Hadoop big data platform is designed to process large volume of data. Small file problem is a performance bottleneck in Hadoop processing. Small files lower than the block size of Hadoop creates huge storage overhead at Namenode’s and also wastes computational resources due to spawning of many map tasks. Various solutions like merging small files, mapping multiple map threads to same java virtual machine instance etc have been proposed to solve the small file problems in Hadoop. This survey does a critical analysis of existing works addressing small file problems in Hadoop and its variant platforms like Spark. The aim is to understand their effectiveness in reducing the storage/computational overhead and identify the open issues for further research.
## I. INTRODUCTION
Hadoop is an open source big data processing platform designed to process large volume of data. The data is kept in form of files in Hadoop distributed file system (HDFS). A map job is spawned on a java virtual machine (JVM) instance for each file in HDFS. The file data is copied to a memory block and the block is passed to map task. In addition, a object instance is created for each file in the Namenode of Hadoop to facilitate processing. When the file size is more than or equal to block size, maximum performance gain in achieved in terms of number of maps spawned and the meta data storage overhead at Namenode. In case of IoT applications, the data files are small (less than 2KB) and when these files are stored in HDFS for data processing, it affects the Hadoop performance [1-2]. On one hand, it drastically increases the storage overhead at Namenode for object bookkeeping [3]. On another hand it exhausts the computational resources by spawning multiple map tasks which only lasts for smaller duration to process small files. The time spent in bootstrapping the map task becomes higher than data processing time in case of small files. Various solutions have been proposed addressing the Hadoop small file problem. The existing solutions can be categorized as: (i) file merging solutions, (ii) file caching solutions, (iii) optimizing Hadoop cluster structure and (iv) Map task optimizations. In file merging solutions, pre-treatment of small files is done to form a big file and this big file is stored in HDFS. In file caching solutions, files are sent to a file queue, and when queue size crosses threshold files are sent to processing in a systematic manner. In Hadoop cluster structure optimization solutions, hierarchical memory structure is created combining cache and HDFS memory to reduce the overhead due to single name node. In map task optimization solution, number of JVM instances spawned for map tasks are reduced and shared.
This work does a critical analysis on various solutions in the above four categories of file merging, file caching, Hadoop cluster structure optimization and map task optimization. The effectiveness of each of the solutions in terms of storage and computation are analyzed and their open issues are identified. Based on the open issues, a prospective solution framework is designed and detailed.
