## I. INTRODUCTION
Our world is moving towards digitized business. This opens up numerous avenues to increase revenue through digital marketing, sales forecast, etc. Huge amount of historical data is available to analyze customer behavior, buying patterns and make predictions for future. However, it also comes with challenges along the way. A substantial amount of the value to be harvested from digitization depends on successful integration of large volume of data from different sources. Unfortunately, many of the existing data sources do not share a common frame of reference. For example, let us say, a marketing team wants to use statistics from retail stores, e-commerce sites etc., to find out potential buyers for a product. Sadly, these two systems do not refer to customers in the same way – i.e., there are no common identifiers or names across the two systems. Duplicate emails or messages may be sent to same customer again and again unless customer records are tagged uniquely. Recommendations to a customer and an effective marketing scheme cannot be performed based on distinct data silos. A group of similar problems has been studied for a long time in a variety of fields under different names like entity resolution, de-duplication etc. Entity matching is the field of research dedicated to solving the problem of matching which records refer to the same real-world entity. Organizations often struggle with a plethora of customer data captured multiple times in different sources by various people in their own ways. Despite having been studied for decades, entity matching remains a challenging problem in practice. In general, there are several factors that make it difficult to solve:
Poor Data Quality: Real-world data is seldom completely structured, cleansed, and homogeneous. Data originating from manual insertion may contain alternative spellings, typos, or fail to comply with the schema (e.g., mixing of first and last name).
Dependency on Human Knowledge: Same data may be represented in different formats by various users like abbreviations, suffixes, prefixes, etc. To perform matching, our solution must interact with human experts and make use of their knowledge. Human interaction in itself is a complex domain.
For example, let's look at a customer table from which analyst is trying to identify distinct customers.
Table 1: Customer Records with Duplicates
<table><tr><td>No.</td><td>Name</td><td>Address</td><td>Email</td></tr><tr><td>1</td><td>Alexander Great</td><td>2/13, Philip Street, Paris, France</td><td>
[email protected]</td></tr><tr><td>2</td><td>Alexander G</td><td>2/13, Philip Street, Paris</td><td>n/a</td></tr><tr><td>3</td><td>Alexander Graham</td><td>10, Middle Street, New York</td><td>
[email protected]</td></tr></table>
Without manual inspection and good understanding of geographical locations, it is difficult to guess whether record 2 is duplicate of 1 or 3. Somewhat ironically, as often pointed out, entity matching suffers from the problem of being referenced by different names, some referring to the exact same problem, while others are slight variations, generalizations, or specializations. In addition, the names are also not used completely consistently. Dedduplication or duplicate detection is the problem of identifying records in the same data source that refer to the same entity and can be seen as the special case $1 = 2$. Given such representation variations, an unprecedented number of permutations and combinations, the entity matching would be a herculean job when we handle large volume of data. Artificial intelligence and machine learning has become an essential part of multiple research fields in recent years, most notably in natural language processing and computer vision, which are concerned with unstructured data. Its most prominent advantage over systematic approaches is its ability to learn features instead of relying on step-by-step calculations.
### a) Problem Definition
Researchers have already realized the potential advantage of machine learning for entity matching. In this paper, we aim to propose a machine learning model for entity matching.
Let E be a data source containing entities. E has the attributes (A1,A2,...,An), and we denote entities as e = (e1, e2,..., en) ∈ E. A data source is a set of records, and a record is a tuple having a specific schema of attributes. An attribute is defined by the intended semantics of its values. So, entities ei = ej if and only if attributes ai of ei are intended to carry the same information as attributes aj of ej, and the specific syntactics of the attribute values are irrelevant. Attributes can also have metadata (like a name) associated with them, but this does not affect the equality between them.
The goal of entity matching is to find the largest possible binary relation $M \subseteq E \times E$ such that $a$ and $b$ refer to the same entity for all $(a, b) \in M$. In other words, we would like to find all record pairs across data source that refer to the same entity. We define an entity to be something of unique existence. Attribute values are often assumed to be strings, but that is not always the case. The records are assumed to operate with the same taxonomic granularity. In this research, we will stick to the definition of dedduplication (or duplicate detection) as the problem of identifying which records in the same data source refer to the same entity.
