The banking sector presents unique challenges for Site Reliability Engineering practices due to stringent regulatory requirements, complex technical environments, and zero-tolerance for financial data errors. This article explores the critical balance between automation capabilities and human expertise in maintaining reliable banking applications. It examines the distinctive reliability requirements of financial systems, identifies effective automation strategies within regulatory constraints, articulates the irreplaceable components of human judgment, and proposes an implementation framework for optimal collaboration between automated systems and human operators. Through detailed analysis of bankingspecific failure modes, monitoring approaches, and incident response workflows, the article provides a structured approach to developing SRE practices that leverage both technological capabilities and human cognitive strengths while respecting the unique constraints of financial environments. The framework presented enables banking institutions to implement reliability practices that maintain transaction integrity, meet regulatory obligations, and support business objectives through carefully designed human-automation systems.
## I. INTRODUCTION
Within banking technology operations, Site Reliability Engineering confronts exceptional demands unlike those in standard commercial domains. Disruptions to financial technology infrastructure generate consequences transcending basic service interruptions to potentially undermine economic functions, institutional credibility, and compliance postures. Banking platforms necessitate reliability protocols where continuous operation represents a baseline expectation rather than an optimization target. Modern financial enterprises navigate contradictory imperatives-ensuring maximum service continuity while undertaking substantial digital modernization-creating operational tensions where conventional reliability techniques demonstrate inadequacy [1]. These organizations shoulder responsibility for maintaining perpetual availability across intricate technological ecosystems handling extraordinary transaction loads, where each financial interaction demands absolute computational accuracy alongside adherence to elaborate governance stipulations.
The technological architecture underlying banking operations magnifies reliability complexities exponentially. Financial enterprises typically maintain diverse infrastructure where newly-developed distributed services must interface flawlessly with established core processing systems developed in previous technological eras. This architectural diversity generates specialized failure patterns at system integration boundaries while simultaneously complicating comprehensive visibility throughout transaction processing pathways. Banking technology resilience frameworks incorporate additional dimensions beyond typical reliability practices, encompassing specific protections addressing financial exposure management, jurisdictional data requirements, and transaction verification protocols uniquely critical to financial services [1]. Such sector-specific operational requirements render generic reliability automation techniques potentially unsuitable without substantial modification to accommodate financial industry particulars.
The pivotal challenge within banking reliability engineering involves establishing precise boundaries separating automated response mechanisms from human intervention points. Despite automation providing essential consistency and instantaneous responses necessary for financial transaction volumes, human expertise remains irreplaceable when confronting atypical system behaviors potentially threatening broader financial ecosystems. This delicate equilibrium becomes acutely important during service degradation scenarios, where automated correction measures require careful supervision to prevent potential multiplication of failures across interconnected financial networks. Banking technology environments necessitate customized reliability methodologies incorporating specialized performance thresholds and availability targets accounting for regulatory mandates and business considerations beyond the interpretive capacity of current automated systems [2].
Subsequent sections examine tactical approaches for establishing optimal coordination between automated mechanisms and human expertise within banking reliability operations. Following chapters explore current reliability engineering methodologies in financial platforms, evaluate automation strategies compatible with regulatory constraints, identify crucial human expertise components, and propose implementation architectures designed specifically for banking applications. Through practical guidance for developing resilient banking infrastructure effectively balancing technological automation with human judgment within financial service limitations, this technical discussion offers reliability practitioners actionable principles for addressing multifaceted operational requirements characteristic of contemporary banking platforms while preserving appropriate balance between computational efficiency and essential human oversight [2].
## II. CURRENT STATE OF BANKING SRE
Banking sector technology operations incorporate reliability engineering methodologies under exceptionally demanding operational constraints that define their functional parameters. Central among these constraints stands the absolute requirement for uninterrupted transaction processing capabilities, where brief service lapses potentially trigger substantial monetary impacts alongside heightened regulatory attention. Contemporary financial platforms must guarantee perfect informational consistency throughout geographically distributed infrastructure while simultaneously handling parallel transactions originating from diverse access points including smartphone applications, browser interfaces, physical terminal networks, and institutional settlement mechanisms. Such operational complexity demands advanced technical resilience strategies incorporating redundant active processing centers, granular transaction recording systems, and purpose-built database synchronization techniques specifically engineered for financial processing workloads. Technical teams overseeing banking reliability implement sophisticated multi-tiered observation frameworks surpassing conventional performance tracking to incorporate specialized fiscal operation verification routines continuously confirming computational accuracy. These validation protocols function as proactive detection mechanisms identifying subtle consistency anomalies that might remain concealed until emerging during reconciliation procedures at operational day conclusion, potentially affecting vast customer populations [3].
Regulatory frameworks establish distinctive operational boundaries surrounding banking reliability practices, imposing structural governance mandates directly affecting technological automation possibilities. Financial organizations function under comprehensive technology risk management directives requiring formal modification control systems, operational separation between development and production responsibilities, and documented authorization sequences for infrastructure alterations. These compliance stipulations directly limit automation implementation options within banking environments, necessitating carefully structured governance architectures balancing operational enhancement against compliance responsibilities. Technology reliability specialists must incorporate regulatory considerations throughout automation planning, establishing verification checkpoints within deployment sequences while maintaining detailed activity documentation for all automated processes. Published guidelines from financial oversight authorities specifically address operational continuity expectations, mandating that banking institutions establish defined recovery timeframes for essential services alongside appropriate technical and procedural safeguards ensuring these targets remain achievable. These regulatory structures profoundly influence banking reliability methodologies, requiring development of specialized operational patterns incorporating compliance verification within automation sequences while preserving appropriate human supervision throughout regulated procedures [3].