## II. SURVEY
Ahad et al [4] proposed a dynamic merging strategy based on the file type for Hadoop. Dynamic variable size portioning is applied to blocks and the file contents are fitted to blocks using next fit allocation policy. By this way large file is created and saved to HDFS. In addition, authors also secured the block using Twofish cryptographic technique. The solution reduced name node memory, number of data blocks and processing time. Merging was done only based on file types without considering the context and their semantic relation. Siddiqui et al [5] proposed a cache based block management technique for Hadoop as a replacement for default Hadoop Archives (HAR). A logical chain of small files is built and transferred to data blocks. In addition, efficient read/write on blocks was facilitated using block manager. Though the solution achieved more than $92\%$ space utilization of data blocks, small files are merged only based on size, without considering the semantic relations and content characteristics. Zhai et al [6] built a index based archive file to solve the small file problem in Hadoop. The small files are merged to large file and metadata record is created to retrieve each file content. Meta data records are arranged into buckets. An order preserving hash is created over metadata records. The hash and the metadata records are in turn written to a index file. The index files helps to retrieve the file contents for processing. This method is able to save at least $11\%$ disk space but the solution access efficiency becomes lower with large number of small files. Also the indexing does not support streaming inputs. Cai et al [7] proposed a file merging algorithm based on two factors of distribution of the files and the correlation of the file. Correlation between files is built based on their history of access and the highly correlated files are kept in the same block. Through experiments, author found that placing highly correlated files in same block improved the speed up. The correlation is not based on content characteristics so over a period of time, performance can reduce. Choi et al [8] integrated combined file input format and JVM reuse to solve the small file problem. Small files are combined till block size and passed to map task. JVM instances are reused for the map task, so they overhead of JVM bootstrap is minimized. Though the integration reduces the computational overhead, the approach combined files in order without considering their semantics. Also the memory buildup due to JVM reuse can crash the tasks due to inefficient memory management. Peng et al [9] combined merging and caching techniques to solve the small file problem. User based collaborative filtering is applied to learn the correlation between the files. Files with higher correlation are merged into single large file. Remote procedure call (RPC) requests to fetch the block information about the files are reduced by caching the access requests and looking into cache for the blocks before placing RPC requests. By this way, authors were able to reduce the file access time by $50\%$ and increase storage utilization by $25\%$ compared to default Hadoop. The scheme does not works well for streaming data, as the correlation model proposed in this work is not adaptive to streaming data. Niazi et al [10] proposed a new technique called inode stuffing to solve the small file problem. For small files, the metadata and data block are combined and decoupling is maintained only for large files. The approach is not scalable as it increases the metadata storage overhead at Namenodes. Jing et al [11] proposed a dynamic queue method to solve the small file problem. The files are first classified using