This article aims to investigate an innovative approach utilizing model, algorithms and IoT technology for early Parkinson’s disease detection. It introduces the comprehensive IoT network that has the IoT platform, enabling the collection of voice data via mobile phones, extraction of relevant features and data processing. Within this process, a Fully Connected Neural Network (FCNN) model is employed to calculate the probability of Parkinson’s disease, potentially providing healthcare professionals and patients with a convenient, accurate, and early diagnostic tool. The study delves into the structure, algorithms, and the integral role of the FCNN within the IoT network, emphasizing its potential impact on the healthcare sector.
## I. INTRODUCTION
As society continues to evolve and science and technology advance, there is an increasing emphasis on early detection and diagnosis of health issues. Parkinson's disease, as a chronic neurological condition, profoundly impacts the quality of life for affected individuals. Early diagnosis is crucial in providing more effective treatment and care [1]. This paper focuses on exploring a novel approach using IoT technology for early detection of Parkinson's disease [2]. Authors [3] proposed approach to early Parkinson's disease detection on voice analythis base. We will introduce a comprehensive IoT network that collects voice data through mobile phones, extracts relevant features, facilitates data transmission and processing, and ultimately outputs the probability of Parkinson's disease. The implementation of this method holds the promise of providing a more convenient, accurate, and early diagnostic tool for both medical professionals and patients. In this paper, we will delve into the structure and algorithms of this IoT network and discuss its potential impact in the field of healthcare. It is our hope that this innovative approach will be a significant step forward in early intervention and treatment of Parkinson's disease.
Initially, voice data is collected and preprocessed using a mobile phone. This involves capturing speech data from Parkinson's disease (PD) patients for a duration of 5 seconds at a sampling frequency of $44.1\mathrm{kHz}$. To enhance signal quality, the spectral subtraction algorithm [4] is employed to eliminate ambient noise.
Subsequently, features are extracted from the pre-processed speech data after noise reduction. The data is then transmitted to the voice channel an IoT platform. The data is fed into a Matlab analysis function.
The Matlab analysis module plays a pivotal role in interpreting the data by loading a 3-layer FCNN model deployed in the cloud. It processes the data and generates a probability value indicating the likelihood of a possible Parkinson's disease diagnosis.
Finally, the results are relayed from the IoT platform to a mobile phone and the outcomes are displayed on a screen for further examination and evaluation.
## II. DATA COLLECTION AND PRE-PROCESSING
Use the spectrum subtraction algorithm for the voice data, the specific process is as follows:
1. Split the original sound signal into frames, the length of each frame is 256 samples, using $50\%$ overlap to split the frames and get a series of frames of signal.
Let the original sound signal be denoted as $s[n]$, where $n$ is the sample index. - Let the frame length be $L = 256$ samples and the overlap percentage be $50\%$.
Define the frame index $k$ such that the start index of the $k$ -th frame is given by:
$$
n _ {k} = (k - 1) * \frac {L}{2}, k = 1, 2, 3 \tag {1}
$$
The k-th frame of the signal is then given by:
$$
s _ {k} [ n ] = s \left[ n _ {k} + n _ {k + 1} \right], 0 \leq n < L \tag {2}
$$
2. Perform Fourier transform on each frame of signal to get the corresponding spectrum.
Let $s_k[n]$ be the k-th frame of the signal. Apply a window function $w[n]$ to the frame to reduce spectral leakage, such as a Hamming window.
Compute the Fourier transform of the windowed frame to get the complex spectrum $X_{k}[f]$:
$$
X _ {k} [ f ] = \operatorname{sum} \left(w [ n ] * s _ {k} [ n ] * \exp \left(- j * 2 * p i * f * \frac{n}{L}\right)\right), 0 < = f < = \frac{L}{2} \tag{3}
$$
Use spectral subtraction algorithm $X_{avg}[f]$ as the basis to calculate the noise spectrum.
3. Wiener filter the noise spectrum to obtain a more accurate noise estimate.
Let $X_{noise}[f]$ be the noise spectrum estimated from $X_{avg}[f]$.