Financial technology platforms demonstrate characteristic failure typologies emerging from intersections between technical sophistication, regulatory mandates, and transaction processing requirements. Predominant system degradation patterns include processing capacity limitations during volume peaks, balance discrepancies between customer-facing interfaces and accounting systems, authentication mechanism failures affecting multiple service channels simultaneously, and integration disconnections between contemporary digital frameworks and established transaction processing infrastructure. The interconnected architecture of banking platforms creates intricate failure propagation pathways where performance degradation affecting individual components rapidly extends to dependent services, potentially triggering extensive service interruptions across digital interaction channels. Banking reliability practices have developed specialized resilience techniques addressing these failure patterns, incorporating transaction management mechanisms prioritizing processing according to financial significance, protective circuit limitation patterns engineered specifically for financial workloads, and graceful capability reduction approaches maintaining essential transaction functions while temporarily disabling supplementary features. These specialized methodologies reflect the banking industry's fundamental prioritization of transaction accuracy and data consistency above alternative considerations, demanding reliability approaches emphasizing correctness assurances despite temporary reductions in functional capabilities or performance characteristics [4].
Table 1: Automation and Human Expertise Distribution in Banking SRE. [3, 4]
<table><tr><td>SRE Component</td><td>Automation Role</td><td>Human Expertise Role</td><td>Primary Consideration</td></tr><tr><td>Monitoring & Alerting</td><td>Continuous data collection, anomaly detection, alert correlation</td><td>Alert triage, context interpretation, impact assessment</td><td>Signal-to-noise ratio optimization</td></tr><tr><td>Transaction Processing</td><td>Integrity verification, reconciliation, throughput management</td><td>Novel failure analysis, financial impact evaluation, compliance oversight</td><td>Transaction integrity preservation</td></tr><tr><td>Incident Response</td><td>Initial detection, data gathering, known pattern remediation</td><td>Strategic decision-making, stakeholder communication, regulatory notification</td><td>Appropriate handoff mechanisms</td></tr><tr><td>Self-Healing Systems</td><td>Non-destructive actions, circuit breakers, graceful degradation</td><td>Boundary enforcement, risk assessment, novel scenario management</td><td>Clearly defined automation boundaries</td></tr><tr><td>Knowledge Management</td><td>Documentation systems, change tracking, alert history</td><td>Tacit knowledge sharing, mentorship, contextual understanding</td><td>Capturing both explicit and implicit knowledge</td></tr></table>
## III. EFFECTIVE AUTOMATION STRATEGIES
Banking SRE teams must establish clear automation priorities that balance operational efficiency with the unique constraints of financial environments. The most effective approach begins with nondestructive automation focused on observability and data collection before progressing to more complex remediation capabilities. Initial automation efforts typically target configuration validation, environment consistency checking, and deployment pipeline orchestration-areas where automation provides immediate value with minimal risk. As these foundational capabilities mature, focus shifts toward implementing circuit breaker patterns that prevent cascading failures across interconnected banking systems. These stability patterns automatically detect degraded conditions and implement protective measures such as connection throttling, request queuing, or graceful service degradation to maintain core transaction processing capabilities during stress conditions. The implementation of bulkhead patterns proves particularly valuable in banking environments, automatically isolating system components to contain failure impacts within non-critical boundaries while preserving essential financial functions. Transaction integrity verification represents another high-priority automation target, with continuous reconciliation processes that automatically validate consistency between distributed ledgers and flagging discrepancies for immediate investigation. This strategic prioritization allows banking institutions to realize automation benefits incrementally while
maintaining appropriate governance over critical financial processing systems [5].
Monitoring and alerting strategies for banking applications demand specialized approaches that accommodate both technical performance metrics and business-oriented transaction processing indicators. Effective monitoring implementations establish clear signal-to-noise ratios by differentiating between actionable alerts requiring immediate response and informational notifications that provide context without demanding intervention. This differentiation becomes particularly critical in banking environments where alert fatigue can lead to overlooked signals with potentially significant financial consequences. Multi-level alerting frameworks organize notifications based on potential business impact, with distinct thresholds for performance degradation, transaction anomalies, and complete service disruption. The most sophisticated monitoring systems implement correlation engines that automatically group related alerts across distributed systems, providing operators with contextual understanding of incident scope and potential financial implications. Synthetic transaction monitoring serves as a cornerstone capability, with automated processes continuously executing simulated customer journeys to validate end-to-end functionality across digital banking channels. Effective monitoring includes specialized verification of non-functional requirements particularly relevant to banking such as response time consistency, transaction throughput sustainability, and processing latency during peak volumes. These comprehensive observability practices create the foundation for successful automation by providing accurate, timely visibility into system behavior across heterogeneous banking technology environments [5].
