We developed a new three-parameter extended inverse Lomax distribution called the Lehmann Type-2 inverse Lomax distribution. We demonstrated its superiority over the inverse Lomax distribution through various theoretical and practical approaches. The derived properties include the quantiles, moments, incomplete moments, entropy (Renyi and Tsallis), and order statistics. Finally, we consider two life-time data sets to show how the practitioner can take advantage of the new Type-2 inverse Lomax model. .
## I. INTRODUCTION
Over the last century, many significant distributions have been introduced to serve as models in applied sciences. The notable among them, generalized beta distribution developed by McDonald (1995), is at the top of the list in terms of usefulness. The main feature of the generalized beta distribution is that it introduces skewness and kurtosis into the baseline distribution that allows for modeling data of various forms of the shape of the hazard function which may be decreasing, increasing, decreasing-increasing, increasing decreasing, and inverted bathtub shapes. In this paper, we focus our attention on one of the most attractive of these distributions, known as the inverse Lomax $(IL)$ distribution. Mathematically, it can be presented in the distribution form as $\mathrm{Y} = X^{-1}$, where $\mathbf{X}$ is a random variable following the famous Lomax distribution (see Lomax, 1954). Thus, the cumulative distribution function (CDF) of the $IL$ distribution is given by
$$
G (x; \lambda , \rho) = \left(1 + \frac {\rho}{x}\right) ^ {- \lambda}, x > 0 \tag {1}
$$
$$
g(x;\lambda,\rho) = \lambda\rho x^{-2}\left(1+\frac{\rho}{x}\right)^{-\lambda-1},\,x>0
$$
where $\pmb{\rho}$ is a positive scale parameter and $\lambda$ is a positive shape parameter. The reasons for studying the IL distribution are not limited to the following: It has proved itself as a statistical model in various applications, including economics and actuarial sciences (see Kleiber and Kotz, (2003)) and geophysics (see McKenzie et al. (2004)). Also, the mathematical and inferential aspects of the IL distribution have been studied. See, for example, Lorenz (2004), for the Lorenz ordering of order statistics, Rahman and Aslam
(2013) studied the estimation of the parameters in a Bayesian setting, Yadav et al. (2016) examined the estimation of the parameters from hybrid censored samples, Singh et al. (2016) the study of the reliability estimator under type II censoring and Reyad, and Othman (2018) studied the Bayesian estimation of a two-component mixture of the IL distribution type I censoring. Despite an interesting compromise between simplicity and accuracy, the IL model suffers from a certain rigidity in the peak (punctual and roundness) and tail properties. This motivates the development of various parametric extensions, such as the inverse power Lomax