Future cars are anticipated to be driverless; point-to-point transportation services capable of avoiding fatalities. To achieve this goal, auto-manufacturers have been investing to realize the potential autonomous driving. In this regard, we present a self-driving model car capable of autonomous driving using object-detection as a primary means of steering, on a track made of colored cones. This paper goes through the process of fabricating a model vehicle, from its embedded hardware platform, to the end-to-end ML pipeline necessary for automated data acquisition and model-training, thereby allowing a Deep Learning model to derive input from the hardware platform to control the car’s movements. This guides the car autonomously and adapts well to real-time tracks without manual feature-extraction.
## I. INTRODUCTION
Self-Driving Car' is one that is able to sense its immediate surroundings and operate independently without human intervention. The main motivation behind the topic at hand is the expeditious progress of applied Artificial Intelligence and the foreseeable significance of autonomous driving ventures in the future of humanity, from independent mobility for non-drivers to cheap transportation services to low-income individuals. The emergence of driverless cars and their amalgamation with electric cars promises to help minimize road fatalities, air and small-particle pollution, being able to better manage parking spaces, and free people from the mundane and monotonous task of having to sit behind the wheel. Autonomous navigation holds quite a lot of promise as it offers a range of applications going far beyond a car driven
## II. SOFTWARE DEVELOPMENT
In this section we elucidate the entire software development process which includes data collection and labelling, model training and model deployment.
### a) Data Collection & Labelling
Around 2,000 images were collected for two types of coloured cones, namely: Orange and Blue. The cones were made from craft paper and were 4.5 centimetres tall with a base diameter of $3\mathrm{cm}$. The pictures included the cones laid out as track, single colour cones, multiple same-coloured cones and a mix of the two cones. A total of 16,382 cones were observed in the collected images with LabellImg being later used to label these cones from the images. 'LabellImg' is a graphical image annotation tool [6]. It is written in Python and uses Qt for its graphical interface. The LabellImg tool was used to label the photographed images in the YOLO format by drawing bounding boxes around the cones and naming each cone with their respective class i.e., colour (orange or blue). After labelling via LabellImg, a common class file was created to all images which contained the two classes "Orange" and "Blue". Another file was created unique to each image which contained the coordinates of each cone present in that image. For example, 1 0.490809 0.647894 0.235628 0.342580 is an entry from the class file created where the first parameter determines the class of the cones, the second and third parameters determine the midpoint of the bounding box while the fourth and fifth parameters determine the height and width of the bounding box. For the randomization and renaming of the images, a software tool called 'Rename Expert' was used. It randomized the images and then named them from 0-1681. Data augmentation was used to increase the amount of data by adding slightly modified copies of already existing data. It involves injecting some noise, rotation and flipping of the images to increase the number of images used for training. It usually helps in preventing overfitting the model and acts as a regularizer [7].
### b) Model Training
YOLOv4 Tiny, a version of YOLOv4 developed for edge and lower-power devices, is a real-time object detection algorithm capable of detecting and providing bounding boxes for many different objects in a single image [8-11]. The model achieves this by dividing an image into regions and then predicting bounding boxes in addition to the probabilities for each region. Relative to inference speed, YOLOv4 outperforms other object detection models by a significant margin. We needed a model that prioritizes real-time detection and conducts the training on a single GPU as well. 'Darknet' is a framework like the Tensor Flow, PyTorch and Keras that proved to be apt for the task at hand. While Darknet is not as intuitive to use, it is immensely flexible, and it advances state-of-the-art object detection results. We train the model on darknet and then later convert it to Tensor Flow for ease in usability. This model can be tested on a physical model or on virtual simulators [12-15]. In terms of training the model, the labelled dataset was segregated into training and validation datasets and was uploaded on cloud VM. After that, the darknet was cloned and built on which the model was trained. The parameters were configured periodically to achieve the best weights. It was important that we convert our darknet framework into Tensor Flow because only then could we make use of the Tensor Flow lite model which is optimized for embedded devices such as Jetson Nano to make the inference at the edge.
