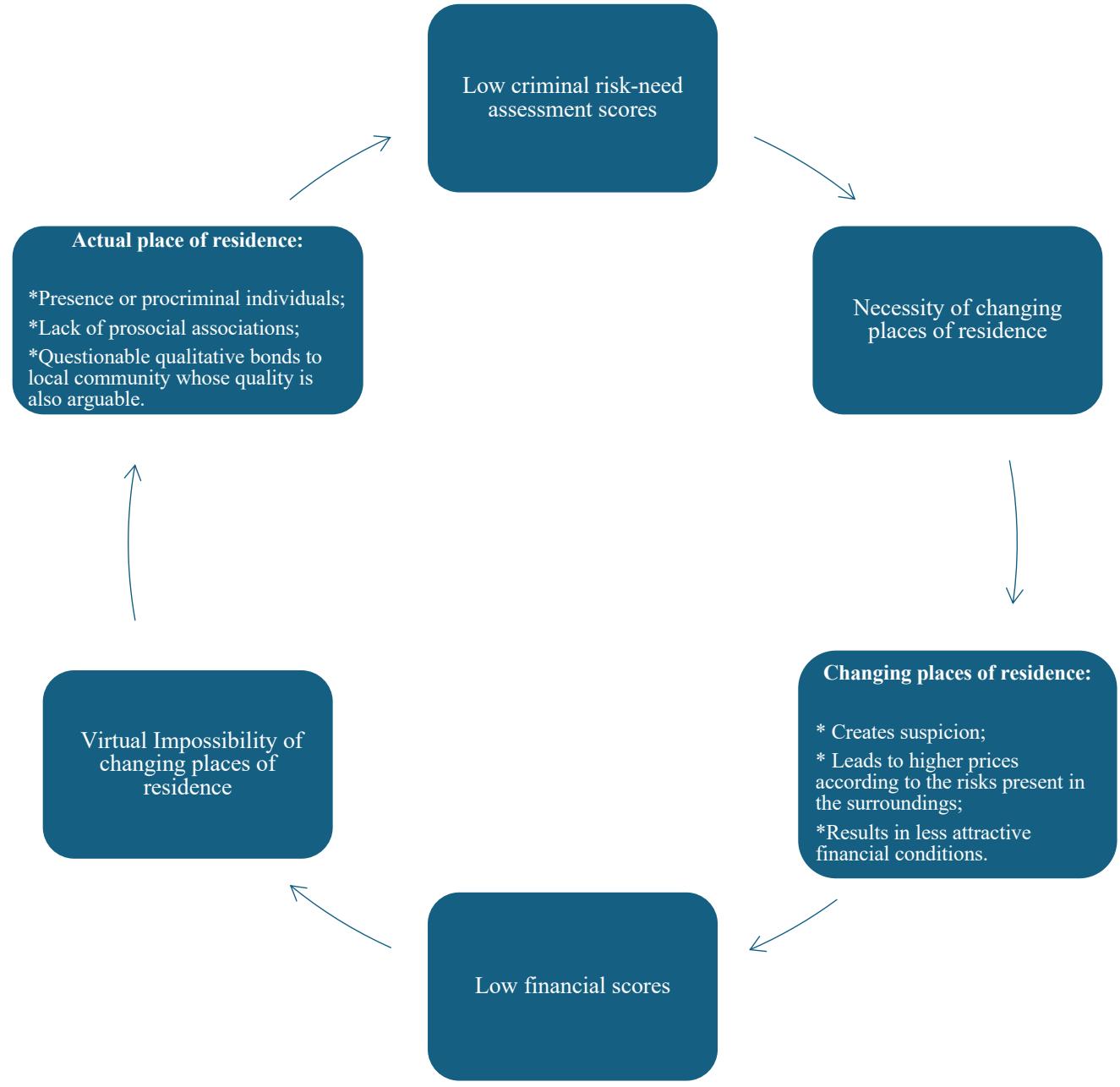
The diagram below illustrates the discussion of this article and summarizes it.