The remainder of this paper is organized as follows. We discuss related work in section 2. In Section 3, we formally formulate the problem and propose our methodology. Section 4 describes how our approach is used to detect similarity in a real-world data set and the results of our experiment are explained. Finally, the paper is concluded in Section 5.
## II. RELATED WORK
Entity resolution, record linkage, dedduplication and entity matching are frequently used for more or less the same problem as we mentioned earlier. It is a technique to identify data records in a single data source or across multiple data sources that refer to the same real-world entity and to correlate the records together. In entity matching, the strings that are nearly identical, but not exactly the same, are matched without explicitly having a unique identifier. Entity matching is crucial as it matches non-identical records despite all the data inconsistencies without the constant need for formulating rules. By combining databases using fuzzy matching, we can refine the data and analyze the information. Comparing big data records having non-standard and inconsistent data from diverse sources that do not provide any unique identifier is a complex problem. In this section, we present an overview of the previous work done by researchers in entity matching. Researchers use two major techniques as shown below:
Rule-Based: Rule-based systems perform matching based on a set of manually crafted rules. To match any two records of the same entity, various string-based comparison rules are defined. Each record then would run with every other record on all these rules to decide if the two are identical.
Automatic: These systems rely on machine learning algorithms to learn from data. Computers first learn from data provided for training so that they can later make predictions on unknown input data items.
Usually, a rule-based system uses a set of human-crafted rules to help identify subjectivity. As the number of records increases, the number of comparisons increases exponentially in rule-based systems. With large volume of records, rule-based data matching becomes computationally challenging and unscalable. Automatic methods, contrary to rule-based systems, do not rely on manually crafted rules but on machine learning algorithms. There has been an uptick in interest on machine learning as a solution for entity matching in recent years. We note that this process is machine-oriented and does not highlight any iterative human interactions or feedback loops. First, there are several books that provide an overview. Christen [15] is a dedicated and comprehensive source on entity matching. Anhai Doan et al. [2] and Talburt [10] introduce entity matching in the context of data quality and integration. Quite early on, statisticians dominated the field of entity matching. Probabilistic methods were first developed by Newcombe et al. [15]. A solid theoretical framework was presented by Fellegi and Sunter [9]. Blocking, which is surveyed by Papadakis et al. [8, 9], is considered an important subtask of entity matching. This is meant to tackle the quadratic complexity of potential matches. Christophides et al. [24] specifically review entity matching techniques in the context of big data. Significant research has gone into active learning approaches by Arvind [3], Jungo [11] and Kun [12]. Interestingly, Jungo et al. [11] use a deep neural network in their active learning approach. Such human-in-the-loop factors are often crucial for entity matching in practice as analyzed by Anhai et al. [2]. Many state-of-the-art models for natural language processing are based on deep learning networks. Central to all these approaches is how text is transformed to a numerical format suitable for a neural network. This is mainly done through embeddings, which are translations from text units to a vector space – traditionally available in a lookup table. The text units will usually be characters or words. An embeddings lookup table may be seen as parameters to the network and can be learned together with the rest of the network end-to-end. That way the network is able to learn good, distributed character or word representations for the problem at hand. The words used in a data set are often not unique to that data set, but rather just typical words from some language. Therefore, one may often get a head start by using pretrained word embeddings like word2vec, GloVe or fastText, which have been trained on enormous general corpora. One particular influential recent trend is the ability to leverage huge pretrained models that have been trained unsupervised for language modeling on massive text corpora similar to what the computer vision community has done for image recognition. They produce contextualized word embeddings that consider the surrounding words. These contextual embeddings can be used as a much more powerful variant of the classical word embeddings, but as popularized by BERT. However, with neural networks, the actual line between the initial feature extraction part and the rest is an artificial one and not necessarily indicative of how the networks actually learn and work. But they do reflect design decisions to a certain degree and help us compare them in that regard. Often these approaches use pre-built word embeddings for a specific set of values. Our research focuses on entity matching based on attributes where
the number of attributes may vary from one use case to another. Also, we try to address the problem of multiple domains, i.e., the machine learning model must be suitable for entities from various categories like customers, products, vendors, etc. In this paper, we present a machine learning model which will perform attribute-based matching of entities. The type, number of attributes may vary over the time, but our approach does not require re-design. Merely a re-training of the model on the new data set will suffice. The model is robust enough to handle slight variations in ordinality and type of the attributes.