Apply a Wiener filter to $X_{noise}[f]$ to obtain a more accurate estimate:
$$
X _ {\text{noise}} ^ {\text{filtered}} [ f ] = \frac{X _ {\text{noise}} [ f ]}{\left(X _ {\text{noise}} [ f ] + \alpha * X _ {s} [ f ]\right)} \tag{4}
$$
where $\alpha$ is a smoothing parameter and $X_{s}[f]$ is the spectrum of the original signal.
4. Compare the spectrum of each frame with the Wiener filtered noise spectrum, calculate the signal-to-noise ratio and consider the frequency components with a signal-to-noise ratio lower than 10 dB as noise components [5].
Let $X_{k}[f]$ be the complex spectrum of the k-th frame of the signal.
Compute the signal-to-noise ratio (SNR) for each frequency component as:
$$
S N R [ f ] = 1 0 * l o g 1 0 \left(\frac{| X _ {k} [ f ] | ^ {2}}{\left| X _ {\text{filtered}} [ f ] \right| ^ {2}}\right) \tag{5}
$$
Consider the frequency components with SNR $< 10$ dB as noise components.
5. Subtract the noise frequency components by adjusting the coefficient to 0.5 to obtain the noise removed spectrum.
Let be the noiseless spectrum of the k-th frame of the signal.
For each frequency component $f$, if $SNR[f] < 10$ dB, then set the magnitude of $X_{k}^{\text{noiseless}}[f]$ to:
$$
\left| X _ {k} ^ {\text{noiseless}} [ f ] \right| = 0.5 * \left| X _ {k} [ f ] - X _ {\text{noise}} ^ {\text{filtered}} [ f ] \right| \tag{6}
$$
To obtain the complete signal after removing noise, we need to convert the noise-removed spectrum back to the time domain and superimpose each frame.
Let $X_{k}^{\text{noiseless}}[f]$ be the noiseless signal in the frequency domain of the k-th frame of the signal, and $X_{k}^{\text{noiseless}}[n]$ be the corresponding signal in the time domain. Similarly, let $Y_{k}[f]$ be the noise-removed spectrum of the k-th frame, and $Y_{k}[n]$ be the corresponding signal in the time domain.
To convert the noise-removed spectrum back to the time domain, we can apply the inverse Fourier transform to $Y_{k}[f]$, which gives us $Y_{k}[n]$:
$$
Y _ {k} [ n ] = if F T \left(Y _ {k} [ f ]\right) \tag{7}
$$
Then, we can combine the noise-removed signal of each frame to obtain the complete signal without noise:
$$
x _ {\text{noiseless}} [ n ] = \operatorname{sum} _ {k} \left(x _ {k} ^ {\text{noiseless}} [ n ] * w _ {k} [ n ]\right) \tag{8}
$$
where $w_{k}[n]$ is a window function applied to each frame, and the sum is taken over all frames.
The Figure 1 shows the algorithms of data preprocessing.