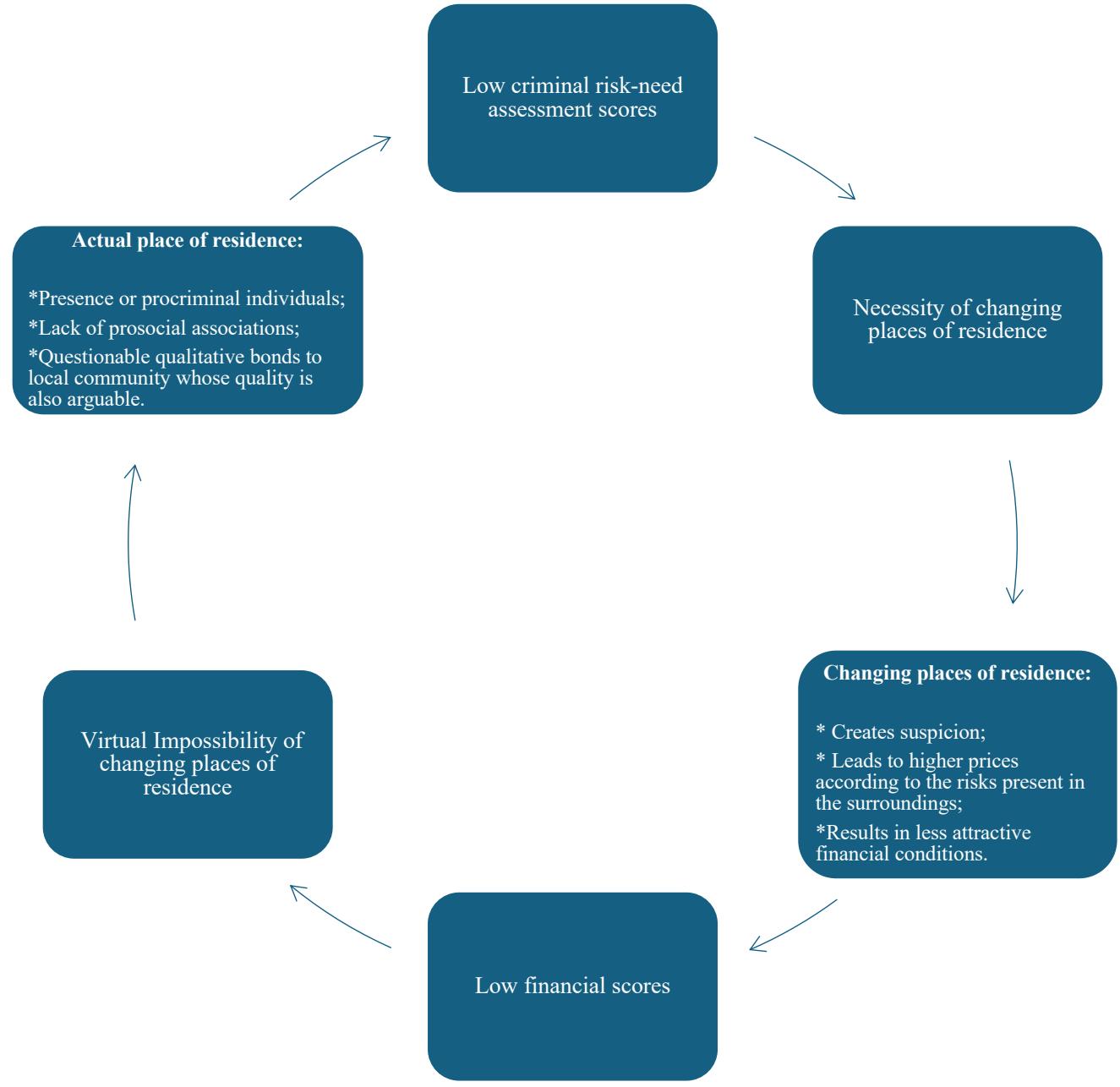 Figure 1
The diagram above encapsulates the main argument of the article, illustrating the feedback loop between criminal risk-need assessment algorithms and financial scoring systems. It visually represents how socio-economic factors—such as poverty, residential location, and financial instability—are assessed by both systems, perpetuating a cycle of disadvantage. The diagram highlights that low financial scores, derived from metrics such as credit history and payment capacity (like FICO), influence criminal risk-need assessments by amplifying perceived criminogenic factors such as social environment and their consequential associates, including place of residence, school, and workplace environments. Conversely, outputs from criminal risk tools like COMPAS may further lower financial scores by embedding judicial requirements—changing addresses, for example—into socio-economic evaluations.
Therefore, this diagram serves as an objective synthesis of the article's argument, clearly representing the feedback loop's mechanisms and implications.