distribution introduced by Hassan and Abd-Allah 92018), the Weibull IL distribution studied by Hassan, A.S.; Mohamed (2019) and, the Marshall-Olkin IL distribution developed by Maxwell et al. (2019). In this paper, we introduce and discuss a new extension of the IL distribution called Lehman Type-2 Inverse Lomax distribution which can model all forms of data exhibiting any shape of the hazard function because of its flexibility and tractability.
## II. LEHMANN TYPE-2 INVERSE LOMAX DISTRIBUTION
The CDF of the Lehmann type-2 family of distribution is given by
$$
F (x) = 1 - \left(1 - G (x)\right) ^ {b} \tag {3}
$$
And the associated PDF is given by
$$
f (x) = b g (x) \left(1 - G (x)\right) ^ {b - 1} \tag {4}
$$
Putting (3) and (4) in (2), we have an expression for the Lehmann Type-2 inverse Lomax (LT-2IL) distribution given by
$$
f (x; b, \lambda , \rho) = b \lambda \rho x ^ {- 2} \left(1 - \frac {\rho}{x}\right) ^ {- \lambda - 1} \left(1 - \left(1 + \frac {\rho}{x}\right) ^ {- \lambda}\right) ^ {b - 1}, x > 0 \tag {5}
$$
$$
F (x; b, \lambda , \rho) = 1 - \left(1 - \left(1 + \frac {\rho}{x}\right) ^ {- \lambda}\right) ^ {b}, \tag {6}
$$
The survival and the hazard function are respectively given by
$$
S (x; b, \lambda , \rho) = \left(1 - \left(1 + \frac {\rho}{x}\right) ^ {- \lambda}\right) ^ {b} \tag {7}
$$
$$
h (x; b, \lambda , \rho) = \frac{b \lambda \rho \left(1 - \frac{\rho}{x}\right) ^ {- \lambda - 1} \left(1 - \left(1 + \frac{\rho}{x}\right) ^ {- \lambda}\right) ^ {b - 1}}{x ^ {2} \left(1 - \left(1 + \frac{\rho}{x}\right) ^ {- \lambda}\right) ^ {b}}. \tag{8}
$$
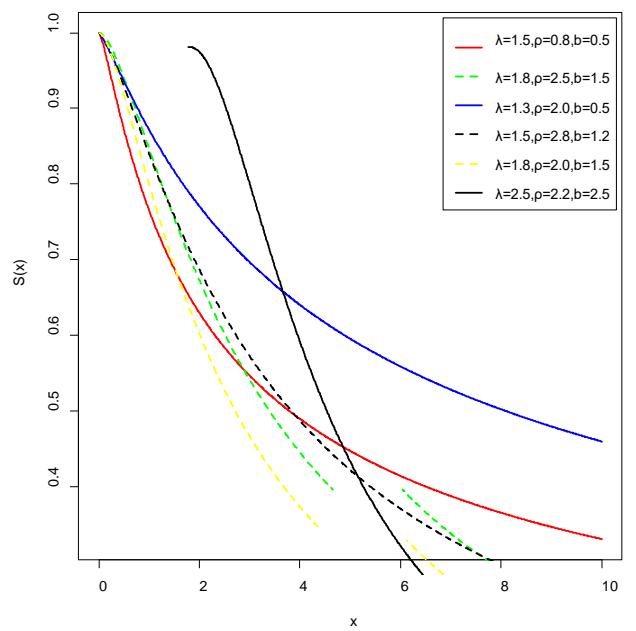
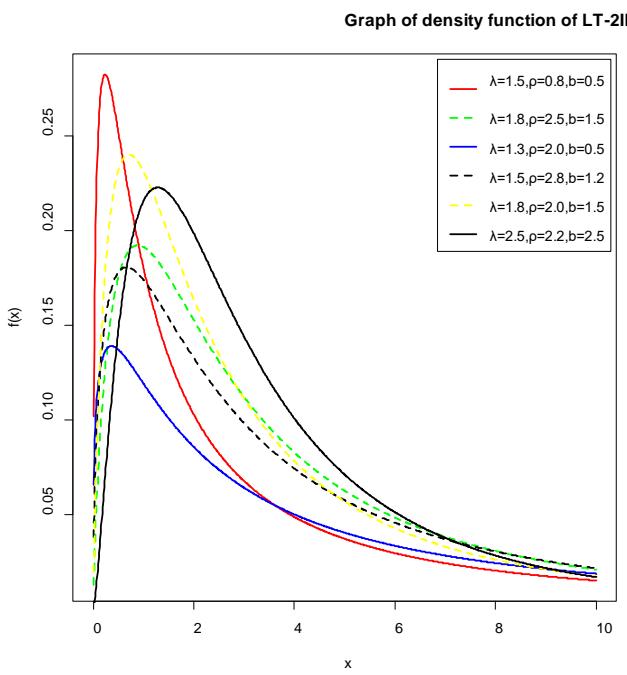
The graph of the density, hazard, and the survival function is given in figures 1, 2, and 3 for various values of the parameters.
 Notes
 Figure 1: The graph of the density function of LT-2IL distribution
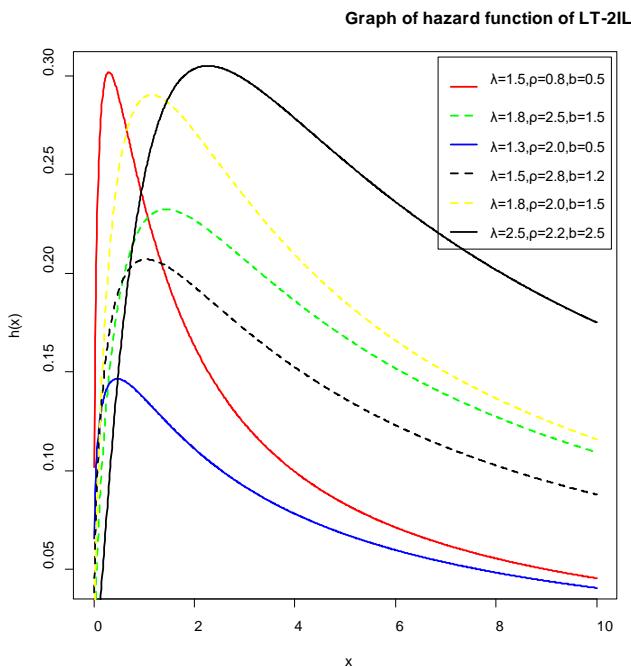
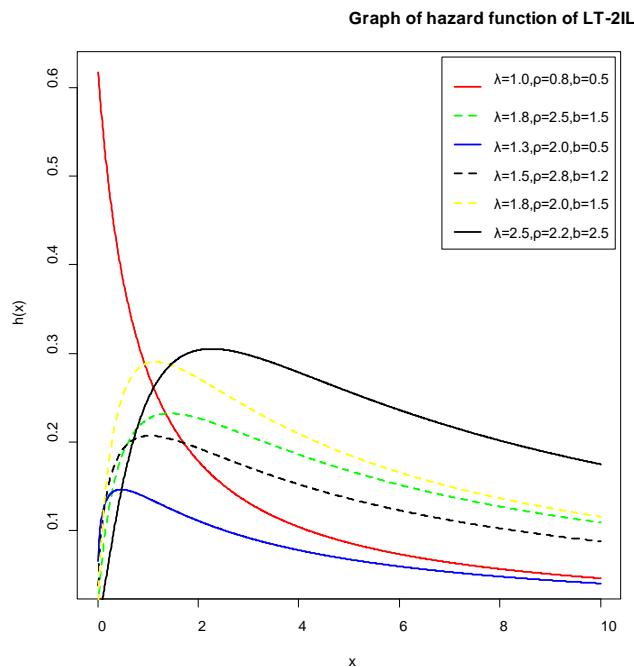 Figure 2: The graph of the hazard function of LT-2IL distribution
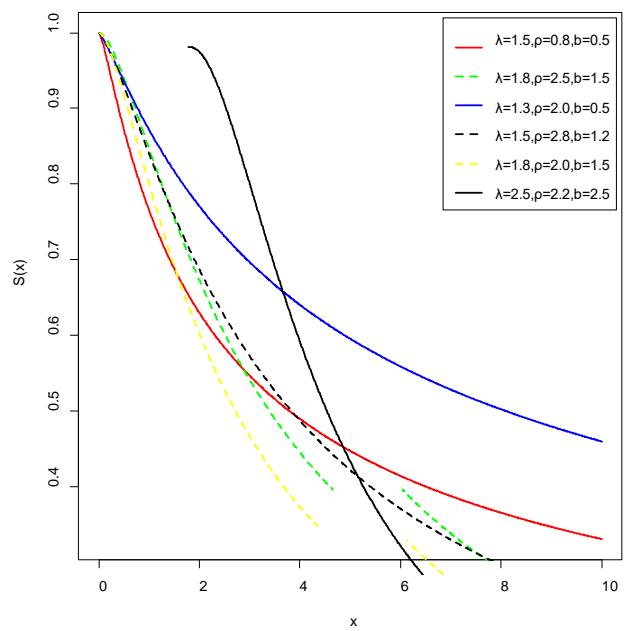 Graph of survival function of LT-2IL
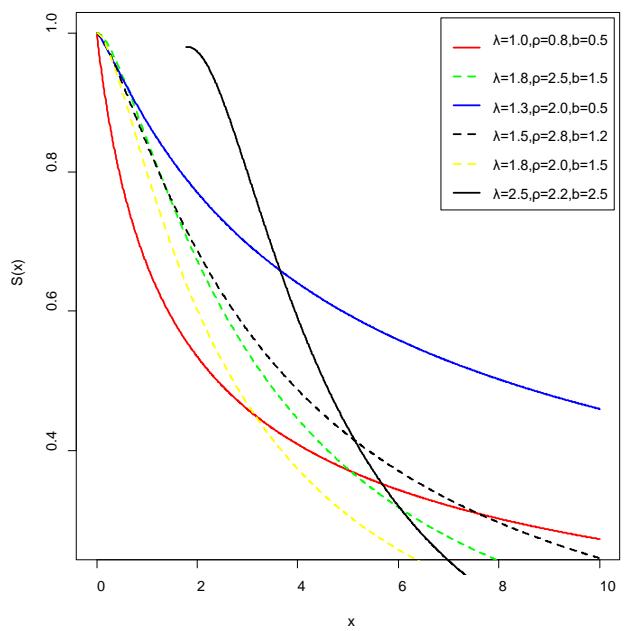 Graph of survival function of LT-2IL Figure 3: The graph of the survival function of $LT - 2IL$ distribution
## III. USEFUL EXPANSIONS
The binomial theorem, for$m > 0$and$|v| < 1$, can be expressed as follows:$(1 - v)^{m} = \sum_{i=0}^{\infty} (-1)^{i} \binom{m}{i} v^{i} \tag{9}$
$$
(1 - v) ^ {m} = \sum_ {i = 0} ^ {\infty} (- 1) ^ {i} \binom {m} {i} v ^ {i} \tag {9}
$$
Then, applying the binomial series expansion given in (9) to (5), we have
$$
\left(1 - \left(1 + \frac{\rho}{x}\right)^{-\lambda}\right)^{b-1} = \sum_{i=0}^{\infty} (-1)^{i} \binom{b-1}{i} \left(1 + \frac{\rho}{x}\right)^{-\lambda i}
$$
Finally, we have
$$
f(x) = b\lambda\rho x^{-2} \sum_{i=0}^{\infty} (-1)^{i} \binom{b-1}{i} \left(1 + \frac{\rho}{x}\right)^{-[\lambda(i+1)+1]}