the period classification algorithm. The algorithm calculates similarity score based on sentence similarity between two documents. The similar files are then merged to large file using multiple queues for specific file sizes. Authors also used file pre-fetching strategy to improve the efficiency of file access. Analyzing similarity between pairs is a cumbersome task for large number of files. Sharma et al [12] proposed a dual merge technique called Hash Based-Extended Hadoop Archive to solve the small file problem in Hadoop. The small files are merged using two level compaction. This reduces the storage overhead at Namenode and increase the data block space utilization at Datanodes. File access is made efficient using two level hash function. The proposed solution is at least $13\%$ faster compared to default Hadoop. The files were merged without considering the content characteristics and their semantics. Wang et al [13] combined merging and caching to solve the small file problem in Hadoop. Authors proposed a equilibrium merger queue algorithm to merge small files to Hadoop block size and then merged file is saved to HDFS. Indexing is built to access small files. To reduce the communication overhead between the client and Namenode for small file access, pre-fetched cache is used. With the cache, the number of RPC calls to name node is reduced. The memory consumption at Namenode drastically reduced in the proposed solution compared to default Hadoop Archives. Contents were merged without considering their content characteristics and semantic correlation. Ali et al [14] proposed a enhanced best fit merging algorithm to merge small files based on type and size. The merging is done till Hadoop block size is reached and merged file is saved to HDFS. Author found that merging improved Hadoop storage utilization by $64\%$ but the file access time was higher in this work. Prasanna et al [15] compressed many small files into a zip file to the size of Hadoop data block and saved to disk. This increased the disk utilization of data nodes and name nodes. But the computational overhead in compressing stage and decompressing during processing is higher. Huang et al [16] addressed the small file problem for the case of images in Hadoop. A two level model was proposed specific to medical images. The images were grouped at first level based on series and next level based on examination. The grouped images are saved to data blocks in HDFS. Indexing and pre-fetching is done to done is reduce the access time for small image files. The pre-fetching algorithm did not have higher cache hit. Renner et al [17] extended the Hadoop archive to appendable file format to solve the small file problem. Small files are appended to existing archive data files whose block size is not completely used. Authors used first fit algorithm to select the data blocks. In addition indexing is done to facilitate faster access. Red black tree structure is used for indexing for efficient lookup. Though this scheme improved the data block utilization, appending is done without considering content characteristics and semantic similarity. Liu et al [18] proposed a file merging strategy based on content similarity. Files are converted to vector space features and correlation between the features is measured using cosine similarity. When cosine similarity is greater than threshold, files are merged. In addition authors used