### c) Deployment
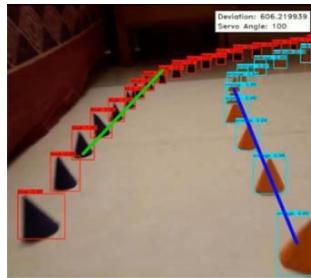
Deployment includes reading the coordinate text data generated from the YOIO4 model into a NumPy framework and labelling the coordinate points according to the two classes, blue and orange. This is done by iterating through the text data line by line, and appending the required point objects into a python array, and finally converting the array into a NumPy format. Matplotlib is used to visualize the set of data points from the camera's perspective, on a $10 \times 10$ cm2 adjusted screen. Using the Scikit-Learn Library, a Linear Regression model is trained using the NumPy data. Two different models are to be trained; one for the blue set of cones, and one for the orange. Using the 'Linear Regression()' predefined method in the Scikit-Learn library, we could easily create a simple regression model without having to build the entire code for the model ourselves. The data is zipped and iterated through using a for loop. The output generated is explicitly converted into a list format. Two lines are created that pass through the orange cones and the blue cones. Again, a graph is plotted of Matplotlib for visual aid of the lines. Next, the equations of the previously formed lines are derived using simple geometric calculations. Straight line equations of the type: $ax + by + c = 0$ are obtained for both blue and orange lines. Next, the point of intersection of the two lines is calculated using the formula of point of intersection. The offset of this line is calculated from the centre of the screen and the x-coordinate of each point is subtracted by the corresponding point on the centre of the screen. This value is the mean deviation and will be used further to calculate the angle by which servo attached on the assembly is to be turned. Fig. 1 shows the outcome of the entire video capture and path mapping process.
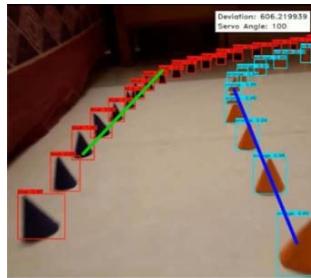
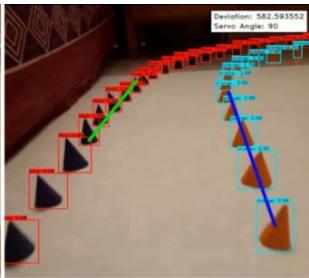

 Fig. 1: Video Capture and Path Mapping Process

## III. HARDWARE DESIGN
Before The car was designed and built with the proper placement and positioning of electronic components, such as the camera, in mind. It consists of three main parts, the steering assembly, the spur gear gearbox and the wheels. The steering system has a rack and pinion type design, chosen for its simple assembly and for providing easier and more compact control over the car. A 3-sided gear box ensures the effortless placement and positioning of the axles and larger gears. Given the opposing forces caused by the axles and front chassis, it also stays strong and sturdy. Spur gears are used in the gear box as they have high power transmission efficiencies (95% to 99%) and are simple to design and install. The wheels are designed and entirely 3D printed to have built-in suspension providing additional steering stability. Because the wheels must be flexible, TPU (Thermoplastic Polyurethane) is used to produce them. All other 3D printed components were produced using PLA (Polylactic acid) as it's easy to use, has a remarkably low printing temperature compared to other thermoplastics and produces better surface details and sharper features. A list of all materials is given below:
List of Materials: All components required for the prototype, including sensors, actuators, power supply, and hardware, are listed here. Fig. 2 and Fig. 3 show all the 3D printed parts and their assembly in Soild Works Simscape respectively.