$$
Equation (10) represents the Exponentiated Inverse Lomax distribution, with shape parameter $[\lambda (i + 1) + 1]$ and scale parameter $\rho$. It then follows that the properties of Lehmann type-2 inverse Lomax distribution can be obtained from that of the Exponentiated inverse Lomax distribution.
### a) Quantile function
The quantile function of the $LT - 2IL$ distribution is defined by $Q(u; b, \lambda, \rho) = F^{-1}(u; b, \lambda, \rho)$, $u \in (0,1)$. After some mathematical manipulations, we obtain
$$
Q (u; b, \lambda , \rho) = \rho \left\{\left[ 1 - (1 - u) ^ {1 / b} \right] ^ {- 1 / \lambda} - 1 \right\}, u \in (0, 1) \tag {10.1}
$$
From (10.1), we can obtain the lower quartile $(q_{1})$, middle quartile $(q_{2})$, also known as the median, and the upper quartiles $(q_{3})$ of the $LT - 2IL$ distribution by taking the values of $u$ to be 0.25, 0.5, and 0.75 respectively. Then, we obtain an equation for the lower quartile, median, and the upper quartile of $LT - 2IL$ distribution given respectively, by
$$
Q (0. 2 5; b, \lambda , \rho) = \rho \left\{\left[ 1 - (0. 7 5) ^ {1 / b} \right] ^ {- 1 / \lambda} - 1 \right\}, \tag {10.2}
$$
$$
Q (0. 5; b, \lambda , \rho) = \rho \left\{\left[ 1 - (0. 5) ^ {1 / b} \right] ^ {- 1 / \lambda} - 1 \right\} \tag {10.3}
$$
and
$$
Q (0. 7 5; b, \lambda , \rho) = \rho \left\{\left[ 1 - (0. 2 5) ^ {1 / b} \right] ^ {- 1 / \lambda} - 1 \right\} \tag {10.4}
$$
### b) Moments of LT - 2IL distribution
The $k^{th}$ moment of the $LT - 2IL$ distribution under certain regularity conditions; the $k^{th}$ moment of TIIHLF distribution is obtained as
$$
\mu_{k}^{\prime} = \int_{-\infty}^{\infty} x^{k} f(x) \, dx = b\lambda\rho x^{-2} \sum_{i=0}^{\infty} (-1)^{i} \binom{b-1}{i} W(x) \tag{11}
$$
where
$$
W (x) = \int_ {- \infty} ^ {\infty} x ^ {k - 2} \left(\mathbf {1} + \frac {\rho}{x}\right) ^ {- [ \lambda (i + 1) + 1 ]} d x \tag {12}
$$
Taking $z = \frac{\rho}{x}$ and putting it in (12), we have
$$
W (x) = - \rho^ {k - 1} \int_ {- \infty} ^ {\infty} z ^ {2 - k} (1 + z) ^ {- [ \lambda (i + 1) + 1 ]} d z \tag {13}
$$
Also, letting $y = \frac{v}{1 - v}$, $dy = (1 - v)^{-2} dv$ and putting it in (13), we have
$$
W (x) = \rho^ {k - 1} \int_ {0} ^ {1} v ^ {2 - r} (1 - v) ^ {k + \lambda (i + 1) - 3} \tag {14}
$$
$$
W (x) = \rho^ {k - 1} B [ 1 - k, k + \lambda (\pmb {i} + \pmb {1}) - 2 ]
$$
Finally, we obtain an expression for the $k^{th}$ moment of the $LT - 2IL$ distribution given as
$$
\mu_{k}^{\prime} = b\lambda\sum_{i=0}^{\infty}(-1)^{i}\binom{b-1}{i}\rho^{k}B\left[1-k,k+\lambda(i+1)-2\right]
$$
Where $B(.,.)$ is a beta function
An expression for the first, second and third moments can be obtained by respectively taking the value of $k = 1,2$ and 3 as
$$
\mu_ {1} ^ {\prime} = b \lambda \sum_ {i = 0} ^ {\infty} (- 1) ^ {i} \binom {b - 1} {i} \rho B [ \lambda (i + 1) - 1 ], \tag {16}
$$
$$