## III. METHODOLOGY
Most neural network-based methods perform entity matching by producing so-called knowledge graph embeddings, embeddings of entries which incorporate information about their relationship with other entries. The embeddings work mainly at word level or character level. Embeddings offer neural networks an initial mapping from the actual input to a suitable numeric representation. When we surveyed the earlier methods, we found that researchers focus on explicit levels of representation of entities into single word or text. However, we try to address two problems mainly,
- How to perform matching of entities containing attributes of different data types, say string, boolean, and categorical?
- Will the machine learning algorithm continue to work even if the number of attributes change over the time?
Let's say there are few entities in a data set as shown in Table 1. It has two duplicates. Following is a generalized notation.
Table 2: Labelled Entities with Multiple Attributes
<table><tr><td>Entity</td><td>Attribute1</td><td>Attribute2</td><td>Attribute3</td><td>Label</td></tr><tr><td>e1</td><td>a11</td><td>a12</td><td>a13</td><td rowspan="2">Duplicate (e1 = e2)</td></tr><tr><td>e2</td><td>a21</td><td>a22</td><td>a23</td></tr><tr><td>e3</td><td>a31</td><td>a32</td><td>a33</td><td>Unique</td></tr></table>
The entities e1 and e2 are same, though they might vary slightly in their attribute values but have similar meanings. Our aim is to design an approach which will combine the attribute level similarity and artificial intelligence to classify entities as unique or duplicate. We propose a two-step methodology where the first step involves calculating attribute level similarity scores and the second step is classification using supervised learning. Feature extraction involves use of a distance function for every pair of attributes. It transforms every pair of entities into numerical vector. For any given pair of attributes $(a_{ij}, a_{kj})$, the distance function $\delta$ produces a numerical value such that
$$
0 < = \delta \left(a _ {i j}, a _ {k j}\right) < = 1
$$
If the two attributes are exactly same, then the distance metric is zero. If they are completely unrelated, then the distance is 1. Partial match will result in value between 0 and 1. We call it as similarity score of the attributes.
A sample set of vectors for a set of three entities will be as shown below.
Table 3: Feature Extraction using Similarity Score
<table><tr><td>Entity Pair</td><td>Score1</td><td>Score2</td><td>Score3</td><td>Label</td></tr><tr><td>e1,e2</td><td>δ(a11, a21) = 0.8</td><td>δ(a12, a22) = 0.6</td><td>δ(a13, a23) = 1</td><td>D</td></tr><tr><td>e2,e3</td><td>δ(a21, a31) = 0.5</td><td>δ(a22, a32) = 0.6</td><td>δ(a23, a33) = 0</td><td>U</td></tr><tr><td>e1,e3</td><td>δ(a11, a31) = 0.6</td><td>δ(a12, a32) = 0.4</td><td>δ(a13, a33) = 1</td><td>U</td></tr></table>
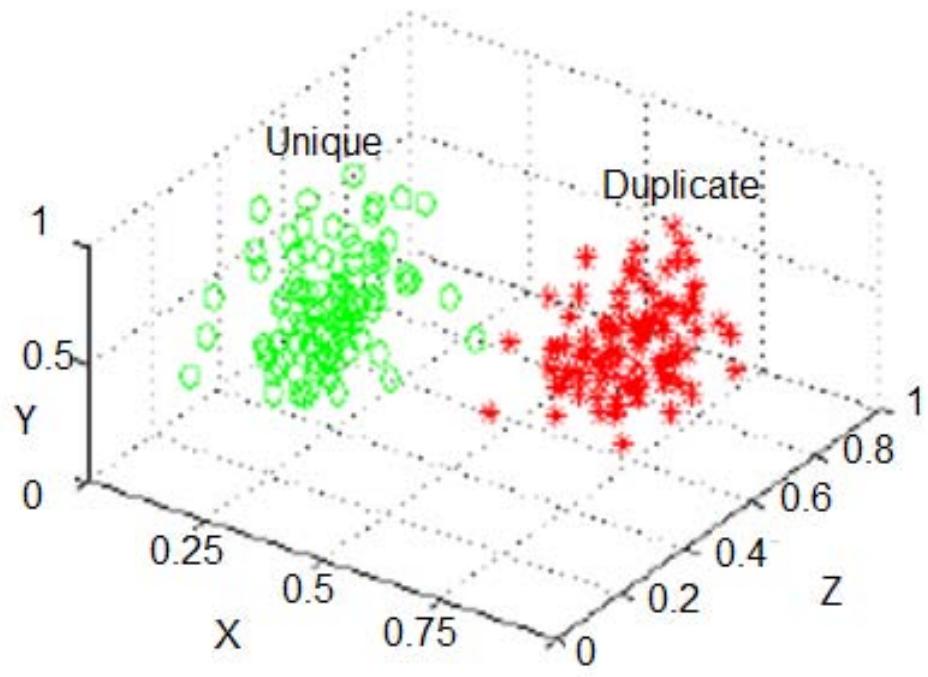
The extracted values correspond to two class labels duplicate (D) and unique (U). If we extract feature vectors of a data set and plot the points in a 3- dimensional space, then we will see two clusters as shown below.