- 3D Printed Parts
- 608zz Bearings (4x)
- Nvidia Jetson Nano
- 1200KV Brushless DC Motor
- 20A ESC (Electronic Speed Controller)
- 5000mAh Power Bank
- 11.1V - 2200mAh (Lithium Polymer) LiPo Rechargeable Battery
- PCA9685 16 Channel Servo Driver
- TowerPro SG90 180° Rotation Servo Motor
- Logitech C615 HD Webcam
 Fig. 2: 3D Printed Parts
 Fig. 3: Car Assembly on Solid Works Simscape
## IV. FUNCTIONALITY
A Nvidia Jetson Nano single-board computer (SBC) serves as both the brain and the communication node in the prototype control system. This SBC receives data from the camera, analyses them, and integrates them into the navigation system to determine the steering angle. A 11.1V - 2200mAh LiPo battery is used solely to power the vehicle's propulsion system, that is, the 1200KV Brushless DC Motor with a 20A ESC. A $180^{\circ}$ rotation servo motor with a torque of $1.2\mathrm{KgCm}$, controlled by the PCA9685 16 Channel Servo Driver, is used to steer the car. Fig. 4 and Fig. 5 show a flowchart of the instruction feedback loop and a schematic diagram of the hardware connections respectively. Fig. 6 shows the entire assembled car.
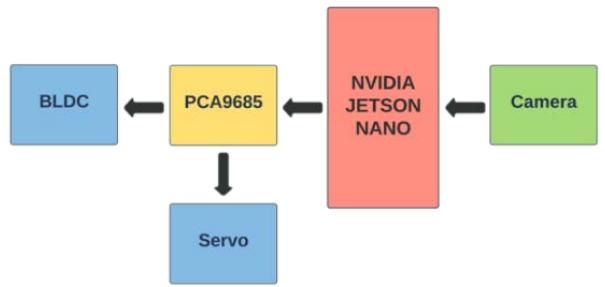 Fig. 4: Flowchart of the Instruction Feedback Loop
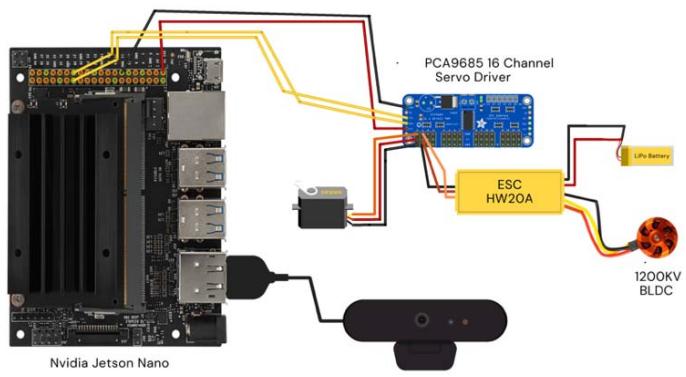
 Fig. 5: Circuit Diagram Fig. 6: Assembled Car
## V. CONCLUSION
Through this paper, we present an approach for designing and building a model self-driving car based on the concept of Behavioural Cloning. This approach being an end-to-end one does not require any of the conventional tasks of feature extraction or connection of various modules, which are often monotonous, manual
in nature and necessary for efficient working. Our model car is tried and tested in real life against various standard models such as DenseNet-201, Resnet-50, and VGG19 for the comparison and performance. The final proposed model is a convolution-based, ten 2D-Convolutional Layers, one Flat Layer and four Dense Layers model. When compared with other Deep Learning based models, our model seems to have outperformed all of the aforementioned standard models by a substantial margin. The work presented through this paper can be realized to build vehicles capable of autonomous steering and driving. Additional training data of real-world obstacles with different track situations and conditions may be required to increase the agility and robustness of the system.
## VI. FUTURE SCOPE
Through this project, we aimed to provide proof of concept for self-driving cars that can solely rely on vision-based object detection techniques for navigation, rather than the conventional feature extraction-based lane detection techniques. Results obtained on our model car made it clear that our approach towards object detection as a means of steering has either outclassed or is at-par with humans in the parameters being tested for. Reinforcement learning methods can be introduced in addition to this method to better performance. This method can be used as a prototype for future citywide self-driving cars projects. It can also be used exclusively, or in addition to conventional lane detection, to further improve on accuracy of self-driving cars. Via these techniques, automobiles might truly serve as end-to-end personal transportation devices and may give rise to an entire ecosystem of car-pooling or car sharing services as well as numerous start-ups thereby making personal transport cheaper, faster and safer. However, when implementing in the real world, many more parameters might be introduced which may increase the complexity of such a system while affecting the performance of the car.