pre-fetching and caching to speed up the file access. Constructing a global feature space for streaming data is difficult and thus this approach is not suitable for streaming data.Lyu et al [19] proposed an optimized merging strategy to solve small file problem. The small files are merged based on size in such that way block size is fully utilized. In addition authors used pre-fetching and caching to increase the access speed. Only block size utilization was considered as the only criteria for merging without considering content characteristics and semantic relations. Similar to it Mu et al [20] proposed an optimization strategy to maximally fill the existing Hadoop archive by appending small files. In addition author also used secondary index to speed up the execution of file access. But here too merging was done without considering content characteristics and semantic relation. Wang et al [21] used probabilistic latent semantic analysis to determine the user access pattern and based on it small files are merged to a large file and placed in HDFS. In addition author also improved the pre-fetching hit ratio based user access transition pattern. Both the strategies improvised the speed of access and data block utilization. But this scheme is not suitable for multi user environment as for each user, a merging order must be kept and this increases the storage overhead. He et al [22] merging
the small files based on balance of data blocks. The aim was to increase the data block utilization. Merging did not consider content characteristics and their semantic relation. Fu et al [23] proposed an flat storage architecture to handle the small files. In this scheme, both files and meta data are collocated with meta size fixed for any number of small files. This is facilitates by meta data having only pointer to related information in its index. But the scheme is not suited for Hadoop as collocation causes higher access overhead for large files. Tao et al [24] merged small files to large file and built a linear hash to small files to speed up access. File size was the only criteria considered for merging. Bok et al [25] integrated file merging and caching to solve the small file problem. Author used two level of cache for small files, so that access requests to -
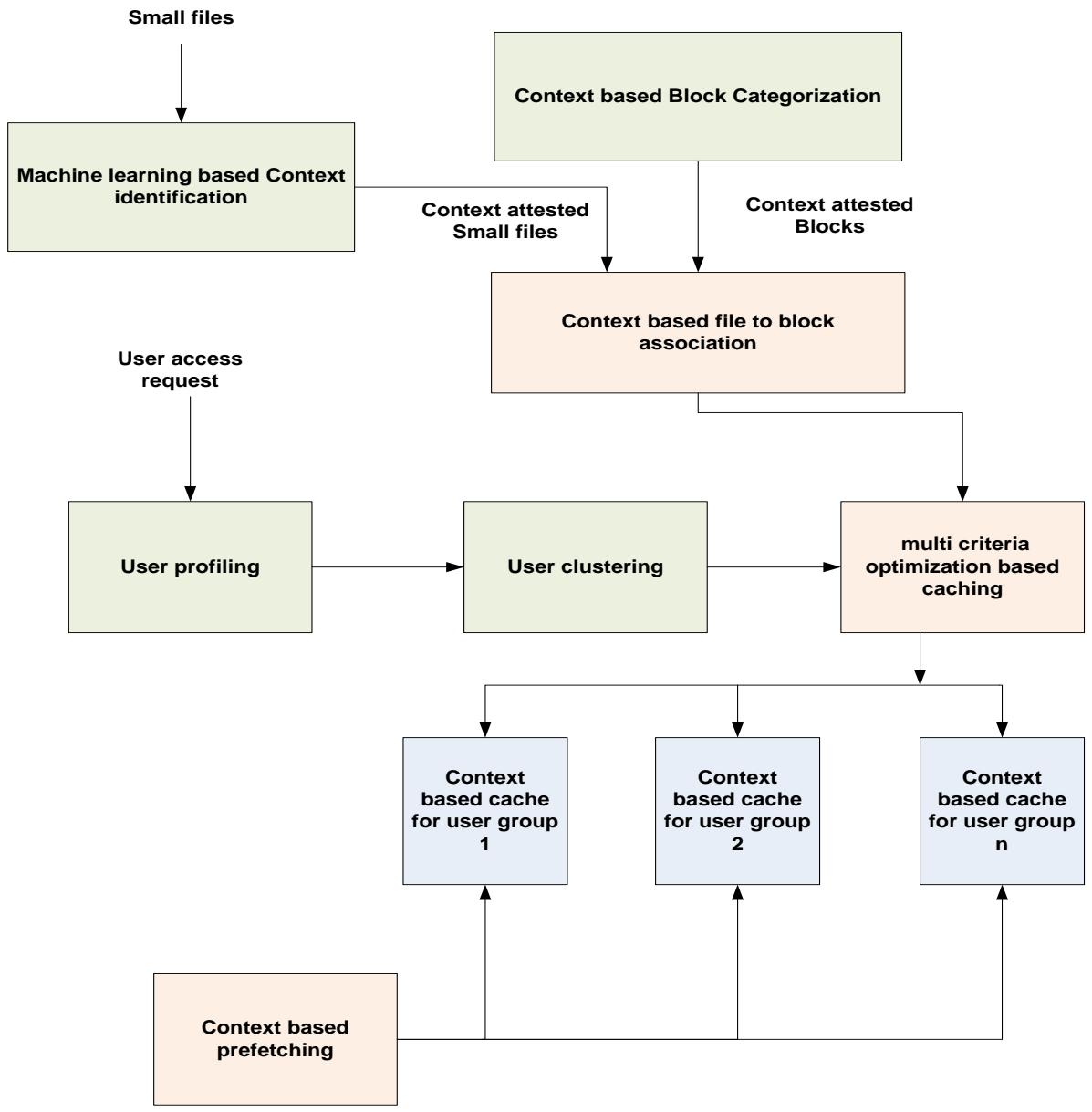
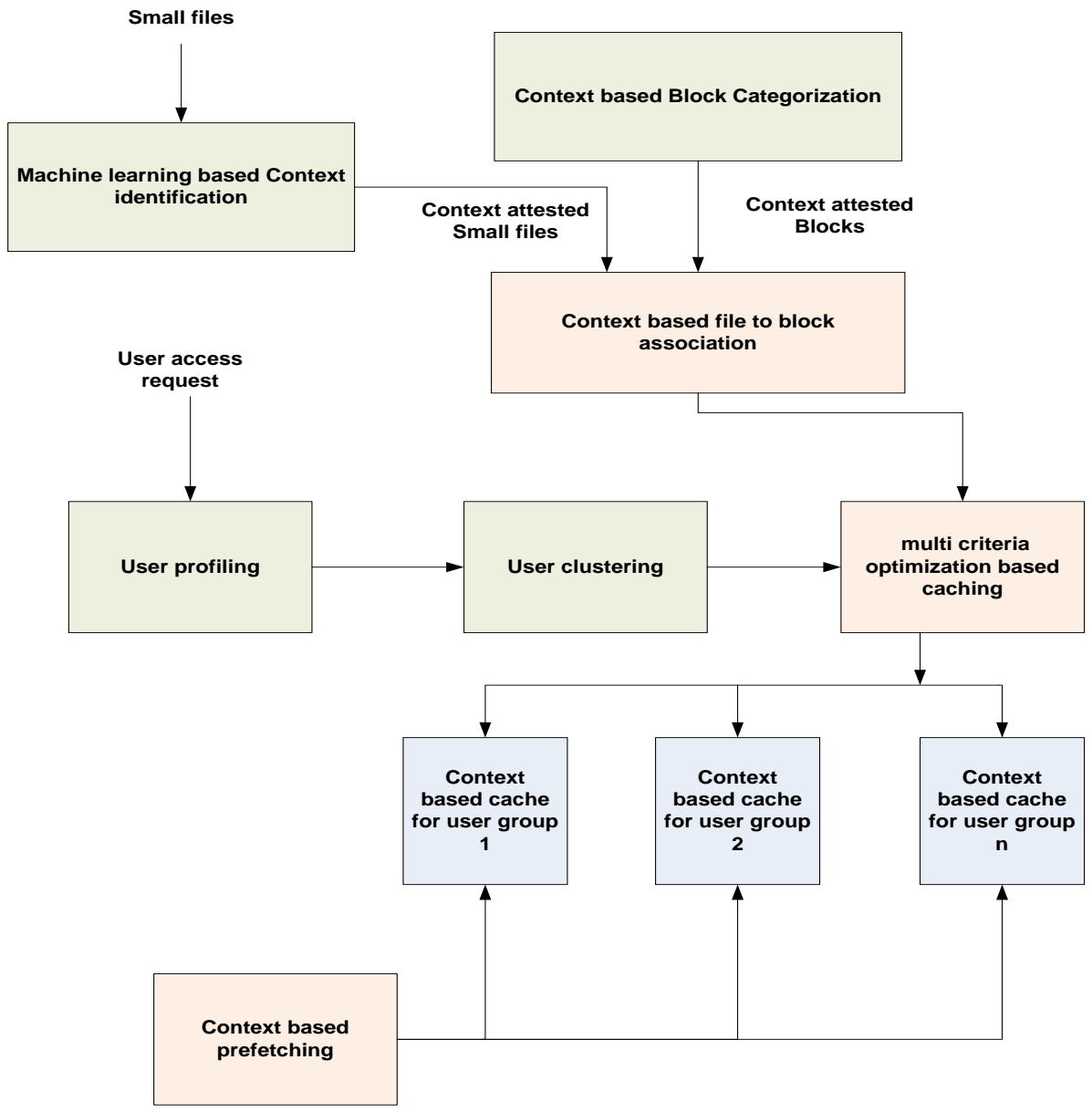 Figure 1: Research direction framework
Table 1: Survey Summary
<table><tr><td>Work</td><td>Solution for Small file Problem</td><td>Gap</td></tr><tr><td>Ahad et al [4]</td><td>dynamic merging strategy based on the file type</td><td>Merging was done only based on file types without considering the context and their semantic relation</td></tr><tr><td>Siddiqui et al [5]</td><td>cache based block management technique</td><td>small files are merged only based on size, without considering the semantic relations and content characteristics</td></tr><tr><td>Zhai et al [6]</td><td>a index based archive file with order preserving hash for speedup</td><td>Does not support streaming</td></tr><tr><td>Cai et al [7]</td><td>file merging algorithm based on two factors of distribution of the files and the correlation of the file</td><td>The correlation is not based on content characteristics</td></tr><tr><td>Choi et al [8]</td><td>integrated combinedfileinputformat and JVM reuse to solve the small file problem</td><td>memory buildup due to JVM reuse can crash the tasks due to inefficient memory management</td></tr><tr><td>Peng et al [9]</td><td>combined merging and caching techniques to solve the small file problem</td><td>The scheme does not works well for streaming data, as the correlation model proposed in this work is not adaptive to streaming data</td></tr><tr><td>Niazi et al [10]</td><td>Coupling both meta data and small file together.