 Figure 1: Feature Vectors Plotted in 3-D Space For
$m$ entities having $n$ attributes, after feature extraction, we will get $m \times n$ values under the two labels. Now, the entity matching problem is reduced to a binary classification problem, where the objective is to predict a pair of entities as unique or duplicate. Feature extraction involves attribute level comparison using fuzzy matching algorithms. The produced output is a labelled data set which can be used to train a model using supervised learning algorithm. A well-trained model will make predictions over the incoming data point. Points which lie around the boundary or away from the cluster centroid might require manual stevedoring. Following diagram shows the architecture of our machine learning based entity matching system.
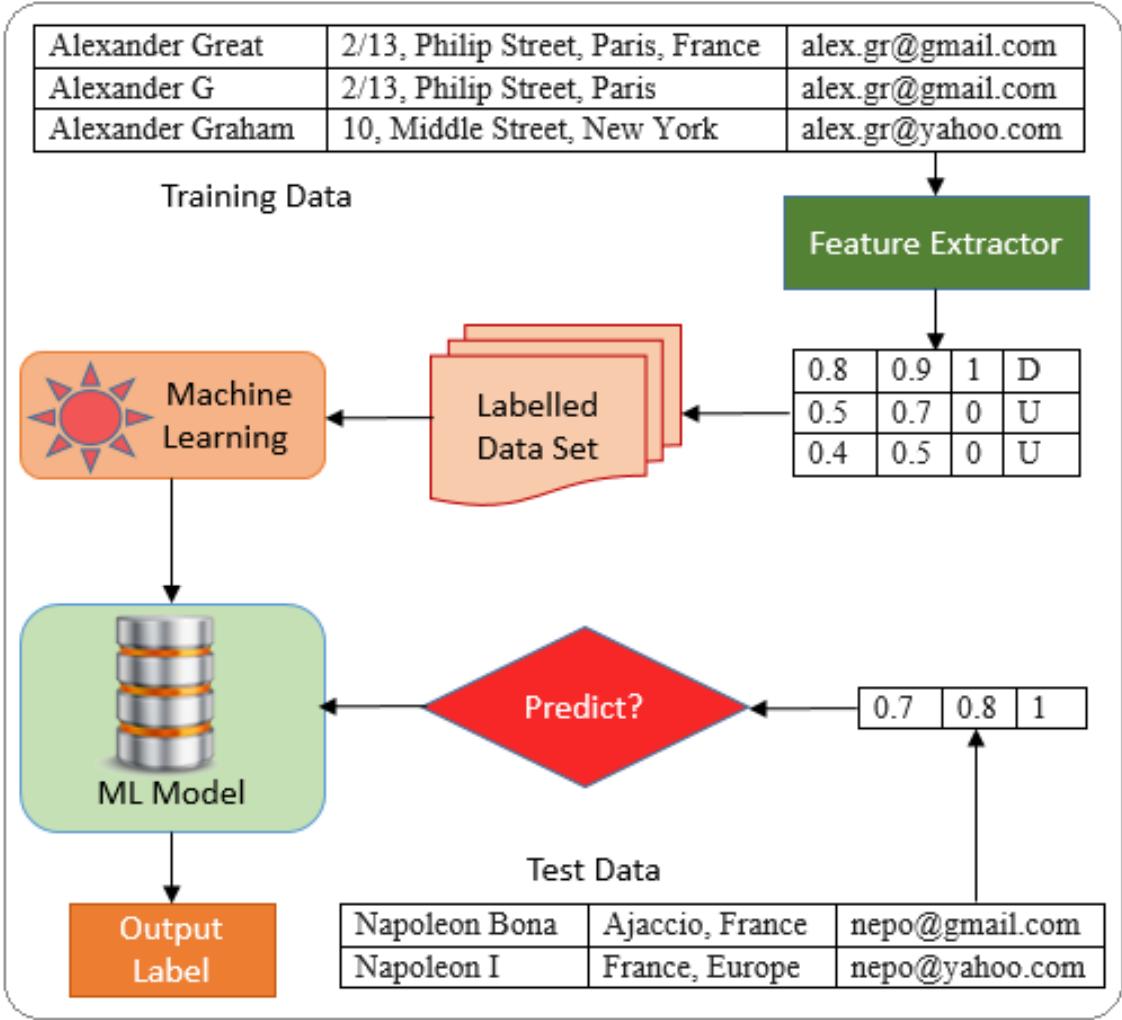 Figure 2: Architecture of Entity Matching System
Our approach takes every pair of entities and produces a numerical vector. This is in turn fed to a machine learning algorithm for classification. We use supervised learning algorithm for classification. The ML model learns from the training data set and makes accurate predictions on the incoming test data.
### a) Feature Extraction using Similarity Score
The first step in ML modeling is data preprocessing, which is usually a crucial step in many data analytics tasks. Typical transformations involve lowercasing all letters, removing excess punctuation, normalizing values, and tokenizing. There are two other major steps in our process. Second one being the feature vector construction using similarity score and last step is machine learning. One might also view second step as feature extraction, since records are transformed to a feature space. The success of this entity matching systems depends upon careful selection of right algorithms. Attributes are often assumed to be strings, but that is not the case always. Attributes