Self-healing capabilities in banking environments operate within carefully defined boundaries that reflect both technical feasibility and risk management considerations. Successful implementation begins with clearly documented failure modes and their corresponding remediation procedures, focusing initial automation efforts on scenarios with deterministic resolution paths and limited potential for adverse side effects. Automated recovery mechanisms typically start with non-destructive actions such as connection reestablishment, cache invalidation, or traffic rerouting before progressing to more invasive interventions like service restarts or database failovers. Banking SRE teams establish explicit control boundaries for self-healing systems, implementing governance gates that prevent automated modification of core transaction processing components without appropriate verification. These boundaries often manifest as tiered automation frameworks where remediation actions with higher potential impact require corresponding levels of confidence before automatic execution. The implementation of graceful degradation patterns represents a particularly valuable self-healing approach, where systems automatically detect performance issues and selectively disable non-essential features while maintaining critical financial functions. For instance, during periods of elevated load, systems might automatically disable complex search functionality or analytical reporting while preserving payment processing capabilities based on predefined business priorities [6].
Risk assessment frameworks provide essential governance for automation implementation in banking environments, requiring formal evaluation processes that consider technical, operational, and regulatory dimensions. Comprehensive assessment methodologies evaluate automation initiatives across multiple factors including potential impact radius, reversibility of automated actions, confidence levels in detection mechanisms, and regulatory compliance implications. Implementation approaches incorporate progressive validation through limited deployment models, where automation initially operates in advisory mode-suggesting actions without executing them—allowing teams to validate accuracy before enabling automated execution. Formal testing regimes verify automation behavior across diverse scenarios, including simulated failure conditions and edge cases specifically relevant to financial processing. Banking SRE teams develop specialized verification approaches for automated remediation capabilities, implementing safeguards such as automatic rollback triggers, execution time limits, and impact scope restrictions. The most mature organizations implement "oversight" mechanisms that automatically notify human operators when automation encounters unexpected conditions, creating a collaborative model where automation handles routine scenarios while escalating novel situations for human judgment. These structured risk assessment processes enable banking institutions to capture efficiency benefits while maintaining appropriate controls over critical financial systems [6].
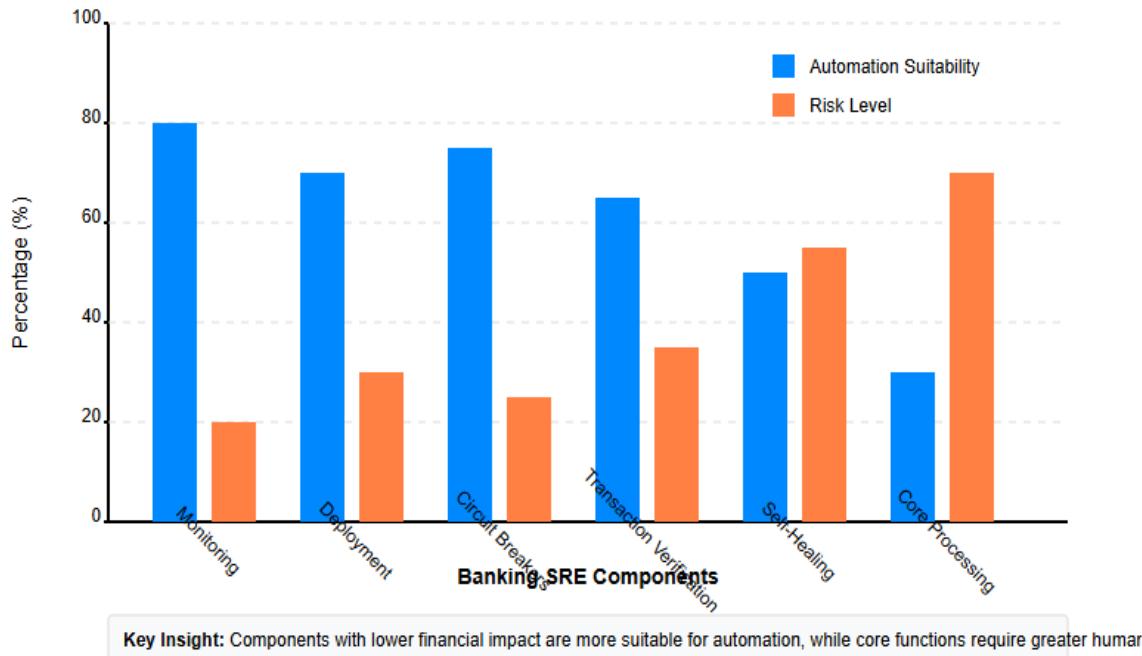 Fig. 2: Banking SRE: Automation Suitability vs. Risk Level. [5, 6]
## IV. HUMAN EXPERTISE COMPONENTS
Technological advancement within financial reliability engineering reveals certain operational domains where human cognitive capabilities remain indispensable despite expanding automation sophistication. Investigations regarding automation paradoxes within mission-critical domains reveal counterintuitive relationships wherein greater system sophistication actually amplifies rather than diminishes human involvement significance during exceptional circumstances. Banking operational environments routinely demonstrate this principle, where programmed systems proficiently manage documented failure situations yet encounter substantial limitations addressing unprecedented disruptions lacking historical context. Human specialists exhibit exceptional proficiency regarding contextual interpretation, identifying subtle relationship patterns between seemingly disconnected system behaviors, and constructing adaptive response strategies using incomplete diagnostic information. These intellectual advantages become particularly consequential during multifaceted incidents where manifestations appear inconsistently throughout distributed financial infrastructure or when disruptions materialize at boundary intersections connecting technical platforms with business operations. Human supervisory functions acquire heightened significance within banking contexts where regulatory adherence must integrate seamlessly with technical recovery strategies. During transaction anomalies occurring amidst peak processing periods, experienced practitioners simultaneously evaluate performance metrics, operational patterns, compliance obligations, and financial exposure implications—creating multidimensional analysis frameworks exceeding present automation interpretation capabilities. Such scenarios underscore fundamental constraints within programmed response systems, which execute predetermined intervention sequences effectively yet lack interpretive awareness, adaptive reasoning capabilities, and nuanced judgment characteristics that human specialists contribute during sophisticated incident resolution within financial technology environments [7].
