The objective of this work was to elucidate paths for expediting and enhancing scientific research productivity from the emerging AI paradigm of foundation models (e.g., ChatGPT). Faster scientific progress can benefit mankind by speeding up progress toward solutions to shared human problems like cancer, aging, climate change, or water scarcity. Challenges to foundation model adoption in science threaten to slow progress in such research areas. This study attempted to survey decision support systems and expert system literature to provide insights regarding these challenges. We first reviewed extant literature on these topics to try to identify adoption patterns that would be useful for this purpose. However, this attempt, using a bibliometric approach and a very high level traditional literature review, was unsuccessful due to the overly broad scope of the study. We then surveyed the existing scientific software domain, finding there to be a huge breadth in what constitutes scientific software. However, we do glean some lessons from previous patterns of adoption of scientific software by simply looking at historical examples (e.g., the electronic spreadsheet)
## I. INTRODUCTION
et al. 2012, Mnih et al. 2015, Silver et al. 2016, Brown et al. 2020, Reed et al. 2022). While this progress hasn't translated to practice as dramatically as some have anticipated (Brynolfsson et al. 2018), it is unlikely that we are at the onset of a third Al winter[^2]2. In fact, the latest family of Al models appears to be ready to live up to the growing Al hype of the past decade, with many describing these models as a general purpose technology (Bommasani et al. 2021; Eloundou et al. 2023).
This recent progress has been driven by advances initially in the AI subdomain of natural language processing (NLP). These advances have most commonly been associated with language models, which are statistical models of human language that are essentially trained to be able to predict the next word in a sentence. To be certain, this is an oversimplification, but more detail is beyond the scope of this study[^3]. However, the progress in NLP is now bleeding over to other subdomains of AI such as computer vision and robotics (Reed et al. 2022). This progress is in an emerging research area that is known as foundation models (Bommasani et al. 2021).
Language models are one type of foundation model, but they are only trained on language data. However, foundation models can be trained on different types of data, for example on image data or video data, in a semi-supervised fashion like language models (Bommasani et al 2021); they can even be trained on multiple data types in what can be described as multimodal models. An example of this is DALL-E 2 (Ramesh et al. 2022), a multimodal model that can take text as input and generate images as output. A version of GPT-4 (OpenAI 2023) integrated into ChatGPT (OpenAI 2022) was used to generate Figure 1 (see Figure caption for more detail), and is now being marketed by OpenAI for creative design tasks. An even more powerful multimodal model was used to create a generalist agent capable of interacting with the real world through robotics and natural language, and capable of outperforming humans at video games[^5][^4](Reed et al. 2022).

Figure 1: An Image Generated from a Text Prompt: "Create a Photorealistic Image of a Scientist Putting herself out of work by using an AI System to Generate Hypotheses and to Propose Experiments that her Research Assistants can conduct in her Laboratory." This Image was Created Using GPT-4 (Openai 2023) Via Chatgpt Plus particularly interested in how foundation models, or other powerful AI tools of the future, might enhance creativity and productivity for research and experimental design, particularly as it relates to advancing science, as this appears to have the greatest potential for positive- and negative-impact to humanity.
There has been a significant amount of discussion regarding the use of AI for scientific discovery or as a driver of scientific progress. Google DeepMind's mission is to[^1] "solve intelligence to advance science and humanity" (Hassabis 2022), and Lila Ibrahim, their COO, recently explained that for scientific research the "ability to use a more generalized intelligence to augment human knowledge-to have some of these breakthroughs-is really going to be quite spectacular" (Kopytoff et al. 2022). While DeepMind may ultimately seek to automate scientific progress, augmenting human knowledge is the direction that current AI models are moving toward most rapidly. Software that uses AI, like foundation models, to augment human knowledge and enhance scientific research productivity and creativity is the focus of this study.
While we are more interested in AI technologies that can augment human intelligence to enhance scientific research productivity and creativity, it is important to point out other ways in which AI is being used to progress science. DeepMind's use of AI in science is already a game changer (Service 2020) because they have effectively solved the problem of protein folding with AlphaFold (Jumper et al. 2021) and created a comprehensive open source database of over two hundred million protein structure predictions $^{5}$. Previously, AI software took the form of expert systems, which contained encoded expert knowledge but were limited to preprogrammed solutions. However, DeepMind is applying machine learning which enables learning generalizable solutions from first principles. DeepMind has also made progress in other scientific areas, such as nuclear fusion (Degrave 2022).
What is common about DeepMind's AI systems for the protein folding problem and for nuclear fusion is that they are systems developed to excel at a single well-defined task (i.e., predicting protein structures or maintaining stability in a high-energy plasma). The promise of foundation models, and tools that can be used to augment human intelligence, lies not in their ability to do one task well, but in the ability of these tools to adapt to whatever task humans require of them. In machine learning, this adaptability is known as the ability of a model to generalize.
While foundation models offer great potential for transforming the scientific landscape, they are also anticipated to create challenges. Applications of language models for science will involve the creation of academic work used for peer review, as well as more general productivity and creativity tools. Because language models are trained on data from the internet, they can come to exhibit biases or flawed data, which could make their use as an aid in peer review more difficult as scientists will not want to trust them (Okerlund et al. 2022). Moreover, because the models require a large amount of data for training, they will likely reinforce Anglo-American dominance in science.
### a) Spreadsheets, The First "Killer Application"
In 1978, Dan Bricklin, a student at Harvard Business School, noticed a pattern in the errors his professor made when completing rows and columns of a table for a business case during a lecture (Castelluccio 2019). Dan noticed that the errors would propagate through the table; one error often required replacing multiple entries in the table to correct for it. Personal computers were emerging at the time, and Dan came up with the idea for a program that could act as a visual calculator for operations organized in tabular form. This idea is what we now think of as a spreadsheet, and while it was not entirely new, Dan's program VisiCalc became the first electronic spreadsheet and the first "killer application" for the personal computer (Zynda 2013).
The power of the electronic spreadsheet lay in its ability to do general computing tasks without requiring users to know how to program (Zynda 2013). Moreover, the application was designed with user experience in mind so as to be straightforward and easy to use for non-programmers. This led to many users purchasing personal computers solely for VisiCalc. Bricklin and his business partner Bob Frankston were urged not to pursue a patent for the software, which would have been difficult to get for software at that time. This left VisiCalc vulnerable to competition, and over the following years Lotus-1-2-3 overtook VisiCalc's market share (Sachs 2007).