</td><td>The approach is not scalable as it increases the metadata storage overhead at Namenodes</td></tr><tr><td>Jing et al [11]</td><td>Files classified using the period classification algorithm and merged based on similarity</td><td>Analyzing similarity between pairs is a cumbersome task for large number of files</td></tr><tr><td>Sharma et al [12]</td><td>Hash Based-Extended Hadoop Archive to solve the small file problem</td><td>The files were merged without considering the content characteristics and their semantics.</td></tr><tr><td>Wang et al [13]</td><td>combined merging and caching to solve the small file problem</td><td>Contents were merged without considering their content characteristics and semantic correlation</td></tr><tr><td>Ali et al [14]</td><td>enhanced best fit merging algorithm to merge small files based on type and size.</td><td>file access time was higher in this work</td></tr><tr><td>Huang et al [16]</td><td>A two level model was proposed specific to medical images</td><td>The pre-fetching algorithm did not have higher cache hit</td></tr><tr><td>Renner et al [17]</td><td>Small files are appended to existing archive data files</td><td>Appending is done without considering content characteristics and semantic similarity</td></tr><tr><td>Liu et al [18]</td><td>File content based merging</td><td>Constructing a global feature space for streaming data is difficult and thus this approach is not suitable for streaming data</td></tr><tr><td>Lyu et al [19]</td><td>optimized merging strategy to solve small file problem.</td><td>Only block size utilization was considered as the only criteria for merging without considering content characteristics and semantic relations</td></tr><tr><td>Wang et al [21]</td><td>probabilistic latent semantic analysis to determine the user access pattern and based on it small files are merged to a large file</td><td>scheme is not suitable for multi user environment as for each user, a merging order must be kept and this increases the storage overhead</td></tr><tr><td>He et al [22]</td><td>merging the small files based on balance of data blocks</td><td>Merging did not consider content characteristics and their semantic relation</td></tr><tr><td>Fu et al [23]</td><td>flat storage architecture collocating metadata and file in same object</td><td>the scheme is not suited for Hadoop as collocation causes higher access overhead for large files</td></tr><tr><td>Tao et al [24]</td><td>merged small files to large file and built a linear hash to small files to speed up access</td><td>File size was the only criteria considered for merging</td></tr><tr><td>Bok et al [25]</td><td>integrated file merging and caching to solve the small file problem</td><td>The merging was based only on size without considering the content characteristics and semantic similarity</td></tr></table>
Namenode is totally minimized. Least recently used (LRU) mechanism is used to upgrade the cache. The merging was based only on size without considering the content characteristics and semantic similarity.