\mu_ {2} ^ {\prime} = b \lambda \sum_ {i = 0} ^ {\infty} (- 1) ^ {i} \binom {b - 1} {i} \rho^ {2} B [ - 1, \boldsymbol {\lambda} (\boldsymbol {i} + \mathbf {1}) ] \tag {17}
$$
And
$$
\mu_ {3} ^ {\prime} = b \lambda \sum_ {i = 0} ^ {\infty} (- 1) ^ {i} \binom{b - 1} {i} \rho^ {3} B [ - 2, 1 + \lambda (i + 1) ] \tag{18}
$$
### c) Incomplete moments of LT-2IL distribution
The incomplete moment of LT-2IL distribution can be obtained using (13) as
$$
\mu_{k}^{ extprime} = \int_{-\infty}^{\infty} x^{k} f(x) dx = b\lambda\rho x^{-2} \sum_{i=0}^{\infty} (-1)^{i} \binom{b-1}{i} W(x) \tag{16}
$$
where
$$
W (x) = \int_ {0} ^ {t} x ^ {k - 2} \left(\mathbf {1} + \frac {\rho}{x}\right) ^ {- [ \lambda (i + 1) + 1 ]} d x \tag {17}
$$
Taking $z = \frac{\rho}{x}$ and putting it in (17), we have
$$
W (x) = - \rho^ {k - 1} \int_ {0} ^ {t} z ^ {2 - k} (\mathbf {1} + \mathbf {z}) ^ {- [ \lambda (i + 1) + 1 ]} d z \tag {18}
$$
Also, letting $y = \frac{v}{1 - v}$, $dy = (1 - v)^{-2} dv$ and putting it in (18), we have
$$
W (x) = \rho^ {k - 1} \int_ {0} ^ {1} v ^ {2 - r} (1 - v) ^ {k + \lambda (i + 1) - 3} \tag {19}
$$
Then we have
$$
W (x) = \rho^ {k - 1} B _ {\rho / t + \rho} [ 1 - k, k + \lambda (i + 1) - 2 ] \tag {20}
$$
Finally, we obtain an expression for the $k^{th}$ incomplete moment of the $LT - 2IL$ distribution given as
$$
\mu_ {k} ^ {\prime} = b \lambda \sum_ {i = 0} ^ {\infty} (- 1) ^ {i} \binom {b - 1} {i} \rho^ {k} B _ {\rho / t + \rho} [ 1 - k, k + \boldsymbol {\lambda} (\boldsymbol {i} + \mathbf {1}) - \mathbf {2} ] \tag {21}
$$
$$
\mu_ {1} ^ {\prime} = b \lambda \sum_ {i = 0} ^ {\infty} (- 1) ^ {i} \binom{b - 1} {i} \rho^ {k} B _ {\rho / t + \rho} [ 1 - k, k + \lambda (\pmb{i} + \mathbf{1}) - \mathbf{2} ] \tag{22}
$$
### d) Renyi entropy
Renyi entropy was proposed by Renyi (1961). It can be obtained by
$$
I _ {\varphi} (x) = \frac {1}{1 - \varphi} \log M \tag {28}
$$
Where
$$
M = \int_ {- \infty} ^ {\infty} f ^ {\varphi} (x) d x, \quad \varphi > 0, \varphi \neq 1 \tag {29}
$$
Putting (5) in (28) followed by binomial expansion, we have
$$
M = (b \lambda \rho) ^ {\varphi} \sum_ {i = 0} ^ {\infty} (- 1) ^ {i} \binom {\varphi (b - 1)} {i} \int_ {- \infty} ^ {\infty} x ^ {2} \left(1 + \frac {\rho}{x}\right) ^ {[ \lambda (\varphi - 1) + \varphi ]} d x \tag {30}
$$
Taking $y = \frac{\rho}{x}$, $dx = -\rho y^{-2} dy$, putting it in (30), we have
$$
M = (b\lambda)^{\varphi} \rho^{2 + \varphi} \sum_{i=0}^{\infty} (-1)^{i} \binom{\varphi (b - 1)}{i} \int_{0}^{\infty} y^{-2} (1 + y)^{[\lambda (\varphi - 1) + \varphi]} dy,
$$
Furthermore, by letting $y = \frac{u}{1 - u}$, $dw = (1 - u)^{-2}du$ and putting it in (31) gives
$$
M = (b \lambda) ^ {\varphi} \rho^ {2 + \varphi} \sum_ {i = 0} ^ {\infty} (- 1) ^ {i} \binom {\varphi (b - 1)} {i} \int_ {0} ^ {\infty} u ^ {- 2} (1 - u) - ^ {[ \lambda (\varphi - 1) + \varphi ]} d y \tag {32}
$$
$$