In the decades since, electronic spreadsheets have grown to be used nearly ubiquitously for a variety of analytics-related tasks while changing very little from the initial versions. Looking at the history of spreadsheets, we see a pattern of development centered on creating a standardized product, one that looks, functions and feels like all other spreadsheets (Campbell-Kelly 2003). This may be the case because spreadsheets are functional as they are, and adding to it is not necessarily desirable (Sachs 2007). Microsoft Excel is now dominant in the market, but competitors are also widely used, such as Google Sheets, a cloud spreadsheet alternative.
The ability to complete a broad range of computing tasks without the need to know how to program was a game changer in 1979, and it meant that spreadsheets were software that had a great ability to generalize to a wide variety of problems. Due to their ability to generalize to a wide variety of tasks, they are a useful example to study when considering the next generation of software that AI will lead to—the next generation of AI is going to help create tools with this ability to generalize[^6]. Perhaps foundation models are going to lead to a new 'killer app' similar to the spreadsheet, and in this study we will more carefully analyze what it means to be generalizable software. In fact, the generalizability of software is key to what we consider productivity and creativity enhancing software, the focus of this study that we will define in the following subsection.
### b) This Study
Spreadsheets were one of the earliest decision support systems to become widely popular. To understand the significance of spreadsheets and other technologies relevant to this study, we can look at how frequently these technologies have been mentioned over time. In Figure 2 we use this approach to track the significance of six technologies-spreadsheets, expert systems, decision support systems, natural language processing, machine learning, and artificial intelligence over the past 50 years. AI, spreadsheets and expert systems all gained a lot of interest in the 1980s. Interest in expert systems quickly diminished. Interest in AI and spreadsheets diminished also; significantly for AI, although substantial interest continued steadily; interest for spreadsheets diminished slightly, and stayed steady for some time, although it seems to have started to diminish more.
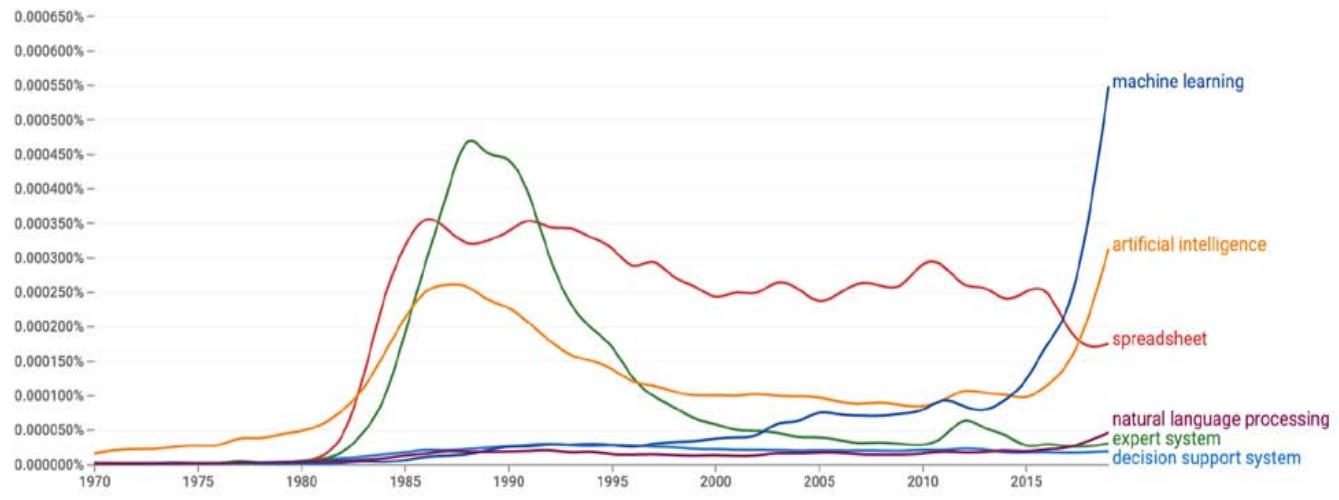 Figure 2: The Frequency of Select Words and Phrases in the Google Books Corpus Since 1970[^7].
Lately, interest in machine learning and AI have begun to explode. Interest in natural language processing is also increasing, but it is unclear how significant this increase will become (i.e., will it increase dramatically like machine learning and AI). Natural language processing aside, it is important to note that AI is used more frequently now than ever, and that machine learning is used twice as often as AI was used during the last AI summer in the 1980s. This time it is unlikely that AI is as overhyped as it was four decades ago, and it is more likely that we will begin to see profound applications of foundation models-the new general purpose technology-across a wide variety of economically valuable applications.
We know that spreadsheets were the first 'killer app' for the personal computer, but it is an open question as to what is going to be the first 'killer app' for foundation models, the latest general purpose technology? Will the characteristics of spreadsheets that made them useful for a broad range of applications—their ability to generalize to a variety of tasks—lead to a new Al-driven app that transforms business? We do not know the answers to these questions, but in this study we attempt reviewing the existing literature to provide a lens through which to view these questions. Specifically, we review literature related to the development of software, scientific software, decision support systems, expert systems, etc. in order to identify insights that can improve the development and adoption of next-generation, Al-driven (i.e., foundation model-driven) software, thereby contributing to the progress of science.
We begin in the next section by identifying definitions of research and experimental development, science, scientific software, etc. We identify criteria for making classifications among different types of scientific software, resulting in a critical distinction between specialized scientific software, like what DeepMind is using for protein folding and nuclear fusion, and more generalizable scientific software, such as tools like spreadsheets which are not always strictly limited to scientific applications. In the following section we review relevant bodies of literature, ranging from software development, to scientific software, to earlier AI-based software like expert systems. We follow this with a discussion and synthesis of the literature, before finally making concluding remarks.
## II. BACKGROUND
Scientific software has been a topic of research since the early 1970s (Hatton 1970; Madison et al. 1970), although it was not heavily studied in academia until over a decade later. While not scientific software per se, electronic spreadsheets were initially developed in the late 1970s and have been widely used in scientific research. In this study, we are interested in both scientific software and more generally useful applications such as electronic spreadsheets. The latter can be used for a wider variety of applications but that also significantly enhance productivity and creativity with respect to scientific research and are our primary concern. However, before diving more deeply into the literature concerning the development of these tools, we first must define what is meant by terms such as scientific software or productivity and creativity enhancement software.