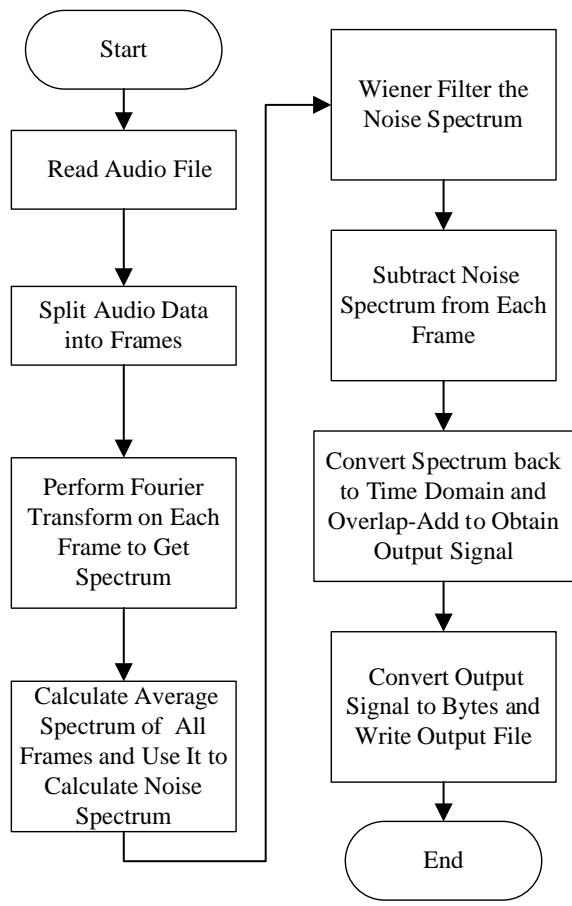 Figure 1: Algorithms of data pre-processing
The voice data after removing the noise is windowed. The main advantage of using the Hamming window [6] to extract the signal window is that it can reduce the oscillation effect at the edge of the window while retaining the main components of the signal inside the window. The window size is 1024 and the frequency of the voice data is 44.1 kHz. The frequency of the voice data is 44.1 kHz and the overlap rate of the window is $50\%$, so the speech time of a window is about 23 ms.
Let $x[n]$ be the original signal in the time domain with a sampling frequency of $f s = 44.1 \, kHz$. Let $w[n]$ be the Hamming window of size $N = 1024$.
The windowed signal $x_{w}[n]$ is obtained by multiplying $x[n]$ with the window $w[n]$ and shifting the window by a hop size of $H = \frac{N}{2}$:
$$
x _ {w} [ n ] = x [ n ] * w [ n - n _ {0} ] \tag {9}
$$
where $n_0 = k * H$ for some integer $k$.
The Hamming window $w[n]$ is defined as:
$$
w [ n ] = 0. 5 4 - 0. 4 6 * \cos \left(2 * p i * \frac {n}{N - 1}\right), 0 \leq n \leq N - 1 \tag {10}
$$
The duration of each windowed segment is $T = \frac{N}{fs} = \frac{1024}{44100}, s = 0.023\sec(23ms)$, and the overlap between adjacent segments is $\frac{H}{T} = 2$.
## III. FEATURE EXTRACTION
Feature extraction of the voice data [7] is performed within the specified window, as illustrated in Table 1 below.
Table 1: Extraction of all features
<table><tr><th>nNum</th><th>Feature Name</th><th>Description</th></tr><tr><td>1</td><td>MDVP:Fo(Hz)</td><td>Average vocal fundamental frequency</td></tr><tr><td>2</td><td>MDVP:Fhi(Hz)</td><td>Maximum vocal fundamental frequency</td></tr><tr><td>3</td><td>MDVP:Flo(Hz)</td><td>Minimum vocal fundamental frequency</td></tr><tr><td>4</td><td>MDVP:Jitter(%)</td><td>Measure of variation in fundamental frequency (percentage)</td></tr><tr><td>5</td><td>MDVP:Jitter(Abs)</td><td>Measure of variation in fundamental frequency (absolute value)</td></tr><tr><td>6</td><td>MDVP:RAP</td><td>Measure of variation in fundamental frequency (relative amplitude perturbation)</td></tr><tr><td>7</td><td>MDVP:PPQ</td><td>Measure of variation in fundamental frequency (pitch period perturbation quotient)</td></tr><tr><td>8</td><td>Jitter:DDP</td><td>Measure of variation in fundamental frequency (average of absolute differences of differences between adjacent periods)</td></tr><tr><td>9</td><td>MDVP:Shimmer</td><td>Measure of variation in