M = (b \lambda) ^ {\varphi} \rho^ {2 + \varphi} \sum_ {i = 0} ^ {\infty} (- 1) ^ {i} \binom {\varphi (b - 1)} {i} B [ - 1, 1 - [ \lambda (\varphi - \mathbf {1}) + \varphi ]
$$
Finally, we have an expression for the Renyi entropy of LT-2IL distribution as
$$
I _ {\varphi} (x) = \frac {1}{1 - \varphi} \log \left[ (b \lambda) ^ {\varphi} \rho^ {2 + \varphi} \sum_ {i = 0} ^ {\infty} (- 1) ^ {i} \binom {\varphi (b - 1)} {i} B [ - 1, 1 - [ \lambda (\varphi - \mathbf {1}) + \varphi ] \right]
$$
### e) Tsallis Entropy
The Tsallis entropy, also known as $\beta$ -entropy, was first discovered by Havrada and Charvat (1967) and later developed by Tsallis (1988). The Tsallis entropy of the LT-2IL distribution can be defined as
$$
I _ {T} ^ {(\varphi)} = \frac {1}{\varphi - 1} \left[ 1 - \int_ {- \infty} ^ {\infty} f (x; b, \rho , \lambda) ^ {\varphi} \right], \quad \varphi > 0, \varphi \neq 1 \tag {33}
$$
Invariably, it may be written as
$$
I_{T}^{(\varphi)} = \frac{1}{\varphi - 1} [1 - M^{\varphi}], \quad \varphi > 0, \varphi \neq 1
$$
Putting (29) in (32), we obtain an expression for the Tsallis entropy given as
$$
I _ {T} ^ {(\varphi)} = \frac {1}{\varphi - 1} \left[ 1 - (b \lambda) ^ {\varphi} \rho^ {2 + \varphi} \sum_ {i = 0} ^ {\infty} (- 1) ^ {i} \binom {\varphi (b - 1)} {i} B [ - 1, 1 - [ \lambda (\varphi - \mathbf {1}) + \varphi ] \right] \quad (3 5)
$$
### f) Order statistics
Let $X$ be a random variable from the KGIL distribution and, given a random sample size $n$ from $X$, say say $X_{1},\ldots,X_{n}$, let $x_{i:n}$ be the $i^{th}$ order statistic such that $x_{1:n}\leq x_{2:n}\leq x_{3:n}\leq \dots \leq x_{n:n}$, given that $x_{h:n}\in \{X_1,\ldots,X_n\}$ for $h = 1,\ldots,n$. In particular, the study of order statistics is very important since naturally it appears in many applications, majorly those involving systems comprises of several components parts that can fail independently of each other. The density of $x_{i:n}$ is given by
$$
f _ {i: n} (x; \cdot) = \frac {n !}{(i - 1) (n - i)} F (x; b, \rho , \lambda) ^ {i - 1} R (x; b, \rho , \lambda) ^ {n - 1} f (x; b, \rho , \lambda), x > 0 \tag {36}
$$
Applying binomial theorem given in (36) to the expression above, it follows immediately that
$$
f _ {i: n} (x) = \frac {n !}{(i - 1) (n - i)} \sum_ {j = 0} ^ {i - 1} {\binom {i - 1} {j}} (- 1) ^ {j} R (x; b, \rho , \lambda) ^ {j + n - 1} f (x; b, \rho , \lambda), x > 0 \tag {37}
$$
Putting (5) and (7) in (37) gives us the following series expansion for the $i^{th}$ order statistics for $LT - 2IL$ distribution as
$$
f_{i:n}(x) = \frac{n!\,b\lambda\rho\,x^{-2}}{(i-1)(n-i)} \sum_{j=0}^{i-1} \binom{i-1}{j} (-1)^{j} \left[ \left(1 - \left(1 + \frac{\rho}{x}\right)^{-\lambda}\right)^{b} \right]^{b+j+n-2} \left(1 + \frac{\rho}{x}\right)^{-\lambda-1}
$$
It should be noted that from (38) an expression for the smallest and the largest order statistics can be obtained.