of an entity may be of any data type like string, numeric, categorical, boolean etc. One single function will not be able to calculate similarity score for various attributes to attribute. It is useful to compare various functions available for similarity score and pick the right choice. To this end, we present a high-level overview of few popular algorithms.
Table 4: Similarity Score Functions
<table><tr><td>No.</td><td>Data Type</td><td>Similarity Function</td></tr><tr><td>1</td><td rowspan="5">Single Word String</td><td>Exact Match</td></tr><tr><td>2</td><td>Levenshtein Distance</td></tr><tr><td>3</td><td>Jaro Distance</td></tr><tr><td>4</td><td>Jaro-Winkler Distance</td></tr><tr><td>5</td><td>Jaccard Similarity</td></tr><tr><td>6</td><td rowspan="6">2-to-5 Words String</td><td>Cosine Similarity</td></tr><tr><td>7</td><td>Levenshtein Distance</td></tr><tr><td>8</td><td>Jaccard Similarity</td></tr><tr><td>9</td><td>Needleman-Wunsch Algorithm</td></tr><tr><td>10</td><td>Smith-Waterman Algorithm</td></tr><tr><td>11</td><td>Monge-Elkan Algorithm</td></tr><tr><td>12</td><td rowspan="4">Long String (>5 Words)</td><td>Cosine Similarity</td></tr><tr><td>13</td><td>Levenshtein Distance</td></tr><tr><td>14</td><td>Jaccard Similarity</td></tr><tr><td>15</td><td>Monge-Elkan Algorithm</td></tr><tr><td>16</td><td rowspan="2">Number</td><td>Exact Match</td></tr><tr><td>17</td><td>Absolute Difference</td></tr><tr><td>18</td><td>Categorical</td><td>Exact Match</td></tr><tr><td>19</td><td>Boolean</td><td>Exact Match</td></tr></table>
For example, consider a similarity function Levenshtein Distance. The Levenshtein distance between 'new yrk' and 'new york' is one since it needs at least one edit (insertion, deletion, or substitution) to transform from 'new yrk' to 'new york'. It is advisable to normalize the similarity scores between 0 and 1 for improved accuracy of the machine learning algorithm.