Banking reliability engineering necessitates distinctive human capability profiles extending substantially beyond conventional technology expertise to encompass specialized financial knowledge, regulatory comprehension, and advanced interpersonal communication skills spanning organizational divisions. Research examining complex operational environments demonstrates that effective management requires practitioners possessing dual proficiency regarding both technological architectures and domain-specific functional contexts. Within banking operations, this translates into reliability specialists comprehending payment processing workflows, settlement system designs, and intricate dependencies connecting customer interfaces with core financial platforms. This specialized knowledge facilitates rapid translation between technical disruption indicators and corresponding business impact evaluations alongside customer experience implications. Professional qualification profiles necessarily incorporate regulatory proficiency, wherein practitioners understand compliance frameworks influencing availability intervention options during service disruptions. Communication proficiency assumes particular importance within financial organizations where incident management frequently requires coordinated responses across technology departments, business divisions, and compliance functions. Skilled practitioners develop specialized communication techniques translating technical concepts into business impact frameworks, enabling appropriate decision-making regarding response priorities and external communications. Problem-solving methodologies within banking reliability contexts require specialized conceptual frameworks accommodating both technical intricacy and stringent compliance limitations, with practitioners developing intellectual flexibility formulating innovative solutions maintaining regulatory adherence even during critical service disruptions. These multifaceted capability requirements underscore organizational imperatives developing comprehensive professional advancement pathways cultivating both technical proficiency and domain-specific expertise within banking reliability engineering teams [7].
Structured intervention frameworks provide essential organizational mechanisms determining appropriate boundaries between automated systems and human specialists within banking operational environments. Investigations examining collaborative human-machine systems demonstrate optimal performance emerges through structured integration rather than isolated component operation. Effective frameworks establish specific intervention criteria defining precise conditions activating human involvement despite existing automation capabilities. These determinations typically incorporate novelty evaluation thresholds escalating unprecedented situations for human assessment, complexity indicators initiating specialist review when multiple interactive factors exceed algorithmic interpretation capacities, and confidence measurements triggering intervention when automated diagnosis produces ambiguous conclusions. Banking reliability teams implement structured decision pathways guiding escalation procedures, ensuring uniform application of intervention principles across geographically distributed operational groups addressing diverse incident categories. These frameworks incorporate temporal triggers initiating human evaluation when automated resolution attempts fail within established timeframes, preventing extended degradation affecting critical banking capabilities. Advanced implementation approaches establish collaborative operational models where automated systems manage routine incident aspects while human specialists concentrate on strategic determinations requiring contextual understanding and stakeholder coordination. During significant disruptions affecting payment processing systems, this manifests through parallel workflows where automation implements predetermined technical mitigations while human specialists determine customer notification strategies and regulatory reporting requirements. These structured frameworks enable financial organizations to maximize automation benefits while ensuring specialized human expertise remains available when genuinely required [8].
Institutional knowledge preservation represents a fundamental dimension supporting human expertise within banking reliability operations, requiring methodical approaches capturing, organizing, and distributing collective operational wisdom throughout technical organizations. Research examining resilient operational systems emphasizes dependence upon distributed knowledge frameworks rather than exclusively technical infrastructure. Banking environments create distinctive knowledge management challenges arising from financial system complexity, specialized domain terminology, and critical historical incident context preservation requirements. Effective knowledge systems implement diverse preservation strategies maintaining both structured technical documentation and experiential wisdom accumulated through incident resolution activities. Post-incident analysis sessions function as primary knowledge acquisition mechanisms, documenting beyond technical failure particulars to capture decision rationales, hypothesis evaluation approaches, and contextual elements influencing response strategies. Banking reliability teams develop specialized documentation methodologies incorporating financial terminology alongside technical descriptions, ensuring knowledge repositories capture comprehensive operational context necessary for future reference. Professional communities establish essential knowledge distribution networks, connecting specialists across different banking functions exchanging insights regarding common challenges and effective resolution techniques. Mentoring relationships assume particular significance within banking environments, establishing structured knowledge transfer pathways enabling experienced practitioners to convey specialized insights potentially missed within formal documentation systems. Organizations implement systematic knowledge validation procedures reviewing existing documentation against current architectural configurations and regulatory requirements, maintaining institutional knowledge accuracy despite continuously evolving banking technology platforms [8].