## IV. MAXIMUM LIKELIHOOD ESTIMATION (MLE) METHOD
Taking an observed sample $x_{1},\ldots,x_{n}$ from the $LT - 2IL$ distribution, the corresponding likelihood function can be represented as
$$
\begin{array}{l} L (b, \boldsymbol {\lambda}, \boldsymbol {\rho}) = \prod_ {i = 1} ^ {n} f \left(x _ {i}: b, \boldsymbol {\lambda}, \boldsymbol {\rho}\right) \tag {39} \\= \prod_ {i = 1} ^ {n} b \lambda \rho x ^ {- 2} \left(1 - \frac {\rho}{x}\right) ^ {- \lambda - 1} \left(1 - \left(1 + \frac {\rho}{x}\right) ^ {- \lambda}\right) ^ {b - 1} \\\end{array}
$$
The MLEs of $p, q, \beta$, and $\lambda$ are denoted by $\hat{b}, \hat{\pmb{p}}$, and $\hat{\lambda}$, respectively. The log-likelihood function is given by
$$
l = n l o g (b \lambda \pmb {\rho}) - (\lambda + \mathbf {1}) \sum_ {i = 1} ^ {n} l o g \left(\mathbf {1} + \frac {\pmb {\rho}}{\pmb {x} _ {i}}\right) + (b - 1) \sum_ {i = 1} ^ {n} l o g \left(1 - \left(\mathbf {1} + \frac {\pmb {\rho}}{\pmb {x} _ {i}}\right) ^ {- \lambda}\right) \qquad (4 0)
$$
And the element of the score vector is given by
$$
\frac {\partial l}{\partial b} = \frac {n}{b} + \sum_ {i = 1} ^ {n} \log \left(1 - \left(\mathbf {1} + \frac {\boldsymbol {\rho}}{x _ {i}}\right) ^ {- \lambda}\right) \tag {41}
$$
$$
\frac{\partial l}{\partial \rho} = \frac{n}{\rho} - (\lambda + \mathbf{1}) \sum_ {i = 1} ^ {n} \left[ \frac{\left(\mathbf{1} - \frac{1}{x _ {i}}\right)}{\left(\mathbf{1} - \frac{\rho}{x _ {i}}\right)} \right] + \lambda (b - 1) \sum_ {i = 1} ^ {n} \left[ \frac{\left(\mathbf{1} + \frac{1}{x _ {i}}\right) ^ {- \lambda - \mathbf{1}}}{\left(1 - \left(\mathbf{1} + \frac{\rho}{x _ {i}}\right) ^ {- \lambda}\right)} \right] \tag{42}
$$
$$
\frac {\partial l}{\partial \lambda} = \frac {n}{\lambda} - \sum_ {i = 1} ^ {n} \log \left(\mathbf {1} + \frac {\boldsymbol {\rho}}{\mathbf {x} _ {i}}\right) + (b - 1) \sum_ {i = 1} ^ {n} \left[ \frac {\left(\mathbf {1} + \frac {\boldsymbol {\rho}}{x _ {i}}\right) ^ {- \lambda} \log \left(\left(\mathbf {1} + \frac {\boldsymbol {\rho}}{x _ {i}}\right)\right)}{\left(1 - \left(\mathbf {1} + \frac {\boldsymbol {\rho}}{x _ {i}}\right) ^ {- \lambda}\right)} \right] \tag {43}
$$
## V. APPLICATIONS
In this section, two life-time data sets are provided to illustrate the importance of the $LT - 2IL$ distribution in modeling life-time data. We compare the $LT - 2IL$ model with other competitive models such as Kumaraswamy inverse Lomax (KIL), Kumaraswamy Frechet (KF), Exponentiated Lomax (EL), and the inverse Lomax (IL) distribution.
To check the adequacy of the fitted model in fitting the data considered, Akaike information criterion (AIC), consistent Akaike information criterion (CAIC), Bayesian information criterion (BIC), Kolmogorov-Smirnov(KS), Crammer-Von Misses (CM), Anderson Darling(AD) goodness of fit test and its p-value (PV) are obtained. In general, it is considered that the smaller the values of AIC, BIC, CAIC, HQIC and, K statistics and the larger the p-value, the better the fit of the model.
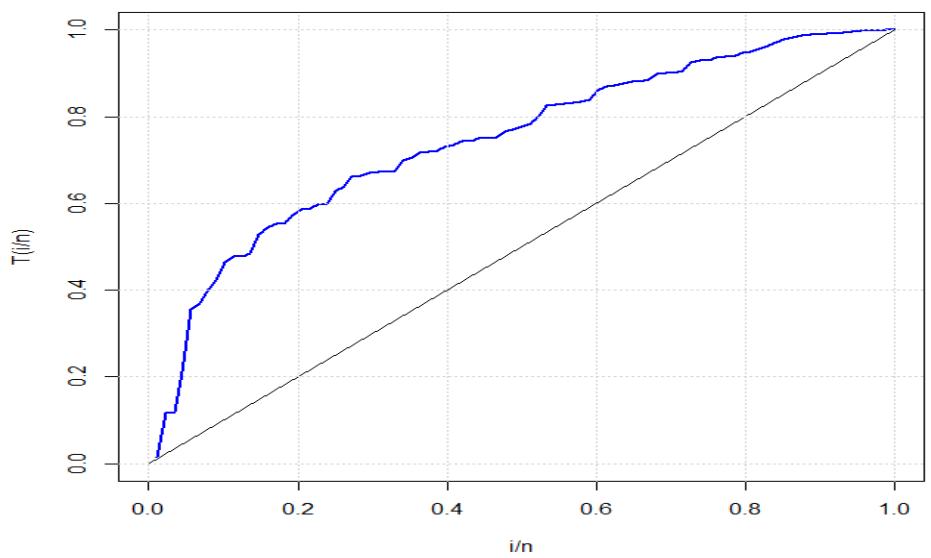 Figure 4: Graph of the total time on test plot for Jet air conditioning data
Table 1: MLEs and standard errors in braces for the first data set
<table><tr><td>Model</td><td>λ</td><td>ρ</td><td>b</td><td>a</td></tr><tr><td>LT-2IL</td><td>1.247(0.199)</td><td>125.111(77.185)</td><td>2.7769(0.961)</td><td>-(-)</td></tr><tr><td>EL</td><td>0.6547(0.161)</td><td>1.2489(0.368)</td><td>15.558(4.407)</td><td>-(-)</td></tr><tr><td>KIL</td><td>0.7724(18.669)</td><td>144.4729(101.187)</td><td>1.565(37.835)</td><td>3.0006(1.204)</td></tr><tr><td>KF</td><td>0.6137(0.110)</td><td>0.6451(0.1625)</td><td>8.8399(1.675)</td><td>5.001(1.353)</td></tr><tr><td>IL</td><td>2.0790(0.395)</td><td>18.822(4.938)</td><td>-(-)</td><td>-(-)</td></tr></table>