## IV. CONCLUSIONS
This article examines the interconnectedness of criminal risk-need assessment algorithms and financial scoring systems, arguing that these tools operate within a feedback loop that worsens systemic disadvantages. Through a theoretical analysis grounded in criminological theories, evidentiary standards, and algorithmic design principles, this study demonstrates how socio-economic factors—such as place of residence, financial instability, and resource accessibility—play a crucial role in shaping algorithmic outcomes. While these variables are not always explicitly included in assessments, they influence both criminal and financial risk scores, reinforcing existing inequities rather than mitigating them.
Although this study is theoretical in nature, it provides a necessary foundation for future empirical research. One of the most pressing next steps is to verify the extent to which criminal and financial algorithms reinforce one another through systematic data analysis. Future studies could employ case studies, statistical modeling, or large-scale data analyses to measure the degree of correlation between an individual's COMPAS score and their financial credit rating over time. Additionally, research could explore how specific algorithmic inputs, such as employment status or prior offenses, disproportionately affect financially marginalized communities.
Given the increasing reliance on algorithmic decision-making, these findings raise critical concerns about fairness, transparency, and accountability. Policymakers and regulatory bodies should consider mandatory audits of these algorithms to identify biases and implement safeguards that prevent their unintended consequences. Furthermore, there is a need to reevaluate the evidentiary standards embedded in these tools, ensuring that algorithmic predictions do not replace human oversight in decisions with life-altering consequences. The financial and criminal justice sectors must critically examine their dependence on automated assessments, particularly when they systematically disadvantage already vulnerable populations.
Ultimately, while algorithmic assessments are often framed as neutral and objective, this study has shown that they incorporate socio-economic biases in ways that demand greater scrutiny. Ignoring these issues risks perpetuating cycles of disadvantage, increasing financial marginalization, and worsening inequities within the criminal justice system. Addressing these challenges requires a multifaceted approach—one that combines theoretical critique with empirical validation, policy reform, and ethical scrutiny of algorithmic decision-making.
[^1]: In general terms, an objective probability quantifies the frequency with which a particular event occurs within a specified sequence of events, approaching an infinite limit. _(p.4)_
[^4]: Here, once again, while the aforementioned literature emphasizes judicial elements, the reasons that lead scholars to discourage the use of statistical evidence in judicial contexts could easily be applied here, namely sociological perspectives. Specifically, the criticism revolves around whether statistics should be used to determine something as proven or not; the nature of the premises—be they judicial, sociological, political, psychological, or even biological—is irrelevant. _(p.6)_
[^5]: Questioning whether one's place of residence had been different may imply that one's family members would also have been different; thus, while provoking thought, these reflections could lead to the dilemma of eternal recurrence and its associated difficulties. For example, if my parents had been raised at a different place of residence, would they have had different personalities, traits, and aspirations, and therefore be different parents themselves? _(p.10)_
[^6]: There is a logical assumption that, all else being equal, few would choose to study or work farther from home when local options are available. _(p.10)_
[^9]: For additional information, refer to https://www.fdic.gov/system/files/2024-06/v-7-1.pdf _(p.11)_
Generating HTML Viewer...
References
31 Cites in Article
Stefanía Ægisdóttir,Michael White,Paul Spengler,Alan Maugherman,Linda Anderson,Robert Cook,Cassandra Nichols,Georgios Lampropoulos,Blain Walker,Genna Cohen,Jeffrey Rush (2006). The Meta-Analysis of Clinical Judgment Project: Fifty-Six Years of Accumulated Research on Clinical Versus Statistical Prediction.
D Andrews,C Dowden (2008). The risk-needresponsivity model of assessment and human service in prevention and corrections: Crimeprevention jurisprudence.
Julia Angwin,Jeff Larson,Surya Mattu,Lauren Kirchner (2016). Machine Bias *.
V Barnett (1973). Comparative Statistical Inference.
I Brunton-Smith,P Sturgis (2011). Do neighborhoods generate fear of crime? An empirical test using the British Crime Survey.
J Bonta,D Andrews (2024). Psychology of Criminal Conduct.
R Carnap (1950). Logical Foundations of Probability.
J Dressel,H Farid (2018). The accuracy, fairness, and limits of predicting recidivism.
M Etienne (2009). Legal and practical implications of evidence-based sentencing by judges.