amplitude (local variation in amplitude)</td></tr><tr><td>10</td><td>MDVP:Shimmer(dB)</td><td>Measure of variation in amplitude (local variation in amplitude in dB)</td></tr><tr><td>11</td><td>Shimmer:APQ3</td><td>Measure of variation in amplitude (amplitude perturbation quotient, 3-point method)</td></tr><tr><td>12</td><td>Shimmer:APQ5</td><td>Measure of variation in amplitude (amplitude perturbation quotient, 5-point method)</td></tr><tr><td>13</td><td>MDVP:APQ</td><td>Measure of variation in amplitude (average amplitude perturbation quotient)</td></tr><tr><td>14</td><td>Shimmer:DDA</td><td>Measure of variation in amplitude (average absolute difference of amplitudes between consecutive periods)</td></tr><tr><td>15</td><td>NHR</td><td>Ratio of noise to tonal components in the voice</td></tr><tr><td>16</td><td>HNRR</td><td>Ratio of harmonics to noise in the voice</td></tr><tr><td>17</td><td>RPDE</td><td>Nonlinear dynamical complexity measure</td></tr><tr><td>18</td><td>D2</td><td>Nonlinear dynamical complexity measure</td></tr><tr><td>19</td><td>DFA</td><td>Signal fractal scaling exponent</td></tr><tr><td>20</td><td>spread1</td><td>Nonlinear measure of fundamental frequency variation</td></tr><tr><td>21</td><td>spread2</td><td>Nonlinear measure of fundamental frequency variation</td></tr><tr><td>22</td><td>PPE</td><td>Nonlinear measure of fundamental frequency variation</td></tr></table>
## IV. DATA TRANSMISSION AND PROCESSING
To upload the 22 features to Thingspeak [8] IoT for analysis.
1. Creating a Channel. Figure 2 below shows the setup of the VOICE channel.
Channel Settings
 Figure 2: The voice channel settings
2. Getting the voice channel write/read API key and channel ID. The figure 3 below shows the voice channel write/read API key and channel ID.
 Figure 3: The write/read API key and channel ID of the voice channel
3. Using the API in the phone. The API library code uses the HTTP protocol to upload 22 voice features to the voice channel. Figure 4 shows the ThingSpeak API data upload algorithm.
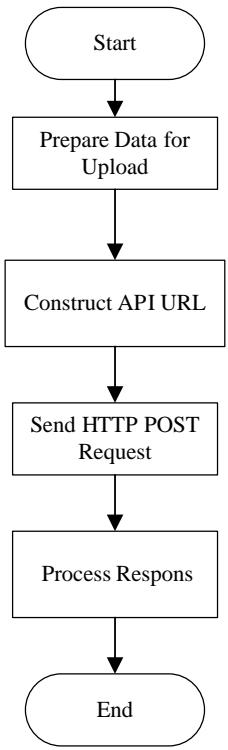 Figure 4: ThingSpeak API data upload algorithm
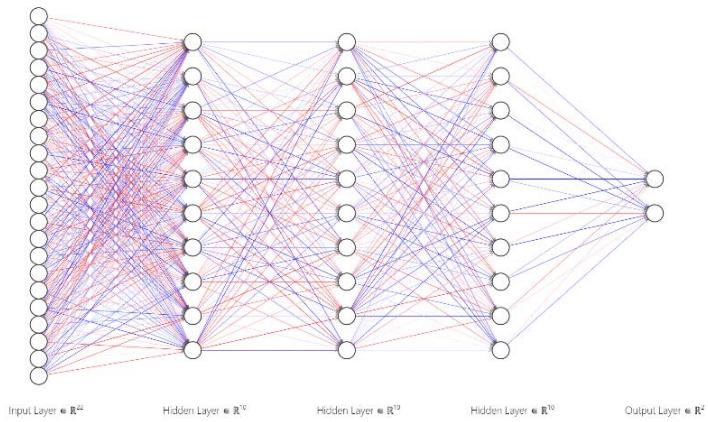
4. To load the pre-trained FCNN [9] model in Matlab Analysis module and to input the 22 data into the model for analysis to obtain the results. The model was trained using a publicly available dataset for Parkinson's Disease [10]. The Figure 5 shows the schematics of 3-Layer FCNN. Table 2 shows hyperparameters of 3-layer FCNN.