Table 2: AIC, BIC, CAIC, CM, AD KS statistic, and P- value (PV) for first data set
<table><tr><td>Model</td><td>-1</td><td>AIC</td><td>BIC</td><td>CAIC</td><td>CM</td><td>AD</td><td>KS</td><td>PV</td></tr><tr><td>LT - 2IL</td><td>1034.77</td><td>2075.54</td><td>2085.25</td><td>2075.68</td><td>0.057</td><td>0.415</td><td>0.050</td><td>0.736</td></tr><tr><td>EL</td><td>1054.88</td><td>2115.77</td><td>2125.48</td><td>2115.90</td><td>0.357</td><td>2.393</td><td>0.089</td><td>0.099</td></tr><tr><td>KIL</td><td>1034.74</td><td>2077.69</td><td>2090.42</td><td>2077.69</td><td>0.061</td><td>0.433</td><td>0.049</td><td>0.741</td></tr><tr><td>KF</td><td>1039.52</td><td>2087.03</td><td>2099.98</td><td>2087.25</td><td>0.115</td><td>0.842</td><td>0.052</td><td>0.687</td></tr><tr><td>IL</td><td>1044.10</td><td>2092.20</td><td>2098.67</td><td>2092.26</td><td>0.173</td><td>1.175</td><td>0.068</td><td>0.343</td></tr></table>
The second data sets have been obtained from Murthy et al. (2004) is about the failure times of windshields and is given by 0.04, 0.3, 0.31, 0.557, 0.943, 1.07, 1.124, 1.248, 1.281, 1.281, 1.303, 1.432, 1.48, 1.51, 1.51, 1.568, 1.615, 1.619, 1.652, 1.652, 1.757, 1.795, 1.866, 1.876, 1.899, 1.911, 1.912, 1.9141, 0.981, 2.010, 2.038, 2.085, 2.089, 2.097, 2.135, 2.154, 2.190, 2.194, 2.223, 2.224, 2.23, 2.3, 2.324, 2.349, 2.385, 2.481, 2.610, 2.625, 2.632, 2.646, 2.661, 2.688, 2.823, 2.89, 2.9, 2.934, 2.962, 2.964, 3, 3.1, 3.114, 3.117, 3.166, 3.344, 3.376, 3.385, 3.443, 3.467, 3.478, 3.578, 3.595, 3.699, 3.779, 3.924, 4.035, 4.121, 4.167, 4.240, 4.255, 4.278, 4.305, 4.376, 4.449, 4.485, 4.570, 4.602, 4.663, 4.694. Some descriptive statistics for these data shows that the smallest and the largest values are 0.04 and 4.694, respectively. Further, the mean, median and variance are 2.569, 2.367 and 1.286, respectively. The Total time on test plot for the windshield data set is given in figure 4. The parameter estimates and the values for the goodness of fit test for the model is given in Table 3 and 4 respectively.
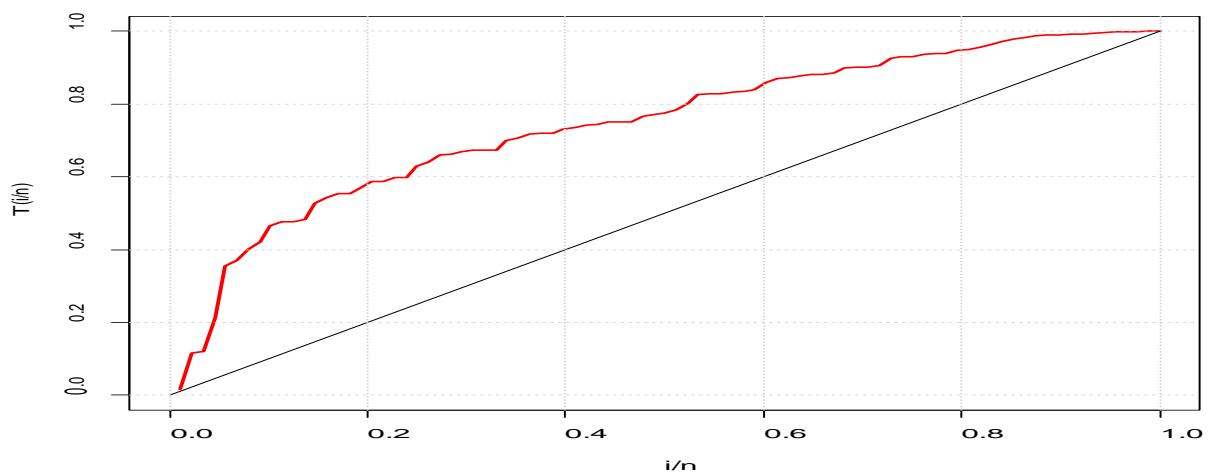 Figure 5: Graph of the total time on test plot for the second data
Table 3: MLEs and standard errors in braces for the second data set
<table><tr><td>Model</td><td>λ</td><td>ρ</td><td>b</td><td>a</td></tr><tr><td>LT-2IL</td><td>2.591(0.319)</td><td>16.442(8.468)</td><td>142.560(111.761)</td><td>-(-)</td></tr><tr><td>EL</td><td>1.584(0.351)</td><td>1.1683(0.348)</td><td>3.428(1.143)</td><td>-(-)</td></tr><tr><td>KIL</td><td>1.549(0.939)</td><td>4.3495(1.485)</td><td>1.939(1.176)</td><td>16.1458(5.434)</td></tr><tr><td>KF</td><td>0.7820(0.305)</td><td>1.0205(0.588)</td><td>7.163(3.946)</td><td>13.3993(8.685)</td></tr><tr><td>IL</td><td>4.123(1.321)</td><td>0.490(0.184)</td><td>-(-)</td><td>-(-)</td></tr></table>
Table 4: AIC, BIC, CAIC, CM, AD, KS statistic and P- value (PV) for the second data set
<table><tr><td>Model</td><td>-1</td><td>AIC</td><td>BIC</td><td>CAIC</td><td>CM</td><td>AD</td><td>KS</td><td>PV</td></tr><tr><td>LT - 2IL</td><td></td><td>283.93</td><td>291.07</td><td>283.94</td><td>0.064</td><td>0.668</td><td>0.057</td><td>0.929</td></tr><tr><td>EL</td><td>166.92</td><td>339.84</td><td>347.27</td><td>340.13</td><td>0.705</td><td>4.571</td><td>0.169</td><td>0.013</td></tr><tr><td>KIL</td><td>143.95</td><td>295.89</td><td>305.80</td><td>296.38</td><td>0.137</td><td>1.203</td><td>0.094</td><td>0.408</td></tr><tr><td>KF</td><td>150.68</td><td>309.83</td><td>319.26</td><td>309.83</td><td>0.272</td><td>2.078</td><td>0.121</td><td>0.152</td></tr><tr><td>IL</td><td>187.02</td><td>378.05</td><td>383.0</td><td>378.19</td><td>0.825</td><td>5.233</td><td>0.336</td><td>4.6e - 09</td></tr></table>