Table 2: Critical Human Capabilities in Banking Reliability Engineering: Automation Gap Analysis. [7, 8]
<table><tr><td>Human Expertise Component</td><td>Criticality Level</td><td>Automation Gap</td></tr><tr><td>Contextual Reasoning</td><td>High</td><td>Substantial</td></tr><tr><td>Domain-Specific Knowledge</td><td>Very High</td><td>Significant</td></tr><tr><td>Regulatory Compliance Understanding</td><td>Critical</td><td>Extensive</td></tr><tr><td>Novel Situation Response</td><td>Very High</td><td>Considerable</td></tr><tr><td>Cross-Functional Communication</td><td>High</td><td>Moderate</td></tr></table>
### Data Interpretation:
This table quantifies the relative importance of various human expertise components in banking SRE and the corresponding gaps in current automation capabilities. The data shows that regulatory compliance understanding represents the area with both the highest criticality and the most extensive automation gap, while communication functions show a somewhat smaller (though still significant) automation gap. This data could be effectively visualized as a radar chart, clustered column chart, or bubble chart in Excel.
## V. IMPLEMENTATION FRAMEWORK
### a) Decision Matrix for Automation vs. Human Control
Establishing productive reliability engineering methodologies within financial technology environments demands structured allocation frameworks distinguishing machine-driven versus specialist-controlled operational domains. Technical architecture investigations concerning enterprise deployments indicate boundary delineation should proceed through comprehensive assessment spanning diverse considerations including-
- Operational viability
- Exposure profiles
- Compliance implications
- Institutional preparedness factors
Practical implementation commences through categorical separation regarding operational functions across multiple classification tiers reflecting:
- Criticality measurements
- Financial consequence parameters
- Restoration complexity characteristics
#### Key Implementation Considerations:
- For foremost-tier operations directly manipulating monetary transfers or account valuation adjustments, decision structures typically advocate specialist-verification methodologies wherein technological assistance occurs throughout processes while execution completion requires explicit authorization protocols.
- Supporting functions facilitating transaction procedures without direct financial record modification might employ technological automation
alongside mandatory specialist supervision during predefined exposure circumstances.
- Subordinate-tier operations demonstrating minimal direct financial consequences may utilize extensive technological oversight with infrequent specialist engagement through exception-handling mechanisms.
- Assessment structures must additionally incorporate incident attributes including-
- Service deterioration progression rates
- Affected clientele distribution patterns
- Confidence assessments regarding automated diagnostic conclusions.
When confronted with unprecedented failure manifestations lacking historical context, determination protocols should default toward specialist-directed response patterns with technological mechanisms providing supplementary assistance regardless of operational classification levels.
Allocation frameworks necessarily evolve through structured governance mechanisms periodically reassessing technological boundaries parallel with capability advancements and emerging regulatory obligations, thereby maintaining proper alignment between progressive technological capacities and compliance parameters. Comprehensive implementation necessarily includes thorough documentation recording rationale supporting individual allocation decisions, thereby constructing institutional knowledge repositories informing subsequent refinement phases throughout financial technology infrastructures [9].
### b) Incident Response Workflow Design
Disruption management workflow architectures constitute foundational components within balanced reliability implementations throughout banking environments, necessitating deliberate orchestration regarding collaboration methodologies between automated mechanisms and specialist personnel during service abnormalities. Technical architectural research emphasizes effective disturbance management requires precisely defined interaction boundaries between mechanical components and specialist decision junctures.
Within financial environments, workflow structures should implement sequential methodologies:
- $\succ$ Initial Phase: Automated identification and preliminary classification procedures.
- $\succ$ Secondary Phase: Introduction of specialist judgment at appropriate determination points.
Key Workflow Components:
> Detection mechanisms utilize observation systems identifying potential disruptions through-
- Threshold violation notifications.
- Pattern deviation identification techniques.
- Transaction processing irregularities potentially indicating financial information corruption.
> Impact assessment conducted by automated components-
- Gathering diagnostic information across affected subsystems.
- Enriching notifications with contextual elements regarding transaction characteristics.
- Identifying potential compliance implications.
$\succ$ Classification Systems categorizing disruptions according to:
- Severity measurements
- Affected component inventories
- Similarity comparisons against documented precedents.
For recognized disruption patterns with established resolution pathways:
- Automation initiates predetermined correction sequences.
- Simultaneously alerts appropriate specialist personnel for situational awareness.
$\succ$ Transition Junctures where disruptions exhibiting specific characteristics transfer toward specialist-directed responses.
- Formalized handover protocols.
- Comprehensive situational awareness.
- Previously attempted correction actions.
- Pertinent historical references.
Architectural implementations should incorporate dedicated communication infrastructures maintaining coordination between technical departments, business stakeholders, and compliance functions throughout disruption resolution lifecycles [9].
### c) Team Structure Recommendations
Organizational structure recommendations regarding banking reliability engineering must accommodate specialized proficiency requirements alongside regulatory considerations characteristic within financial environments while cultivating shared accountability principles regarding service dependability.
Effective Structural Implementations Balance:
- Centralized specialization
- Distributed responsibility allocation
Key Organizational Elements:
$\succ$ Primary reliability teams should incorporate practitioners demonstrating complementary proficiency distributions:
- Infrastructure specialization
- Application performance expertise
- Observation system proficiency
- Automation development capabilities
- Combined technical competence alongside financial domain comprehension
These Centralized Specialist Groups Establish:
- Dependability standards
- Automation frameworks
- Observation platforms specifically addressing banking requirements
$\succ$ Embedded Reliability Specialists within application development groups ensure:
- Dependability practices integrate effectively alongside domain-specific implementation
- Alignment with business requirements
Dedicated Compliance Functions focusing specifically on regulatory aspects:
- Ensuring continuous alignment between technological practices and financial industry regulations.