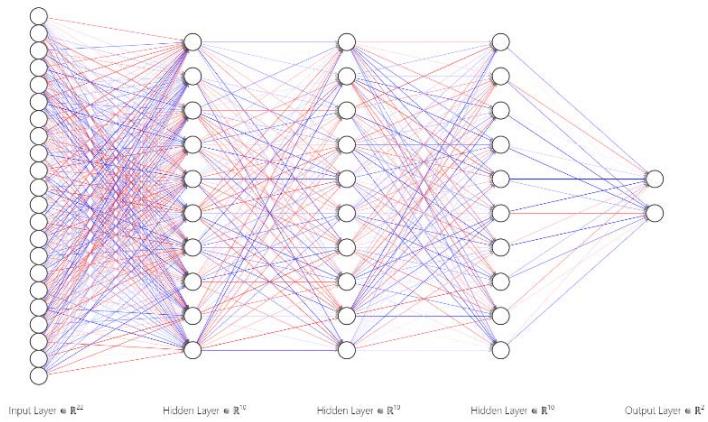 Figure 5: Schematics of 3-Layer FCNN
Table 2: Hyperparameters of 3-layer FCNN
<table><tr><td>Name</td><td>Hyperparameters</td></tr><tr><td>First Layer Size</td><td>10</td></tr><tr><td>Second Layer Size</td><td>10</td></tr><tr><td>Third Layer Size</td><td>10</td></tr><tr><td>Activation Function</td><td>ReLU</td></tr><tr><td>Iteration Limit</td><td>1000</td></tr><tr><td>Learning Rate</td><td>0.01</td></tr><tr><td>Learning Rate Update Algorithm</td><td>SGD</td></tr><tr><td>Regularization Strength (Lambda)</td><td>0</td></tr><tr><td>Standardize Data</td><td>Yes</td></tr></table>
In Thingspeak, store the result value to file1 in the voice channel, and then the phone reads the value of file1 in the voice channel.
## V. RESULTS AND DISCUSSION
The process begins with receiving the initial signal from the microphone, then the signal goes through a number of preprocessing stages, including high-frequency isolation, noise suppression and segmentation of the speech frame using a Hamming window. Key characteristics are then extracted from these processed data and compiled into datasets. These data sets are transmitted to a neural network for training and optimization of the model, visually represented in the figure as a multi-layered structure. The completion of training and optimization is the creation of a model file capable of classifying voice input data. The experiment was conducted on an international dataset [11]. The results of test experiments in the IV network for the diagnosis of PD in patients with speech changes are shown in Table 3.
Table 3: The data of test experiments for speech recognition
<table><tr><td>Набор данньх/
Показасти</td><td>Среедnia
Точ�数ь</td><td>Среедnia
Чувсантуль�数ь</td><td>Среедnia
F1 оменka</td><td>Точ�数ь
Тechироваши</td></tr><tr><td>бли по peчи_</td><td>92,95%</td><td>92,95%</td><td>92,95%</td><td>94,7%</td></tr></table>
The IoT network achieved $94.7\%$ accuracy in diagnosing Parkinson's disease based on speech data and an F1 score of $92.95\%$. On the same data set, one of the best indicators of foreign studies is $95.8\%$ [12], which indicates both good recognition results and the possibility of implementing an IV network for domestic PD diagnostics.
## VI. CONCLUSIONS
In summary, the IoT network efficiently collects voice data from PD patients, processes it to remove noise, extracts essential features, and utilizes a 3-layer FCNN model to provide probability-based diagnostic outcomes, offering a viable solution for the timely detection of Parkinson's disease. Our work underscores the pivotal role of the IoT advancing healthcare. By seamlessly connecting devices and systems, IoT not only enables remote diagnostics but also promotes patient empowerment, personalized medicine, and enhanced healthcare delivery.
An approach using machine learning, neural networks, signal processing, and the Internet of Things (IoT) technologies for early detection of Parkinson's disease is described. A model and algorithms for processing audio signals from patients studied for the likelihood of Parkinson's disease are presented. The Internet of Things network collects voice data from PD patients, processes it to eliminate noise, extracts important characteristics, and uses a three-level FCNN model to obtain probability-based diagnostic results, offering a solution for timely detection of Parkinson's disease.