The summary of survey so far discussed is presented in Table 1.
## III. OPEN ISSUES
From the survey, following three open issues are identified.
1. Context specific merging
2. Personalized access
3. Streaming support
Context specific merging: In most of the existing approaches, merging was based only on size. Merging did not consider user access or application contexts, content characteristics and their semantic relation. In applications like recommendations based on user comments, it is necessary to co-locate user comments related to specific product characteristics in same blocks for application speedup.
Personalized Access: In most of the existing caching strategies, caching was based on least recently used at a global context without considering the user access context. But it is important to consider user access context as each user access behavior is different. Caching on global context can provide better performance for some users and can give worst performance for other users. To solve this access time discrepancy among the users, personalized caching strategy must be employed.
Steaming Support: Most of the merging schemes does not handle the steaming data effectively. Streaming data content similarity cannot be computed effectively using vector space modeling and their merging can become ineffective. Merging based on streaming arrival patterns has not been considered in earlier works.
## IV. RESEARCH DIRECTIONS
Based on the open issues identified, a prospective framework for further research is presented in Figure 1.
The framework addresses three problem areas of context specific merging, personalized access and streaming support.
Context Specific Merging: It can be facilitated and made adaptive using machine learning. Based on the application contexts and inherent data characteristics the files to be merged can be found. Blocks can be categorized based on context and small files can be categorized based on context. Context based merging is the realized to merge files and blocks based on context similarity. Instead of flat context, hierarchical context can be learnt automatically from file summmarization. File summarization strategies specific to file types can be proposed to identify the context to be associated with files and blocks.
Personalized Access: User can be clustered based on their content access patterns over a temporal duration and multiple caches can be maintained for each user group. Also the cache item management can be based on multi criteria optimization instead of LRU mechanisms. The items to pre-drop can be identified based on context associated with files. By this way access speed up can be increased and optimized specific to each user group.
Streaming Support: To support streaming data, the context must be learnt dynamically in a light weight manner and association of small file to blocks must be done based on context. To learn context in a light weight manner, the streaming data characteristics and their arrival patterns must be used.
## V. CONCLUSION
This survey made a critical analysis of existing solutions for small file problems in Hadoop. The solutions were analyzed in four categories of file merging solutions, file caching solutions, optimizing Hadoop cluster structure and Map task optimizations. Based on the survey, three open issues of context specific merging, personalized access and streaming support are identified. Prospective solutions to these three open issues were identified and a solution roadmap for further exploration in this area was documented.
Generating HTML Viewer...
References
24 Cites in Article
Tharwat El-Sayed,Mohammed Badawy,Ayman El-Sayed (2018). SFSAN Approach for Solving the Problem of Small Files in Hadoop.
Bo Dong,Qinghua Zheng,Feng Tian,Kuo-Ming Chao,Rui Ma,Rachid Anane (2012). An optimized approach for storing and accessing small files on cloud storage.
Mohd Ahad,Ranjit Biswas (2018). Dynamic Merging based Small File Storage (DM-SFS) Architecture for Efficiently Storing Small Size Files in Hadoop.
Isma Siddiqui,Nawab Qureshi,Bhawani Chowdhry,Muhammad Uqaili (2020). Pseudo-Cache-Based IoT Small Files Management Framework in HDFS Cluster.