- Maintaining compliance throughout implementation phases.
$\succ$ Multi-Disciplinary Disruption Management Teams consolidate:
- Technical specialists
- Business representatives
- Compliance authorities
- Comprehensive resolution capabilities addressing both technological and regulatory dimensions.
Professional Development Pathways should incorporate:
- Rotational assignments.
- Combined technical proficiency development.
- Broad financial knowledge domains.
- Multidisciplinary expertise essential for effective reliability engineering within financial environments [10].
### d) Performance Metrics for Balanced SRE Practices
Performance evaluation frameworks regarding balanced reliability implementations within banking environments must assess both technological outcomes alongside human-automation collaboration effectiveness through comprehensive measurement structures.
#### Limitations of Traditional Metrics:
- Traditional evaluation approaches concentrating primarily on availability percentages provide inadequate insights within financial contexts.
- Transaction accuracy, processing correctness, and compliance adherence demonstrate equivalent importance compared against system accessibility measurements.
#### Effective Evaluation Methodologies Include:
#### $\succ$ Multiple Reliability Dimensions:
- Consistency regarding customer experiences across interaction channels.
- Transaction fulfillment ratios.
- Alignment against regulatory requirements.
#### Technical Measurements:
- Acceptable disruption thresholds
- Failure frequencies across critical transaction pathways.
- Response timing characteristics.
- Banking-specific measurements including reconciliation precision.
#### > Automation Effectiveness Assessment:
- Implementation coverage across operational functions.
- Successful versus unsuccessful automated remediation attempts.
Comparative resolution duration
### Human Performance Indicators:
- Collaboration effectiveness
- Transition efficiency between systems and specialists
- Decision accuracy during disruption scenarios
- Knowledge preservation across organizational boundaries
#### > Compliance Aspects:
- Punctual notification procedures toward regulatory authorities.
- Comprehensive disruption documentation practices.
- Adherence toward mandated recovery timeframes.
Sophisticated approaches implement balanced evaluation frameworks assessing both technological outcomes alongside process effectiveness metrics, thereby avoiding disproportionate emphasis regarding individual measurements potentially establishing counterproductive organizational incentives. Effective measurement regimes incorporate operational burden tracking mechanisms identifying opportunities regarding beneficial automation while preserving human engagement within domains where judgment and contextual comprehension remain indispensable [10].
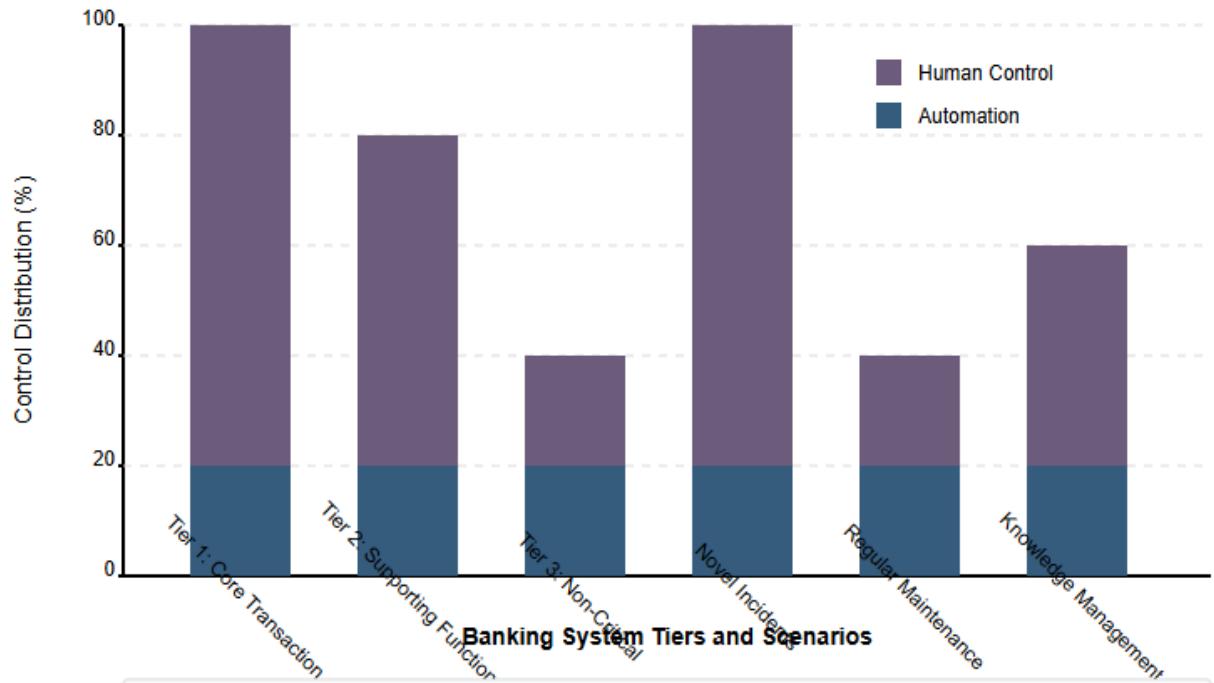 Fig. 3: Automation vs. Human Control in Banking SRE Tiers. [9, 10]
## VI. CONCLUSION
The effective implementation of SRE in banking applications fundamentally depends on establishing appropriate boundaries between automation and human expertise. The article demonstrates that successful banking SRE requires specialized approaches that extend beyond traditional reliability practices to accommodate financial domain requirements, regulatory constraints, and transaction processing integrity. Through carefully designed decision matrices, incident workflows, team structures, and performance metrics, banking organizations can create reliability frameworks that leverage automation for consistency and efficiency while preserving human judgment for complex decision-making and regulatory compliance. The complementary strengths of automated systems and skilled practitioners create resilient banking platforms capable of maintaining reliable service delivery despite the inherent complexity of financial environments. As banking technology continues to evolve with increasing automation capabilities, maintaining this balanced approach will remain essential-neither complete automation nor predominantly manual operations can address the multifaceted reliability requirements of modern banking systems. The structured implementation framework presented offers banking institutions a practical path toward reliability practices that simultaneously satisfy technical, business, and regulatory imperatives through thoughtful integration of automation capabilities and human expertise.