### b) Classification using Supervised Learning
The matching phase aims to develop the prediction model, which takes a candidate pair as input and predicts whether they are matching or non-matching. Figure 2 illustrates that the model predicts an output label Duplicate (D) or Unique (U). This is a binary classification problem. Data scientists need to decide which algorithm is most suitable for their classification task. Based on our study and experiments, we found three classification algorithms suitable for this task.
## i. K-Nearest Neighbors (KNN)
K-Nearest Neighbors (KNN) is an algorithm that learns all available cases from data set and classifies new data item by a majority vote of its K neighbors. A case assigned to the data is a majority of its K nearest neighbors measured by a distance (metric) function. The metric functions include Euclidean, Manhattan, Minkowski, and Hamming distances. KNN can be used for both regression and classification problems. However, it is widely used in classification problems in the industry.
## ii. XG Boost
XG Boost stands for Extreme Gradient Boosting. It is a scalable, distributed gradient-boosted decision tree (GBDT) machine learning library. It provides parallel tree boosting and is the leading machine learning library for regression, and classification problems.
## iii. Support Vector Machines (SVM)
Support Vector Machine is a supervised algorithm in which the learning algorithm analyzes data and recognizes patterns. We plot the data as points in an n-dimensional space. The value of each feature is then tied to a particular co-ordinate, making it easy to classify the data.
And finally, we need to tune hyper-parameters in order to get the best model performance.
## IV. EXPERIMENTS AND RESULTS
Automatic entity matching makes the life of commercial organizations easier. A company that maintains thousands of customer records cannot afford to employ many people to verify manually and identify duplicates. Artificial Intelligence based entity matching is an efficient and cost-effective analytics tool for operational efficiency. We used open-source data sets for our experiments. While several open-source datasets are available, we picked up few commercial data sets for analysis. In this section, we describe the evaluation tasks, the data sets used, and the experimental results of our approach.
### Evaluation Tasks:
1. We evaluate our approach on real-world data set.
2. We evaluate our approach on popular benchmarks.
Our goal is to provide real-life solution using our approach. We aim to evaluate the quality of entity matching. The empirical result is compared with real-time data to harness the accuracy. The results show promising output.
### a) Data Set
We conducted extensive experiments on real-world benchmark entity datasets to evaluate the performance of approach. Following are few open-source data sets available for evaluating entity matching algorithms.
Table 5: Entity Matching Data Sets
<table><tr><td>No.</td><td>Dataset</td><td>Description</td><td>Training Size</td><td>Testing Size</td><td>No. of Attributes</td></tr><tr><td>1</td><td>Fodors-Zagats</td><td>Customer records with name, address, city, phone, type, and category code.</td><td>757</td><td>189</td><td>6</td></tr><tr><td>2</td><td>iTunes-Amazon</td><td>Records of songs with song name, artist name, album name, genre, etc.</td><td>430</td><td>109</td><td>8</td></tr><tr><td>3</td><td>DBLP-ACM</td><td>Publication dataset with paper title, author, venue etc.</td><td>9890</td><td>2473</td><td>4</td></tr><tr><td>4</td><td>DBLP-Scholar</td><td>Publication dataset with title, authors, venue, and year.</td><td>22965</td><td>5742</td><td>4</td></tr><tr><td>5</td><td>Amazon-Google</td><td>Software product dataset with attributes product title, manufacturer, and price.</td><td>9167</td><td>2293</td><td>3</td></tr><tr><td>6</td><td>Walmart-Amazon</td><td>Electronic product dataset with attributes product name, category, brand, model number, etc.</td><td>8193</td><td>2049</td><td>5</td></tr><tr><td>7</td><td>Abt-Buy</td><td>Product dataset with attributes product name, price, and description.</td><td>7659</td><td>1916</td><td>3</td></tr></table>
Many commercial organizations are nowadays struggling with customer de-duplication. Automatic deduplication has significance in various sectors like Banking and Finance, Insurance, Telecom, Retail, etc. Hence our results mainly focus on the evaluation metrics accuracy on the customer data set.