### a) Definitions
We consider scientific research to encapsulate all research driving technological progress, be it in the social sciences, engineering, the hard sciences, etc. Thus, we define science broadly as a communal and systematic enterprise that builds and organizes knowledge through the process of research and experimental development (Wilson 1999; National Academies of Science 2019). The final portion of this definition-research and experimental development-is key to this study because this is the process through which scientific knowledge is created.
The Frascati Manual[^8] is widely thought to be the authoritative source of metrics for evaluating scientific progress, especially for economic purposes (OECD 2015). The Frascati Manual is not directly concerned with scientific research, but focuses entirely on research and experimental development-referred to in the manual simply as R & D-and its components as measurement of such activity is of principal concern to economists. The Frascati Manual defines research and experimental development as creative and systematic work conducted to advance the body of knowledge, including knowledge of humanity, culture and society, and to generate new applications of available knowledge.
The Frascati Manual makes a critical distinction of the three components of R & D: 1) basic research, 2) applied research and 3) experimental development
(OECD 2015). Basic research is experimental or theoretical work undertaken primarily to acquire new knowledge without a specific aim or application. Such research is often undertaken by academics or governments. Applied research refers to investigations that seek to generate new knowledge, but that have a specific, practical aim at the outset. Often applied research attempts to determine uses for theory or knowledge generated in basic research, and it is often conducted by organizations as the results are intended for practical applications to products, operations, methods and systems. Finally, experimental development draws on knowledge from research and practice to produce additional knowledge in the attempt to create novel products or processes, or to improve existing products or processes. Experimental development should not be confused with product development, as it is not concerned with commercialization of a product-it is only a single stage in the product development cycle.
Kanewala and Bieman (2014) define scientific software simply as "software used for scientific purposes". In other prominent literature on scientific software, little effort has been made to define scientific software (Hannay et al. 2009; Joppa et al. 2013). We defer to Kanewala and Bieman's definition for this study, and we point out that this would include software such as electronic spreadsheets if they are used for scientific purposes. This is appropriate for this study, as we are interested in generally capable software that can have a wide range of applications in science and R & D. However, the broad definition is not implicit in much of the prominent literature on the topic. Consequently, we will clarify this distinction between what is traditionally considered scientific software and the more general software that we also consider to be relevant in this study.
The use of the term scientific software in the existing literature is varied. A significant amount of previous work involving scientific software is tied to scientific computing and computational science. In these cases, scientific software refers to software designed to run in a distributed environment such as for high performance computing (i.e., supercomputing; Grannan et al. 2020). Other work refers to a scientific software ecosystem comprised of scientists developing custom software for specific domains, commercial scientific software developers and administrators of platforms for high performance computing (Howison et al. 2015). This broader vision of the scientific software ecosystem better captures the intent of our broad definition of scientific software.
We define specialized scientific software as software that is developed for a specific class of problems in a single domain or closely related domains which doesn't have utility to those working on other problems or outside the domain(s). This could be a commercial program run on individual workstations, such as Pointwise for generating grids for computational engineering; it could be a proprietary program like DeepMind's AlphaFold that is run using distributed computing; or it could be an custom application for controlling physical actuators such as the software DeepMind created for steadying superheated plasma in nuclear fusion or software used in robotics. Specialized systems such as control systems, decision support systems and expert systems, when used for scientific applications, would also be considered specialized scientific software.
We define generalizable scientific software as software that is capable of tasks that are very general and which are useful for a wide variety of applications, with science and R&D being common applications. Generalizable scientific software is often software designed at enhancing creativity and productivity. Excel could be considered as part of this group. Other examples and a more granular discussion of generalizable scientific software are included in the next section.
### b) Categories of Scientific Software
Above we have key terms such as science and research and experimental development (R & D; OECD 2015). We further made a distinction between specialized scientific software and generalizable scientific software. Here, we build on this dichotomy and again draw from the Frascati Manual to develop a set of criteria that we can use for mapping the space of scientific software.
As discussed in the previous subsection, the Frascati Manual proposes distinctions between three different categories of research and experimental development: 1) basic research, 2) applied research and 3) experimental development. The manual further lays out five criteria that are to be used when determining whether an activity constitutes an R&D activity. Specifically, the manual requires that activities be:
- Novel-the activity should be aimed at generating new knowledge.
- Creative-the activity should involve concepts that are original and not obvious.
- Uncertain-there should be substantial uncertainty about the outcome a priori.
- Systematic-the activity should be fastidiously planned and conducted systematically.
- Transferable and/or reproducible-it should lead to results that are reproducible.
Anything assisting in the criteria above can be considered to assist in the development of scientific software. However, we also need to understand the common activities that comprise scientific R & D. Below we propose lists of common activities for both basic and applied research.
There is a large amount of software that could be construed as scientific software, and in order to map the space of scientific software we must identify categories of software based on the activities or tasks that they assist scientists with. We have already described two broad categories—specialized scientific software and generalizable scientific software—and we discuss these further below. However, we also need to categorize further specialized scientific software so that we are able to create the map we desire.
First, we might identify software that can be used for scientific research but that is not relevant to the objective of our study. For one, we feel that project management software and its adoption lies outside the scope of this work[^9].
Another categorization that may be useful is that of 'click-and-run' software and 'syntax-driven platforms'; 'click-and-run' refers to software with polished user interfaces whereas 'syntax-driven' refers to either application programming interfaces (APIs) or software navigated via command line interfaces (CLIs). In a survey conducted by Joppa et. al. (2013) scientific software users were split between those who preferred 'click-and-run' programs and those who preferred 'syntax-driven' programs.
Software that doesn't seem to fit nicely into one of the two categories provided poses challenges to the proposed definitions. An example might be computer-aided design software that enables designers, engineers and researchers to design parts, products and experimental apparatus might be an example of something that doesn't fall clearly into one of the two categories. This would be the case because the task is very specific, to simply create a 3D object digitally. Objects can vary so much that there is often software specific to different domains, but some of the most generic applications can be useful to a wide range of domains. Because it is unclear how to classify such software, we further specify that in such cases of ambiguity, consider the task the software performs or the problem that it solves, and whether or not this is general or specialized.