Generating HTML Viewer...
References
12 Cites in Article
(2019). Operational resilience in financial services.
Jamil Mina (2021). Bringing reliability to banking services: a new twist on Site Reliability Engineering.
Emad Al Khoufi (2019). Adu, K.K. and Adjei, E. (2018). The phenomenon of data loss and cyber security issues in Ghana. Foresight, 20(2), 150–61. Ahmed, M.T.U., Bhuiya, N.I. and Rahman, M.M. (2017). A secure enterprise architecture focused on security and technology-transformation (SEAST), The 12th International Conference for Internet Technology and Secured Transactions, (ICITST-2017), Cambridge, UK, 11–4/12/2017. Alanazi, S.T., Anbar, M., Ebad, S.A., Karuppayah, S. and Al-Ani, H.A. (2020). Theory-based model and prediction analysis of information security compliance behavior in the Saudi healthcare sector. Symmetry, 12(9), 1544. DOI: 10.3390/sym12091544 Alateyah, S.A., Crowder, R.M. and Wills, G.B. (2013). Identified factors affecting the citizen’s intention to adopt e-government in Saudi Arabia. World Academy of Science, Engineering and Technology, 7(8), 904–12. Antonino, P., Duszynski, S., Jung, C. and Rudolph, M. (2010). Indicator-based architecture-level security evaluation in a service-oriented environment. In: The Fourth European Conference on Software Architecture: Copenhagen, Denmark, 23–26/08/2010. DOI: 10.1145/1842752.1842795. Chaturvedi, M., Gupta, M. and Bhattacharya, J. (2008). Cyber Security Infrastructure in India: A Study, Emerging Technologies in E-Government. Available at: http://www.csi-sigegov.org/emerging_pdf/9_70-84.pdf (Accessed on 15/11/2020). Dalol, M.H. (2018). Effectiveness of Accounting Information Systems in Light of Development of IT Infrastructure and Information Security. Master’s Dissertation, The Islamic University of Gaza, Gaza, Palestine. Dooley, K. (2001). Designing Large Scale LANs: Help for Network Designers. USA: O'Reilly Media. Ebad, S. (2018a) An exploratory study of ICT projects failure in emerging markets. Journal of Global Information Technology Management, 21(2), 139–60. DOI: 10.1080/1097198X.2018.1462071. Ebad, S. (2018b). The influencing causes of software unavailability: A case study from industry. Software Practice and Experience, 48(5), 1056–76. DOI: 10.1002/spe.2569. Hashizume, K., Rosado, D.G., Fernández-Medina, E. and Fernandez, E.B. (2013). An analysis of security issues for cloud computing. Journal of Internet Services and Applications, 4(5), n/a. DOI: 10.1186/1869-0238-4-5. Kirby, L. (2015). Beyond Cyber Security: Protecting Your IT Infrastructure. Available at https://uptimeinstitute.com/images/Documents/ProtectingYourITInfrastructure.pdf (accessed on 15/11/2020). Lethbridge, T.C., Sim, S.E. and Singer, J. (2005). Studying software engineers: Data collection techniques for software field studies. Empirical Software Engineering, 10(3), 311–41. Marrone, M. and Kolbe, L.M. (2011). Impact of IT service management frameworks on the IT organization. Business and Information Systems Engineering, 3(1), 5–18. Mastelic, T. and Brandic, I. (2013). TimeCap: Methodology for comparing IT infrastructures based on time and capacity metrics. In: The IEEE 6th International Conference on Cloud Computing, 131–8, Santa Clara, CA, USA, 28/06–03/07/2013. Mimura, M. and Suga, Y. (2019). Filtering malicious JavaScript code with Doc2Vec on an imbalanced dataset. In: The 14th Asia Joint Conference on Information Security (AsiaJCIS), Kobe, Japan, 24–31/08/2019. Pearlson, K.E., Saunders, C.S. and Galletta, D.F. (2019). Managing and Using Information Systems. 5th edition, USA: Wiley. Popp, K. and Meyer, R. (2011). Profit from Software Ecosystems Models, Ecosystems and Partnerships in the Software Industry. Norderstedt, Germany: Books on Demand. Priem, R. (2020). Distributed ledger technology for securities clearing and settlement: Benefits, risks, and regulatory implications. Financial Innovation, 6(11), n/a. DOI: 10.1186/s40854-019-0169-6. Rabii, L. and Abdelaziz, D. (2015). Comparison of e-readiness composite indicators, The 15th International Conference on Intelligent Systems Design and Applications (ISDA), Marrakech, Morocco, 14–16/12/2015. Sanchez-Nielsen, E., Padron-Ferrer, A. and Marreo-Estevez, F. (2011). A multi-agent system for incident management solutions on IT infrastructures. In: The 14th Conference of the Spanish Association for Artificial Intelligence (CAEPIA 2011), La Laguna, Spain, 07–11/11/2011. Schoenfisch, J, Meilicke, C., Stülpnagel, J.V. and Ortmann, J (2018). Root cause analysis in IT infrastructures using ontologies and abduction in Markov logic networks. Information Systems, 