### b) Popular Metrics
In this section, we first describe a set of metrics commonly used for evaluating the performance of our classification model. Then we present a quantitative analysis of the performance using popular benchmarks.
Accuracy and Error Rate: These are primary metrics to evaluate the quality of a classification model. Let TP, FP, TN, FN denote true positive, false positive, true negative, and false negative, respectively. The classification Accuracy and Error Rate are defined in Equation 1.
$$
\text{Accuracy} = \frac{\left(\mathrm{T P} + \mathrm{T N}\right)}{N}, \quad \text{Errorrate} = \frac{\left(\mathrm{F P} + \mathrm{F N}\right)}{N} \tag{1}
$$
where $N$ is the total number of samples. Obviously, we have Error Rate $= 1 - \text{Accuracy}$.
Precision, Recall, and F1 Score: These are also primary metrics and are more often used than accuracy or error rate for imbalanced test sets. Precision and recall for binary classification are defined in Equation 2. The F1 score is the harmonic mean of the precision and recall, as in Equation 2. F1 score reaches its best value at 1 (perfect precision and recall) and worst at 0.
$$
\text{Precision} = \frac{\mathrm{T P}}{\mathrm{T P} + \mathrm{F P}}, \quad \text{Recall} = \frac{\mathrm{T P}}{\mathrm{T P} + \mathrm{F N}}, \quad \mathrm{F 1 - s c o r e} = \frac{2 * \operatorname{Prec} * \operatorname{Rec}}{\operatorname{Prec} + \operatorname{Rec}} \tag{2}
$$
For multi-class classification problems, we can always calculate precision and recall for each class label and analyze the individual performance on class labels or average the values to get the overall precision and recall. In our case, the average for the two labels Duplicate (D) and Unique (U) were calculated and the following diagram is the pictorial representation of the metrics.
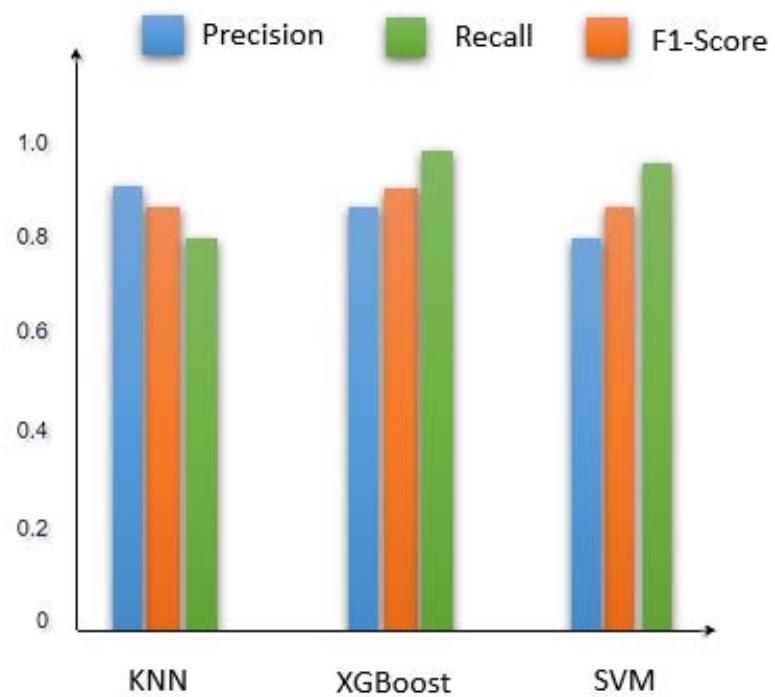 Figure 3: Quantitative Metrics Analysis
From the above results, we observe that XGBoost has highest F1-Score and best suited for the entity matching problem. Following table shows the final metrics of experiments conducted using various similarity score and classification algorithms over Fodors-Zagats dataset.