It could be observed from the results obtained from the two data sets considered that the Lehmann Type-2 Inverse Lomax model possesses the smallest AIC, BIC, CAIC, CM, AD, KS statistic and, the largest of a P-value. It could therefore be regarded as the best model in the class of the models considered based on the data used.
## VI. CONCLUDING REMARKS
In this paper, we developed a study a novel three-parameter distribution called Lehmann-type-2 Inverse distribution. Some statistical properties of the new distribution are studied. The maximum likelihood estimation method is used to obtain the parameters. Two real data sets are presented to illustrate the applicability of the new model.
Generating HTML Viewer...
References
16 Cites in Article
Gauss Cordeiro,Artur Lemonte (2011). The <mml:math xmlns:mml="http://www.w3.org/1998/Math/MathML" altimg="si38.gif" display="inline" overflow="scroll"><mml:mi>β</mml:mi></mml:math>-Birnbaum–Saunders distribution: An improved distribution for fatigue life modeling.
James Mcdonald,Yexiao Xu (1995). A generalization of the beta distribution with applications.
K Lomax (1954). Business Failures: Another Example of the Analysis of Failure Data.
Christian Kleiber,Samuel Kotz (2003). Statistical Size Distributions in Economics and Actuarial Sciences.
D Mckenzie,C Miller,D Falk (2011). The Landscape Ecology of Fire.
C Kleiber (2004). Lorenz ordering of order statistics from log-logistic and related distributions.
Shujiao Huang,Broderick Oluyede (2014). Exponentiated Kumaraswamy-Dagum distribution with applications to income and lifetime data.
Jafer Rahman,Muhammad Aslam (2013). On estimation of two-component mixture inverse Lomax model via Bayesian approach.
A Yadav,S Singh,U Singh (2016). On hybrid censored inverse Lomax distribution: Application to the survival data.
Sanjay Singh,Umesh Singh,Abhimanyu Yadav (2016). Bayesian estimation of Lomax distribution under type-II hybrid censored data using Lindley's approximation method.
H Reyad,S Othman (2018). E-Bayesian estimation of two-component mixture of inverse Lomax distribution based on type-I censoring scheme.
Amal Hassan,Marwa Abd-Allah (2018). On the Inverse Power Lomax Distribution.
A Hassan,R Mohamed (2019). Weibull inverse Lomax distribution.
Obubu Maxwell,Angela Chukwu,Oluwafemi Oyamakin,Mundher Khaleel (2019). The Marshall-olkin Inverse Lomax Distribution (MO-ILD) with Application on Cancer Stem Cell.
D Murthy,M Xie,R Jiang (2004). Weibull Models.
Constantino Tsallis (1988). Possible generalization of Boltzmann-Gibbs statistics.
Explore published articles in an immersive Augmented Reality environment. Our platform converts research papers into interactive 3D books, allowing readers to view and interact with content using AR and VR compatible devices.
Your published article is automatically converted into a realistic 3D book. Flip through pages and read research papers in a more engaging and interactive format.
Our website is actively being updated, and changes may occur frequently. Please clear your browser cache if needed. For feedback or error reporting, please email [email protected]
Thank you for connecting with us. We will respond to you shortly.