2. This work highlights the role of the Internet of Things in the development of IT diagnostics of patients. Thanks to the wireless connection of devices, the IoT network not only provides remote diagnostics, but also helps to empower patients and doctors, staff and improve the quality of medical care. As a result of experiments on an international dataset in the IV
network, $94.7\%$ accuracy was achieved in diagnosing Parkinson's disease based on speech data.
Generating HTML Viewer...
References
12 Cites in Article
Peter Whitehouse (2019). Ethical issues in early diagnosis and prevention of Alzheimer disease.
Konstantina-Maria Giannakopoulou,Ioanna Roussaki,Konstantinos Demestichas (2022). Internet of Things Technologies and Machine Learning Methods for Parkinson’s Disease Diagnosis, Monitoring and Management: A Systematic Review.
U Vishniakou,Xia Yiwei (2023). IT Diagnostics of Parkinson’s Disease Based on the Analysis of Voice Markers and Machine Learning.
Navneet Upadhyay,Abhijit Karmakar (2015). Speech Enhancement using Spectral Subtraction-type Algorithms: A Comparison and Simulation Study.
M Dendrinos,S Bakamidis,G Carayannis (1991). Speech enhancement from noise: A regenerative approach.
Hussein Al-Barhan,Sinan Elyass,Thamir Saeed,Ghufran Hatem,Hadi Ziboon (2021). Modified Speech Separation Deep Learning Network Based on Hamming window.
Max Little,Patrick Mcsharry,Stephen Roberts,Declan Costello,Irene Moroz (2007). Exploiting Nonlinear Recurrence and Fractal Scaling Properties for Voice Disorder Detection.
S Pasha (2016). ThingSpeak based sensing and monitoring system for IoT with Matlab Analysis.
Tara Sainath,Oriol Vinyals,Andrew Senior,Hasim Sak (2015). Convolutional, Long Short-Term Memory, fully connected Deep Neural Networks.
M Little,P Mcsharry,E Hunter,J Spielman,L Ramig (2008). Suitability of Dysphonia Measurements for Telemonitoring of Parkinson's Disease.
(2024). Fig. 5. Fragment of the publication "St. Petersburg Necropolis" with the death date and burial place of Professor Ya. O. Sapolovich. National Electronic Library. Access mode: https://rusneb.ru/catalog/000199_000009_004011546/.
Betul Sakar,M Isenkul,C Sakar,Ahmet Sertbas,Fikret Gurgen,Sakir Delil,Hulya Apaydin,Olcay Kursun (2013). Collection and Analysis of a Parkinson Speech Dataset With Multiple Types of Sound Recordings.
No ethics committee approval was required for this article type.
Data Availability
Not applicable for this article.
How to Cite This Article
Uladzimir, Vishniakou. 2026. \u201cModels and Algorithms for the Diagnosis of Parkinsons Disease and Their Realization on the Internet of Things Network\u201d. Global Journal of Research in Engineering - J: General Engineering GJRE-J Volume 24 (GJRE Volume 24 Issue J1): .
Explore published articles in an immersive Augmented Reality environment. Our platform converts research papers into interactive 3D books, allowing readers to view and interact with content using AR and VR compatible devices.
Your published article is automatically converted into a realistic 3D book. Flip through pages and read research papers in a more engaging and interactive format.
This article aims to investigate an innovative approach utilizing model, algorithms and IoT technology for early Parkinson’s disease detection. It introduces the comprehensive IoT network that has the IoT platform, enabling the collection of voice data via mobile phones, extraction of relevant features and data processing. Within this process, a Fully Connected Neural Network (FCNN) model is employed to calculate the probability of Parkinson’s disease, potentially providing healthcare professionals and patients with a convenient, accurate, and early diagnostic tool. The study delves into the structure, algorithms, and the integral role of the FCNN within the IoT network, emphasizing its potential impact on the healthcare sector.
Our website is actively being updated, and changes may occur frequently. Please clear your browser cache if needed. For feedback or error reporting, please email [email protected]
Thank you for connecting with us. We will respond to you shortly.