Table 6: F1-Score of Various Algorithms
<table><tr><td rowspan="2" colspan="2"></td><td colspan="3">CLASSIFICATION ALGORITHM</td></tr><tr><td>XGBoost</td><td>KNN</td><td>SVM</td></tr><tr><td rowspan="3">SIMILARITY SCORE</td><td>Jaccard Similarity</td><td>87%</td><td>86%</td><td>83%</td></tr><tr><td>Levenshtein Distance</td><td>84%</td><td>83%</td><td>81%</td></tr><tr><td>Cosine Similarity</td><td>83%</td><td>81%</td><td>80%</td></tr></table>
### c) Empirical Results
We aim to use our entity matching system in real world applications like retail, e-commerce etc. We analyzed the presence of duplicate customer data and results showed more that $80\%$ accuracy in read-world data sets. Following is a set of predictions made by our system from Fodors-Zagats dataset.
Table 7: Entities Matched using Automated System
<table><tr><td>No.</td><td>Name</td><td>Address</td><td>City</td><td>Phone</td><td>Label</td></tr><tr><td>1</td><td>restaurant ritz-carlton atlanta</td><td>181 Peachtree st.</td><td>Atlanta</td><td>404/659 -0400</td><td rowspan="2">D</td></tr><tr><td>2</td><td>ritz-carlton restaurant</td><td>181 Peachtree st.</td><td>Atlanta</td><td>404/659 -0400</td></tr><tr><td>3</td><td>posterior</td><td>545 post st.</td><td>San Francisco</td><td>415/776 -7825</td><td rowspan="2">D</td></tr><tr><td>4</td><td>postrio</td><td>545 post street.</td><td>San Francisco</td><td>415/776 -7825</td></tr><tr><td>5</td><td>tavern on the green</td><td>in central park at 67th st</td><td>New York</td><td>212/873 -3200</td><td rowspan="2">D</td></tr><tr><td>6</td><td>tavern on the green</td><td>central park west</td><td>New York</td><td>212/873 -3200</td></tr><tr><td>7</td><td>carey's</td><td>1021 cobb pkwy. se</td><td>marietta</td><td>770-422-8042</td><td>U</td></tr><tr><td>8</td><td>carey's corner</td><td>1215 powers ferry rd.</td><td>marietta</td><td>770-933-0909</td><td></td></tr><tr><td>9</td><td>chops</td><td>70 w. paces ferry rd.</td><td>atlanta</td><td>404-262-2675</td><td rowspan="2">U</td></tr><tr><td>10</td><td>chopstix</td><td>4279 roswell rd.</td><td>atlanta</td><td>404-255-4868</td></tr></table>
From the above table, we observe that customers, vendors can easily get their ambiguities resolved using automatic entity matching system. AI-based entity matching is an alternative to traditional manual or other text analysis-based tools, and it is cost-effective solution for decision-makers.
## V. CONCLUSION AND FUTURE WORK
The proposed method accomplished superior performance in terms of time and cost. The overall benefits of AI-based entity matching include:
Sorting Data at Scale: Manually screening thousands of customer records, or product details is complex and time-consuming. AI-based entity matching helps businesses process large amounts of data in an efficient and cost-effective way.
Real-Time Analysis: The automatic entity matching can help organizations quickly identify duplicates on real-time basis and act swiftly before duplicate marketing or promotional offers are sent out.
Though many deep learning models are being developed nowadays for entity matching, we propose a supervised learning model for few major reasons.
Explainability and Ease of Debugging: For many applications, it is crucial to trust the data source, and try to understand why something does not work is key. Unfortunately, deep learning models are notoriously hard to interpret. As steps in the entity matching process increasingly coalesce into a large neural network, we get fewer checkpoints along the way in the process that can easily be inspected. We can't see the output from each step in the same way anymore. Therefore, figuring out why two records where matched or not matched is usually nontrivial while inspecting deep learning models. There are a few techniques that are already used, such as looking at alignment scores, but we are still far away from a comprehensive way of debugging neural networks for entity matching. Our model addresses the challenges of explainability, running time in interactive settings, and the large need for training examples. Explainability of our supervised learning algorithm helps researchers to improve accuracy through inspection, comparison of algorithms and meet the real-world demands. We also see a lot of opportunities in trying to develop more open datasets, standardized benchmarks, and publicly available pretrained models for entity matching.