## III. REVIEW OF LITERATURE
### a) Scientific Software Literature
et al. 2020). While this may not seem relevant, there are some things that might be valuable from this literature. Consider that AI systems like foundation models require large amounts of computation to process language (Sevilla et al. 2022; Kaplan et al. 2020; Amodei and Hernandez 2018). And, another term for NLP is computational linguistics, and it is a subdiscipline of computer science that is effectively a computational science.
Many of the problems described in the HPC scientific software literature involve the portability of this software from one system architecture to another system architecture (Joppa et al. 2013). This can be particularly challenging, and may be relevant to the proliferation of AI scientific software. Particularly, two things may be impacted: large, open source foundation models and regulatory testing and evaluation of large foundation models.
The problems of parallelization of large distributed systems, even for the most simple of tasks, were so tremendous that the first real solution didn't emerge until the demands of the growing search market in the early 2000s led to Google's MepReduce programing paradigm, first reported in 2004 (Dean and Ghemawat 2004). Hadoop was created as an open source version of Google's MapReduce in 2007 (Borthakur 2007; Shvachko et al. 2010). Spark (Zaharia et al. 2012), built on top of the Hadoop distributed file system similarly works well for parallelizing general problems, but both Hadoop and Spark still are insufficient for scientific computing, even if still very useful for analysis of data generated in scientific computing applications. The only similar software enabling large scale distributed computing on compute clusters with various architectures might be Google's Tensorflow (Abadi et al. 2016) and Meta's Pytorch (Paske et al. 2019). These platforms are used specifically for deep learning applications, which would most likely be for scientific computing—specialized scientific software or generalizable scientific software—but would not necessarily be.
We describe the examples of MapReduce (Dean and Ghemawat 2004), Hadoop (Borthakur 2007), Spark (Zaharia et al. 2012), Tensorflow (Abadi et al. 2016), and Pytorch (Paske et al. 2019) to illustrate the limited number of platforms able to support automatic parallelization on large-scale distributed compute clusters. This is important because HPC software is typically written for specific system architectures due to the need for parallelization under specific system constraints. While Tensorflow and Pytorch are written specifically to be able to be applied to a broad range of tasks, parallelization on very large models again encounters the challenges traditionally found in scientific computing (Basili et al. 2008; Joppa et al. 2013; Grannan et al. 2020). Challenges of parallelization on the proliferation and use of foundation models for all applications, including for scientific applications, is something that companies appear to be increasingly cautious of publishing publicly. One recent exception to this would be Google's description of their Pathways program (Barham et al. 2022). This architecture was used to train Google's largest model to date, PALM 2 (Anil et al. 2023), which is referenced in the acronym PALM is derived from Pathways Language Model (Chowdhery et al. 2022). Pathways is able to scale beyond the limitations of the TPU v4's 3d torus network topology (Jouppi et al. 2023), although the scalability is unclear beyond two TPU Pods. In the future, if proprietary systems for distributed inference are required, this could be problematic for sharing of open source systems or testing and evaluation of systems if a single architecture is not adopted. The architecture that is likely to be adopted will be that dictated by the market leader, Nvidia, with their Superpod architecture used in HPC systems like Nvidia's Selene compute cluster, number 13 on the Top 500[^10] as of November 2023. It is likely that cloud providers will continue to use this architecture, and even possible that Nvidia provides a parallelization process for models that require more than a single pod to run inference or train on.
### b) Technology Acceptance
Substantial work has been conducted on the topic of technology acceptance, and the Technology Acceptance Model (TAM), first proposed by Davis (1986), is the most commonly employed and influential theory related to an individual's acceptance of information technology (IT; Lee et al. 2003). TAM enables researchers to understand how users will respond when interacting with a new technology. It builds on Ajzen and Fishbein's (1980) theory of reasoned action, and it assumes that an individual's acceptance of IT is determined by two primary variables: perceived usefulness and perceived ease of use. It is very versatile, being able to be applied to various technologies in various situations with different control factors and with different subjects.
When discussing the results of prior research utilizing TAM, Lee et al. (2003) identify four categories of target IT systems: communications systems, general-purpose systems, office systems and specialized business systems. The issue with TAM is that it is specifically intended to analyze case studies in business applications, and is intended largely to provide theoretical contributions. It is intended to have implications for practitioners, but this is not the case in practice. Moreover, it is thought by researchers in information systems research to be a topic that academics should avoid because it is devoid of valuable contribution, and, in a period of what might seem to be a Kuhnian "mopping-up" period, or even a post "mopping-up" period (Kuhn 1962).
### c) AI-Based Software
We conducted literature reviews of expert systems' and decision support systems' literature, first identifying existing surveys to provide an overview, and then using a bibliometric approach. For the bibliometric approach we used very generic search terms, and it was clear from the start that, for both decision support systems and expert systems, we would be unable to get useful results for a review so broad in scope.
For both topics we queried the database Scopus database, which allowed for querying large numbers of abstracts. We conducted our queries in May of 2022. Given our interest in enhancing scientific research productivity with foundation models, we focused broadly on decision support systems and expert systems to try to understand broad adoption trends.
### d) Decision Support Systems
## i. Existing Surveys
Prior to our bibliometric analysis of decision support systems literature, but using the results from our Scopus query, we reviewed extant literature reviews on decision support systems. After filtering the articles with 100 citations or more from the "decision support system" query, we identified those that were either surveys or literature reviews. There were several well-cited and broad literature reviews on the topic. The most significant of these involves a series of three surveys covering different spans of time: from 1971 to 1988 (Eom and Lee 1990), from 1988 to 1994 (Eom et al. 1998), and from 1995 to 2001 (Eom and Kim 2006). We summarize these literature reviews below:
- The first literature review in this group covering the earliest period-from 1971 to 1988 (Eom and Lee 1990)-concludes that Alter's proposed taxonomy for information systems (Alter 1977) was not suitable for decision support systems and proposed that integrating the separate decision-support systems that coexist in an organization was the next task in the future.