J Ferrer Beltrán (2007). La valoración racional de la prueba.
J Ferrer Beltrán (2021). Prueba sin convicción.
I Good (1983). Good Thinking: The Foundations of Probability and its Applications.
Kelly Hannah-Moffat (2005). Criminogenic needs and the transformative risk subject.
K Hannah-Moffat (2013). Actuarial sentencing: An "unsettled" proposition.
K Heilbrun (2009). Risk assessment in evidencebased sentencing context and promising uses.
J Kanan,M Pruitt (2002). Modeling fear of crime and perceived victimization risk: The (in) significance of neighborhood integration.
D Kaye (1988). Introduction. What is Bayesianism.
L Laudan (2016). The Law's Flaws. Rethinking Trial and Errors? Milton Keynes.
Jennifer Logg,Julia Minson,Don Moore (2019). Algorithm appreciation: People prefer algorithmic to human judgment.
D Mackenzie (2001). Corrections and sentencing in the 21st century: Evidence-based corrections and sentencing.
J Mackie (1973). Truth, Probability and Paradox: Studies in Philosophical Logic.
M Marcus (2009). MPC-The root of the problem: Just deserts and risk assessment.
M Marcus (2009). Conversations on evidencebased sentencing.
B Dietvorst,J Simmons,C Massey (2015). Algorithm aversion: people erroneously avoid algorithms after seeing them err.
(2015). Practitioner's guide to COMPAS core.
Valeria Saladino,Oriana Mosca,Filippo Petruccelli,Lilli Hoelzlhammer,Marco Lauriola,Valeria Verrastro,Cristina Cabras (2021). The Vicious Cycle: Problematic Family Relations, Substance Abuse, and Crime in Adolescence: A Narrative Review.
Marco Santos (2024). The Lack of Evidentiary Standards to Define “Sufficient Evidence of Authorship” in Pretrial Detentions in Brazil: The Jurisprudence of the Brazilian Constitutional Court.
L Savage (1954). The Foundations of Statistics.
A Sorge,G Borrelli,E Saita,R Perrella (2022). Violence Risk Assessment and Risk Management: Case-Study of Filicide in an Italian Woman.
R Warren (2007). Evidence-Based Public Policy Options to Reduce Future Prison Construction, Criminal Justice Costs, and Crime Rates.
M Wolfe (2008). Evidence-based judicial discretion: Promoting public safety through state sentencing reform.
No ethics committee approval was required for this article type.
Data Availability
Not applicable for this article.
How to Cite This Article
Marco Tulio Ferreira dos Santos. 2026. \u201cAlgorithmic Bias and Place of Residence: Feedback Loops in Financial and Risk Assessment Tools\u201d. Global Journal of Human-Social Science - F: Political Science GJHSS-F Volume 25 (GJHSS Volume 25 Issue F1): .
Explore published articles in an immersive Augmented Reality environment. Our platform converts research papers into interactive 3D books, allowing readers to view and interact with content using AR and VR compatible devices.
Your published article is automatically converted into a realistic 3D book. Flip through pages and read research papers in a more engaging and interactive format.
This article explores how criminal risk-need assessment algorithms (e.g., COMPAS) and financial scoring systems (e.g., FICO) create feedback loops that perpetuate systemic biases, disproportionately affecting already financially marginalized groups. It examines the intersection of these tools, particularly how factors like place of residence, financial instability, and access to resources influence both systems. Using a theoretical critique, this study indirectly analyzes (1) criminological theories, (2) algorithmic design principles, and (3) evidentiary standards. The criminological theories considered-including Social Class and Crime, Strain Theory, Subcultural Perspectives, Labeling and Marxist/ Conflict Theories, Control Theories, and Differential Association Theory-share a consensus that environmental factors contribute to crime. While this research does not aim to verify their conclusions, it investigates how algorithmic models incorporate personal financial data and place of residence. It also examines the relevance of these to observing non-virtuous behaviors, as supported by the previously mentioned criminological theories, although the findings of these theories may differ regarding the levels of relevance of the environment to criminal occurrences. Additionally, evidentiary standards and numerical reasoning help assess how these inputs shape potentially biased and unfair scores.
Our website is actively being updated, and changes may occur frequently. Please clear your browser cache if needed. For feedback or error reporting, please email [email protected]
Thank you for connecting with us. We will respond to you shortly.