Yanlong Zhai,Jude Tchaye-Kondi,Kwei-Jay & Lin,Zhu,& Liehuang,Tao,& Wenjun,Du,& Xiaojiang,Mohsen Guizani (2021). Hadoop Perfect File: A fast and memory-efficient metadata access archive file to face small files problem in HDFS.
Xun Cai,Cai Chen,Yi Liang (2018). An optimization strategy of massive small files storage based on HDFS.
Chang Choi,Chulwoong Choi,Junho Choi,Pankoo Kim (2018). Improved performance optimization for massive small files in cloud computing environment.
Jian-Feng Peng,Wen-Guo Wei,Hui-Min Zhao,Qing-Yun Dai,Gui-Yuan Xie,Jun Cai,Ke-Jing He (2018). Hadoop Massive Small File Merging Technology Based on Visiting Hot-Spot and Associated File Optimization.
Weipeng Jing,Danyu Tong,Guangsheng Chen,Chuanyu Zhao,Liangkuan Zhu (2018). An optimized method of HDFS for massive small files storage.
Vijay Sharma,Asyraf Afthanorhan,Nemi Barwar,Satyendra Singh,Hasmat Malik (2022). A Dynamic Repository Approach for Small File Management With Fast Access Time on Hadoop Cluster: Hash Based Extended Hadoop Archive.
Kun Wang,Yang Yang,Xuesong Qiu,Zhipeng Gao (2017). MOSM: An approach for efficient storing massive small files on Hadoop.
Adnan Ali,Nada Masood Mirza,Mohamad Khairi Ishak (2023). Enhanced Best Fit Algorithm for Merging Small Files.
L Prasanna,Kumar (2016). Optimization Scheme for Storing and Accessing Huge Number of Small Files on HADOOP Distributed File System.
Xin Huang,Wenlong Yi,Jiwei Wang,Zhijian Xu (2021). Hadoop-Based Medical Image Storage and Access Method for Examination Series.
Thomas Renner,Johannes Müller,Lauritz Thamsen,Odej Kao (2017). Addressing Hadoop's Small File Problem With an Appendable Archive File Format.
Jun Liu (2019). Storage-Optimization Method for Massive Small Files of Agricultural Resources Based on Hadoop.
Yanfeng Lyu,Xunli Fan,Kun Liu (2017). An Optimized Strategy for Small Files Storing and Accessing in HDFS.
Qi Mu,Yikai Jia,Bibo Luo (2015). The Optimization Scheme Research of Small Files Storage Based on HDFS.
Tao Wang,Shihong Yao,Zhengquan Xu,Lian Xiong,Xin Gu,Xiping Yang (2015). An Effective Strategy for Improving Small File Problem in Distributed File System.
H He,Z Du,W Zhang,A Chen (2016). Optimization strategy of Hadoop small_le storage for big data in healthcare.
S Fu,L He,C Huang,X Liao,K Li (2015). Performance optimization for managing massive numbers of small files in distributed file systems.
Wenjun Tao,Yanlong Zhai,Jude Tchaye-Kondi (2019). LHF: A New Archive Based Approach to Accelerate Massive Small Files Access Performance in HDFS.
Kyoungsoo Bok,Hyunkyo Oh,Jongtae Lim,Yosop Pae,Hyoungrak Choi,Byoungyup Lee,Jaesoo Yoo (2017). An efficient distributed caching for accessing small files in HDFS.
No ethics committee approval was required for this article type.
Data Availability
Not applicable for this article.
How to Cite This Article
Prof. Shwetha K S. 2026. \u201cCritical Analysis of Solutions to Hadoop Small File Problem\u201d. Global Journal of Computer Science and Technology - C: Software & Data Engineering GJCST-C Volume 23 (GJCST Volume 23 Issue C2).
Explore published articles in an immersive Augmented Reality environment. Our platform converts research papers into interactive 3D books, allowing readers to view and interact with content using AR and VR compatible devices.
Your published article is automatically converted into a realistic 3D book. Flip through pages and read research papers in a more engaging and interactive format.
Our website is actively being updated, and changes may occur frequently. Please clear your browser cache if needed. For feedback or error reporting, please email [email protected]
Thank you for connecting with us. We will respond to you shortly.