- The second literature review of this series covers the middle period-from 1988 to 1994 (Eom et al. 1998). In this survey, the authors proposed that: 1) supporting strategic decisions and the application of decision support systems to global management decision making should be the focal point of decision support system research, 2) the production and operations management and management information systems areas have become the two predominant fields of decision support systems research between the 1980s and the first half of the 1990s, and 3) graphics, visual interactive modeling, artificial intelligence techniques, fuzzy sets, and genetic algorithms had become widely used as decision support system tools.
- The third installment of this series, covering the final time frame-between 1995 and 2001 (Eom and Kim 2006)-concludes that during this time there were several important changes in decision support system application development including the development of negotiation support systems, organizational decision support systems, interorganizational decision support systems, intelligent decision support systems, and web-based decision support systems.
We identified one other decision support systems literature review worth mentioning. Hosack et al. (2012) conducted a literature review to assess the future of decision support systems research. This study came to three valuable conclusions:
1. The paper suggested using the term decision support within a work system.
2. For research to continue to produce meaningful ideas for organizations, researchers of the future must strive to integrate technology evolution into the concept of organizational decision support while understanding that technology, decision-making processes, and organizational support are different foci of the research.
3. They predicted that knowledge management-based decision support systems and data warehousing, social media decision support, mobile computing, negotiation support would drive future trends in decision support systems research.
Clearly, these surveys did not illuminate any extant research relevant to the adoption of decision support systems for scientific applications. The technology acceptance model (TAM) remained the only robust body of relevant literature on technology acceptance (Davis 1989), but was insufficient for providing the guidance desired in this study related to adoption of new AI tools for scientific applications and expediting scientific progress.
Moreover, our literature review discovered that there were many, many more surveys of decision support system literature related to specific types of decision support systems. For example, reviews on a broad range of topics from agricultural decision support systems (Zhai et al. 2020), to manufacturing decision support systems (Kasie et al. 2017), to agent-based decision support systems for clinical management and research (Foster et al. 2005), to knowledge-based decision support systems in financial management (Zopounidis et al. 1997), to decision support systems' use in dental practices (Goh et al. 2016). A very large number of literature reviews focus on clinical decision support systems (Wright et al. 2016[^11]; Kawamoto et al. 2005; Ahmadian et al. 2011; Kaushal et al. 2003; Sittig et al. 2006; Robinson et al. 2010). There is even a review related specifically to AI in clinical decision support systems (Montani et al. 2019). There are even numerous surveys on the use of machine learning in decision support systems alone (Hogenboom et al. 2016; Merkert et al. 2015; Ngai et al. 2011). There are many more domain-specific literature reviews, but we feel that those cited here demonstrate the breadth and volume of literature reviews on domain-specific topics as opposed to those more broadly on decision support systems research as a whole.
## ii. Bibliometric Analysis
On the topic of decision support systems, we collected 120,019 abstracts using the search term "decision support systems". We used latent Dirichlet allocation (LDA; Blei et al. 2002), a statistical natural language processing technique widely used for topic modeling to identify the salient topics in the corpus. Based on the criterion of perplexity, commonly used as an evaluation metric when using LDA, it was determined that 23 topics was an optimal number of topics. We used 1-gram analysis with a default set of stop words and a default search for hyperparameters.

Figure 3: Above is a word cloud generated from the results of the LDA topic modeling for decision support systems. The trend noticed in the extant literature reviews of a large focus on clinical decision support systems can be seen to some degree with the terms clinical, patients, diagnosis, and health appearing in descending relevance. However, largely there is little with respect to structure in the clusters that is often associated with the use of LDA. We additionally had difficulty labeling the topics due to their poor quality.
Again, extensive effort was not placed on bibliometric analysis because 1) this study was not initially intended to utilize bibliometrics or scientometrics and 2) previous work had not had significant success with bibliometrics. Bibliometrics and scientometrics are more often used for identifying trends and predicting progress in technological development (Daim et al. 2016). Use of large language models may provide better results. However, given the findings of other elements of this literature review, we do not feel that further analysis of the data would have proven very valuable.
### e) Expert Systems
## i. Existing Surveys
As depicted in Figure 2, the use of the term "expert systems" in literature exploded in the 1980s but had largely subsided by the end of the 1990s. Expert systems are a form of AI system that encode expert knowledge for retrieval and use in specific context to support the activities of professionals in a variety of jobs where extensive expertise is required. It could be thought that expert systems use AI techniques for information retrieval to the behavior or judgment of an organization, a human expert, or a group of human experts with exemplary expertise in a specific field.
As with decision support systems, we began by exploring the extant literature reviews on the topic. Again, we attempted to draw literature reviews from the bibliometric search we conducted of the Scopus database, after filtering out articles having less than 100 citations. Doing so, we found one highly cited literature review on the topic. Thus, we expanded our search slightly to try to identify more work.
The most widely cited reviews in this domain was that of Liao (2005) covering work done on expert systems in the decade from 1995 to 2004. This was the period during which interest in the topic was subsiding, at least based on the Google Books Corpus, as depicted in Figure 2. This review reported that, over this period: 1) expert systems methodologies were tending to develop towards expertise orientation and expert systems applications development was a problem-oriented domain; 2) that different social science methodologies, such as psychology, cognitive science, and human behavior could implement expert systems as another kind of methodology; and 3) that the ability to continually change and obtain new understanding is the driving power of expert systems methodologies, and should be the expert systems application of future works.
A text mining or bibliometric analysis of the topic was conducted and published relatively recently by Cortez et al. (2018). This paper talked significantly about authors' national affiliations, and worked used the results to propose a taxonomy which they compared with others, including not only a specialized expert systems taxonomy (Sahin et al., 2013) but also the two general library classification systems: the Dewey Decimal Classifications (DDC; Scott, 1998), and the Library of Congress Classifications (LCC; Chan, 1995). The EXSY journal recently (from 2018) adopted their taxonomy system.
Similar to what we found in decision support systems, there were numerous narrower reviews on specific types of expert systems. For example, we identified reviews on a breadth of subtopics including explanation in expert systems (Moore and Swartout 1998), expert systems in production planning and scheduling (Metaxiotis et al. 2002), expert systems evaluation techniques (Grogono et al. 1993), expert systems for fault detection(), and
Interestingly, expert systems showed up as topics in literature reviews focused on artificial intelligence techniques, as well (Bharammirzaee 2010; Horvitz et al. 1988).