Generating HTML Viewer...
References
15 Cites in Article
Felix Endres,Jurgen Hess,Jurgen Sturm,Daniel Cremers,Wolfram Burgard (2014). 3-D Mapping With an RGB-D Camera.
M Tipping,M Hatton,R Herbrich (2013). US brings patent system in line with rest of the world.
L Cardamone,D Loiacono,P Lanzi,A Bardelli (2010). Searching for the optimal racing line using genetic algorithms.
Krisada Kritayakirana,J Gerdes (2012). Using the centre of percussion to design a steering controller for an autonomous race car.
H Fujiyoshi,T Hirakawa,T Yamashita (2019). Deep learning-based image recognition for autonomous driving.
Darrenl (2015). Figure 5: Annotation process in LabelImg..
Chigozie Nwankpa,Solomon Eze,Winifred Ijomah,Anthony Gachagan,Stephen Marshall (2018). Achieving remanufacturing inspection using deep learning.
Shaoqing Ren,Kaiming He,Ross Girshick,Jian Sun (2017). Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks.
Ruturaj Kulkarni,Shruti Dhavalikar,Sonal Bangar (2018). Traffic Light Detection and Recognition for Self Driving Cars Using Deep Learning.
Aditya Jain (2018). Working model of Self-driving car using Convolutional Neural Network, Raspberry Pi and Arduino.
Juntae Kim,Geunyoung Lim,Youngi Kim,Bokyeong Kim,Changseok Bae (2019). Deep Learning Algorithm using Virtual Environment Data for Self-driving Car.
Yue Kang,Hang Yin,Christian Berger (2019). Test Your Self-Driving Algorithm: An Overview of Publicly Available Driving Datasets and Virtual Testing Environments.
Shital Shah,Debadeepta Dey,Chris Lovett,Ashish Kapoor (2018). AirSim: High-Fidelity Visual and Physical Simulation for Autonomous Vehicles.
A Dosovitskiy,G Ros,F Codevilla,A Lopez,V Koltun (2017). CARLA: An Open Urban Driving Simulator.
B Wymann,C Dimitrakakis,A Sumner,E Espié,C Guionneau (2015). TORCS: The open racing car simulator.
No ethics committee approval was required for this article type.
Data Availability
Not applicable for this article.
How to Cite This Article
Rishabh Chopda. 2026. \u201cDesign and Development of an Autonomous Car using Object Detection with YOLOv4\u201d. Global Journal of Computer Science and Technology - A: Hardware & Computation GJCST-A Volume 23 (GJCST Volume 23 Issue A1): .
Explore published articles in an immersive Augmented Reality environment. Our platform converts research papers into interactive 3D books, allowing readers to view and interact with content using AR and VR compatible devices.
Your published article is automatically converted into a realistic 3D book. Flip through pages and read research papers in a more engaging and interactive format.
Future cars are anticipated to be driverless; point-to-point transportation services capable of avoiding fatalities. To achieve this goal, auto-manufacturers have been investing to realize the potential autonomous driving. In this regard, we present a self-driving model car capable of autonomous driving using object-detection as a primary means of steering, on a track made of colored cones. This paper goes through the process of fabricating a model vehicle, from its embedded hardware platform, to the end-to-end ML pipeline necessary for automated data acquisition and model-training, thereby allowing a Deep Learning model to derive input from the hardware platform to control the car’s movements. This guides the car autonomously and adapts well to real-time tracks without manual feature-extraction.
Our website is actively being updated, and changes may occur frequently. Please clear your browser cache if needed. For feedback or error reporting, please email [email protected]
Thank you for connecting with us. We will respond to you shortly.