74(2), 103–16. Shang, S. and Seddon, P.B. (2000). A comprehensive framework for classifying the benefits of ERP systems. In: The 2000 American Conference of Information Systems, Long Beach, California, 10–13/08/2000. Shoffner, M., Owen, P., Mostafa, J., Lamm, B., Wang, X., Schmitt, C.P. and Ahalt S.C. (2013). The secure medical research workspace: An IT infrastructure to enable secure research on clinical data. Clinical and Translational Science, 6 (3), 222–5. Shrivastava, A.K. (2015). The impact assessment of IT Infrastructure on information security: a survey report. In: International Conference on Information Security and Privacy (ICISP2015), Nagpur, India, 11–12/12/2015. Sommerville, I. (2015). Software Engineering. 10th edition, UK: Pearson. Sousa, K.J. and Oz, E. (2015). Management Information Systems. 7th edition, USA: Cengage Learning. Teymourlouei, H., and Harris, V. (2019). Effective methods to monitor IT infrastructure security for small business. In: The 2019 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 5–7/12/2019. Topper, J. (2018). Compliance is not security. Computer Fraud and Security, 2018(3), 5–8. DOI: 10.1016/S1361-3723(18)30022-8. Wohlin, C., Runeson, P., Host, M., Ohlsson, M.C., Regnell, B. and Wesslen, A. (2012). Experimentation in Software Engineering. Germany: Springer. Yasasin, E., Prester, J., Wagner, G. and Schryen, G. (2020). Forecasting IT security vulnerabilities –an empirical analysis. Computers and Security, 88(n/a), n/a. DOI: 10.1016/j.cose.2019.101610. Zambon, E., Etalle, S., Wieringa, R.J. and Hartel, P. (2010). Model-based qualitative risk assessment for availability of IT infrastructures. Software and Systems Modeling, 10(4), 553–80..
Alexandr Hacicheant (2014). Ensuring the Availability of Critical Cloud Services Through SRE Practices.
Michael Nygard (2018). Release It! Second Edition Design and Deploy Production-Ready Software.
Slawek Ligus (2012). Effective Monitoring and Alerting.
Lisanne Bainbridge (1983). Ironies of automation.
Erik David D Woods,Hollnagel (2006). Joint Cognitive Systems: Patterns in Cognitive Systems Engineering.
Len Bass (2015). The Software Architect and DevOps.
Niall Richard,Murphy Site Reliability Engineering.
Len Bass (2015). DevOps: A Software Architect's Perspective.
Betsy Beyer (2016). Site Reliability Engineering: How Google Runs Production Systems.
No ethics committee approval was required for this article type.
Data Availability
Not applicable for this article.
How to Cite This Article
Anjana Shree Sundar. 2026. \u201cBlending Automation and Human Expertise in SRE for Banking Applications\u201d. Global Journal of Computer Science and Technology - G: Interdisciplinary GJCST-G Volume 25 (GJCST Volume 25 Issue G1): .
Explore published articles in an immersive Augmented Reality environment. Our platform converts research papers into interactive 3D books, allowing readers to view and interact with content using AR and VR compatible devices.
Your published article is automatically converted into a realistic 3D book. Flip through pages and read research papers in a more engaging and interactive format.
The banking sector presents unique challenges for Site Reliability Engineering practices due to stringent regulatory requirements, complex technical environments, and zero-tolerance for financial data errors. This article explores the critical balance between automation capabilities and human expertise in maintaining reliable banking applications. It examines the distinctive reliability requirements of financial systems, identifies effective automation strategies within regulatory constraints, articulates the irreplaceable components of human judgment, and proposes an implementation framework for optimal collaboration between automated systems and human operators. Through detailed analysis of bankingspecific failure modes, monitoring approaches, and incident response workflows, the article provides a structured approach to developing SRE practices that leverage both technological capabilities and human cognitive strengths while respecting the unique constraints of financial environments. The framework presented enables banking institutions to implement reliability practices that maintain transaction integrity, meet regulatory obligations, and support business objectives through carefully designed human-automation systems.
Our website is actively being updated, and changes may occur frequently. Please clear your browser cache if needed. For feedback or error reporting, please email [email protected]
Thank you for connecting with us. We will respond to you shortly.