## ii. Bibliometric Analysis
On the topic of expert systems, we collected 65,551 abstracts using the search term "expert systems". We again used latent Dirichlet allocation (LDA; Blei et al. 2002) for our topic modeling. Based on the criterion of perplexity, it was determined that 16 topics was an optimal number of topics. Similar to the LDA analysis of the decision support systems corpus, we used 1-gram analysis with a default set of stop words and a default search for hyperparameters.
 Figure 4: Above is a word cloud generated from the results of the LDA analysis. This illustrates the lack of value in the topics that were identified. It was difficult labeling the clusters in any meaningful way with the results from this process.
Overall, our perception of the expert systems literature was—just like the decision support system literature—that the scope was too broad to produce meaningful results. There were more general literature reviews than with decision support systems, but, in inspecting these studies we were unable to identify insights of substantive value to our goal of enhancing scientific productivity from foundation models. Much may lie in the fact that expert systems, like decision support systems, are more often used in business applications and not for advancing science. We see that much of the time neither decision support systems or expert systems would be categorized as specialized scientific software or generalizable scientific software as we define these terms in this study.
## IV. DISCUSSION
### a) Scientific Software Development
There seem to be lessons that can be learnt from HPC-specific scientific software. One thing that we're not encountering yet is the need to port large language models or foundation models to different HPC compute clusters. However, as the need to test and evaluate increasingly generalizable systems grows, it will likely be necessary to have generic HPC architectures that large language models and foundation models can easily be ported to-at least for inference tasks-in order to test and evaluate them, particularly in the case of final pre-deployment system evaluations.
Particularly, the sensitivity of large AI models/systems to the coprocessor architecture, the system topology, and the interconnect bandwidth, will become an increasingly significant factor to porting large models to other systems. However, it is also critical that large models be deployed in very secure environments with near military levels of information security (Patel 2023). Therefore, any government facilities that are designed to test or evaluate such systems need to be very secure, and possibly even airgapped or classified. The challenges of porting HPC software described by others are things that must be avoided for such testing and evaluation protocols to work, and these protocols must be enacted in legislation quickly due to the rapid pace of tech progress and the pace with which legislation is going to need to keep up (e.g., the NIST AI Safety Institute, the Federal AI Risk Management Act of 2023).
### b) Emerging AI Software Tools
Some of the most valuable lessons from the literature regarding the development and adoption of novel software tools might be those taken from the case of the electronic spreadsheet. VisiCalc was novel, and brought new capabilities to non-programmers because it made general computing tasks possible without having to know a programming language or how to write a program. It is also significant to remember how important the user interface and user experience was particularly the ease of use. We also note that Lotus 1-2-3 was able to overtake VisiCalc because it targeted IBM PCs, which were more widely adopted by businesses due to the reputation of IBM.
Other relevant lessons for enhancing scientific productivity from foundation models may involve the open sourcing of such models, but, there are inherent risks in open sourcing such powerful models. Additionally, lessons relevant to this were described in the previous subsection, being drawn from literature on software design in HPC.
For more complex software the users' need for trust increases, as they are not able to independently validate the results provided (Joppa et al. 2013). This is in contrast to previous generalizable scientific software that has been more transparent, with operations that are able to be verified with a calculator. Insights about emerging AI software tools was the inspiration for this study, and this proved to be a very difficult topic to glean insights on. However, we feel there is much greater potential in the automation of science described in the following subsection.
### c) Beyond Scientific Software Tools
AI-powered NLP tools like ChatGPT (OpenAI 2022) have tremendous abilities, including abilities for foresight and creativity (Gruetzemacher 2022), and it would not be prudent to underestimate the transformative potential of AI driven by the capabilities of future systems (Gruetzemacher and Whittlestone 2022).
Moving beyond the notion of simply using foundation model-powered scientific software as a tool for discovery of new proteins (Jumper et al. 2021; Ferruz et al. 2023) or for accelerating human-supervised literature review (Gruetzemacher 2022; Manning et al. 2023; Haman and Skolnik 2023), it is possible to consider the use of increasingly powerful systems to automate literature review to the point where systems are able to 1) identify gaps in the existing literature and 2) to propose experiments and hypotheses to contribute to the body of knowledge in a field or domain. Perhaps this might be useful for scientific progress, albeit the mundane, or what Kuhn (1962) refers to as the "mopping-up".
Science has been thought to fundamentally be a process of conjectures and refutations (Popper 1963), and while at present much of experimentation seems likely to require human involvement, it is easy to expect that conjectures could be made by powerful foundation models in the near future. Moreover, conjectures that involve hypotheses testable by computational experiments might either avoid falsification or be refuted without human involvement. This is why Shevlane et al. (2023) foresee automation of AI research as an extreme risk. Ignoring that this is considered a risk, it is obvious that hypotheses beyond just machine learning or computer science can also be falsified computationally. Thus, we could see automation of such scientific areas in the future, first with "mopping-up" (Kuhn 1962) types of research, and later with novel or profound work.
Given the pace of recent progress in AI (Sevilla et al. 2022), and that progress is likely to continue $^{12}$ (Gruetzemacher et al. 2020) with continued scaling of model's training compute and dataset size (Amodei and Hernandez 2018; Kaplan et al. 2020), we must be cautious to not ignore these seemingly science fiction possibilities. Thus, this has significant potential for future work. In fact, we feel that a complete research agenda on the topic of automation of science is merited, but we outline some specific starting points for future work below.
## i. Future work
One obvious starting point is to start experimentally trying to determine what hypothesis generation capabilities exist in today's cutting edge frontier models like GPT-4 (OpenAI 2023). Simple experiments could begin to uncover this, and we foresee a large range of potential experiments that could demonstrate different abilities of this phenomena. For example, simply identifying ten papers from a research group that could be confirmed to not be in the training data for a model, and then prompting the model assuming a large enough context window, such as that with Claude 2 (Anthropic 2023) of 100,000 tokens-with the papers, asking it to propose new experiments and hypotheses. The results from this could simply be compared to the research group's actual plans for new experiments, or those that are published in the following six to twelve months.
Many variations of the above experiment could be conducted, and this could be done over a variety of domains. It might be useful to identify strengths and weaknesses of early systems, even if current systems are not practically useful, so as to anticipate weaknesses in future systems, and how we might go about addressing such deficiencies to expedite scientific progress.
Beyond just exploring the proof-of-concept, work could be done on the other half of the automation of science; i.e., for domains where experiments can be conclusively decided computationally. Research could be conducted to evaluate how well systems were able to take existing code from previous experiments in computational fluid dynamics or computational biology, and extend or adapt that code accurately and precisely enough to conduct an experiment testing a different hypothesis. These experiments need not begin with hypotheses generated from the systems, but rather, with very basic hypotheses simply extending the previous computational experiment. The key to this would be to understand the limitations of current foundation models at coding for scientific computing applications. It would be interesting to work on predicting whether the bottleneck for automating computational research disciplines will lie in the rigorous and robust 1) hypothesis creation, 2) design of experiments, or 3) execution of experiments.
Research along these lines could pave the way for a new pseudo-discipline of automated science. Previous work has described automated science for decades (King et al. 2009; Lenat 1979), but foundation models have unprecedented potential for this process. Further work should attempt to better understand how this might impact the economy and society, ensuring that rapid progress on this type of research does not wind up disproportionately benefitting the wealthiest of nations and ignoring the impacts to the Global South.
## V. CONCLUSION
This paper has described an extensive effort to use literature review to identify potential paths for enhancing scientific research productivity through the use of foundation models. The initial plan, to review decision support systems and expert systems literature did not reveal much of value because the survey was overly ambitious. This was evidenced by previous literature reviews on these topics, which largely focused on reviews specific subtopics of the content in these broad topics. A review of the development of scientific software, such as literature on HPC software, as well as a review of applications often not considered scientific software, like the electronic spreadsheet, offered some useful insights, but none of the magnitude that we had sought.
During the course of the study, tremendous changes occurred in the field of artificial intelligence research, particularly the release of ChatGPT (OpenAI 2022) and the addition of GPT-4 (OpenAI 2023) into ChatGPT Plus. This has changed AI research dramatically, leading to governments taking seriously the transformative potential of AI for society more broadly (Gruetzemacher and Whittlestone 2022; Lazar and Nelson 2023). In the final subsection of the discussion we discussed some salient activities for future work to explore involving the use of advanced AI for driving and expediting scientific progress. We are particularly keen on the idea of using foundation models for automating scientific research, and encourage future work in this direction. Pursuing such research may avoid the limitations encountered by this study by looking forward to anticipate enhancing scientific software research productivity instead of looking backward.
### ACKNOWLEDGEMENTS
We especially thank our co-investigator, Dr. Huigang Liang, who was tremendously helpful in this research. We thank Christy Manning for comments and suggestions at different stages of the process. This research was generously supported by the Alfred P. Sloan Foundation as part of the Better Software for Science program.
[^3]: Interested readers can refer to Gruetzemacher and Paradice (2022). _(p.1)_
[^4]: Given the tremendous potential for capabilities such as those demonstrated by DALL-E 2, foundation models are expected to lead to a new generation of Aldriven software tools for enhancing creativity and productivity (Gruetzemacher 2022). Foundation models are actually thought to be a general purpose technology (GPT; Bommasani et al. 2021), with the potential to transform society in a manner similar to previous GPTs like electricity or the internal combustion engine (Lipsey et al. 2005). It is difficult to imagine how an emerging technology with such tremendous transformative potential will come to be used in society, much like it would be difficult to anticipate the impact that electricity would later have in 1882 when electricity generation began to first be used to light streets at night. We are _(p.2)_
[^6]: $^{6}$ Tools like Elicit, from ought, are already attempting to become the next 'killer app': https://www.elicit.org. _(p.4)_
[^7]: https://books.google.com/ngrams/ _(p.4)_
[^8]: The first edition was published in 1963, and the current edition, published in 2015, is the 7th edition of the manual. _(p.5)_
[^9]: For more on this topic, interested readers can see Romano et al. (2002) or Liberatore and Pollack Johnson (2003). _(p.6)_
[^10]: https://www.top500.org/lists/top500/2023/11/ _(p.7)_
[^11]: We concluded from these results, and their poor quality, that the breadth of the topic was too great to identify the types of trends we sought for providing a guide to enhancing scientific research productivity using foundation models. Foundation models are a novel, emerging technology, with emergent capabilities themselves (Bommasnie et al. 2021) that are difficult to predict (Wei et al. 2022). Thus, there are inherent challenges in finding insights that apply to our target topic, beyond just the challenges in the overly ambitious aims of our study. _(p.9)_
[^1]: Google's DeepMind AI research lab has a goal of "solving intelligence to advance science and humanity" (Hassabis 2022). _(p.1)_
[^2]: ${}^{2}$ AI has historically gone through two previous hype cycles that have been followed by periods of reduced interest and funding. The periods of reduced interest and funding are commonly described as AI winters. _(p.1)_
[^5]: AlphaFold is the system that was used for this, and the database can be found at: https://alphafold.ebi.ac.uk/. _(p.3)_
[^12]: Albeit possibly not as quickly as in the past five years (Gruetzemacher et al. 2020). _(p.12)_
Leila Ahmadian,Mariette Van Engen-Verheul,Ferishta Bakhshi-Raiez,Niels Peek,Ronald Cornet,Nicolette De Keizer (2011). The role of standardized data and terminological systems in computerized clinical decision support systems: Literature review and survey.
S Alter (1977). Designing a decision support system for working capital management.
Anthropic (2023). Model Card and Evaluations for Claude Models.
I Azjen,M Fishbein (1980). Understanding attitudes and predicting social behavior.
P Barham,A Chowdhery,J Dean,S Ghemawat,S Hand,D Hurt,M Isard,H Lim,R Pang,S Roy,B Saeta (2022). Pathways: Asynchronous distributed dataflow for ml.
V Basili,J Carver,D Cruzes,L Hochstein,J Hollingsworth,F Shull,M Zelkowitz (2008). Understanding the high-performancecomputing community: A software engineer's perspective.
Arash Bahrammirzaee (2010). A comparative survey of artificial intelligence applications in finance: artificial neural networks, expert system and hybrid intelligent systems.
David Blei,Andrew Ng,Michael Jordan (2003). Latent Dirichlet Allocation.
D Borthakur (2007). The hadoop distributed file system: Architecture and design.
T Brown,B Mann,N Ryder,M Subbiah,J Kaplan,P Dhariwal,A Neelakantan,P Shyam,G Sastry,A Askell,S Agarwal (2020). Language models are few-shot learners.
R Bommasani,D Hudson,E Adeli,R Altman,S Arora,S Von Arx,M Bernstein,J Bohg,A Bosselut,E Brunskill,E Brynjolfsson (2021). On the opportunities and risks of foundation models.
Erik Brynjolfsson,Daniel Rock,Chad Syverson (2018). Artificial Intelligence and the Modern Productivity Paradox.
Martin Campbell-Kelly (2003). The rise and rise of the spreadsheet.
M Castelluccio (2019). THE VISICALC DAWN.
L Chan (1995). Library of Congress Classification: Alternative Provisions.
A Chowdhery,S Narang,J Devlin,M Bosma,G Mishra,A Roberts,P Barham,H Chung,C Sutton,S Gehrmann,P Schuh (2022). Palm: Scaling language modeling with pathways.
Paulo Cortez,Sérgio Moro,Paulo Rita,David King,Jon Hall (2018). Insights from a text mining survey on Expert Systems research from 2000 to 2016.
T Daim,D Chiavetta,A Porter,O Saritas (2016). Anticipating future innovation pathways through large data analysis.
F Davis,V Venkatesh (1986). Toward Preprototype User Acceptance Testing of New Information Systems: Implications for Software Project Management.
F Davis (1989). Perceived usefulness, perceived ease of use, and user acceptance of information technology.
J Dean,S Ghemawat (2004). MapReduce: Simplified data processing on large clusters.
J Degrave,F Felici,J Buchli,M Neunert,B Tracey,F Carpanese,T Ewalds,R Hafner,A Abdolmaleki,D De Las Casas,C Donner (2022). Magnetic control of tokamak plasmas through deep reinforcement learning.
T Eloundou,S Manning,P Mishkin,D Rock (2023). Gpts are gpts: An early look at the labor market impact potential of large language models.
Hyun Eom,Sang Lee (1971). A Survey of Decision Support System Applications (1971–April 1988).
S Eom,S Lee,E Kim,C Somarajan (1998). A survey of decision support system applications (1988–1994).
S Eom,E Kim (2006). A survey of decision support system applications (1995-2001.
Wee Goh,Xiaohui Tao,Ji Zhang,Jianming Yong (2016). Decision support systems for adoption in dental clinics: A survey.
A Grannan,K Sood,B Norris,A Dubey (2020). Understanding the landscape of scientific software used on high-performance computing platforms.
R Gruetzemacher (2022). Natural Gas. Police Power.
Ross Gruetzemacher,David Paradice,Kang Lee (2020). Forecasting extreme labor displacement: A survey of AI practitioners.
R Gruetzemacher,D Paradice (2022). Deep Transfer Learning & Beyond: Transformer Language Models in Information Systems Research.
Ross Gruetzemacher,Jess Whittlestone (2022). The transformative potential of artificial intelligence.
Michael Haman,Milan Školník (2023). Using ChatGPT to conduct a literature review.
Frederik Hogenboom,Flavius Frasincar,Uzay Kaymak,Franciska De Jong,Emiel Caron (2016). A Survey of event extraction methods from text for decision support systems.
N Ferruz,M Heinzinger,M Akdel,A Goncearenco,L Naef,C Dallago (2023). From sequence to function through structure: Deep learning for protein design.
D Foster,C Mcgregor,S El-Masri (2005). A survey of agent-based intelligent decision support systems to support clinical management and research.
Peter Grogono,Aïda Batarekh,Alun Preece,Rajjan Shinghal,Ching Suen (1993). Expert system evaluation techniques: a selected bibliography.
D Hassabis (2022). Using AI to Accelerate Scientific Discovery.
Eric Horvitz,John Breese,Max Henrion (1988). Decision theory in expert systems and artificial intelligence.
Bryan Hosack,Dianne Hall,David Paradice,James Courtney (2012). A Look Toward the Future: Decision Support Systems Research is Alive and Well.
James Howison,Ewa Deelman,Michael Mclennan,Rafael Ferreira Da Silva,James Herbsleb (2015). Understanding the scientific software ecosystem and its impact: Current and future measures.
Lucas Joppa,Greg Mcinerny,Richard Harper,Lara Salido,Kenji Takeda,Kenton O'hara,David Gavaghan,Stephen Emmott (2013). Troubling Trends in Scientific Software Use.
Norm Jouppi,George Kurian,Sheng Li,Peter Ma,Rahul Nagarajan,Lifeng Nai,Nishant Patil,Suvinay Subramanian,Andy Swing,Brian Towles,Clifford Young,Xiang Zhou,Zongwei Zhou,David Patterson (2023). TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings.
J Jumper,R Evans,A Pritzel,T Green,M Figurnov,O Ronneberger,K Tunyasuvunakool,R Bates,A Žídek,A Potapenko,A Bridgland (2021). Highly accurate protein structure prediction with AlphaFold.
J Kaplan,S Mccandlish,T Henighan,T Brown,B Chess,R Child,S Gray,A Radford,J Wu,D Amodei (2020). Scaling laws for neural language models.
F Kasie,G Bright,A Walker (2017). Decision support systems in manufacturing: a survey and future trends.
Kensaku Kawamoto,Caitlin Houlihan,E Balas,David Lobach (2005). Improving clinical practice using clinical decision support systems: a systematic review of trials to identify features critical to success.
Rainu Kaushal,Kaveh Shojania,David Bates (2003). Effects of Computerized Physician Order Entry and Clinical Decision Support Systems on Medication Safety.
Ross King,Jem Rowland,Stephen Oliver,Michael Young,Wayne Aubrey,Emma Byrne,Maria Liakata,Magdalena Markham,Pinar Pir,Larisa Soldatova,Andrew Sparkes,Kenneth Whelan,Amanda Clare (2009). The Automation of Science.
Alex Krizhevsky,Ilya Sutskever,Geoffrey Hinton (2012). ImageNet classification with deep convolutional neural networks.
V Kopytoff,L Ibrahim,R Socher (9092). Delivering On The Promise Of Health Information Technology In 2022.
T Kuhn (1962). The structure of scientific revolutions.
S Lazar,A Nelson (2023). AI safety on whose terms?.
K Kozar,K Larsen (2003). The technology acceptance model: Past, present, and future.
Douglas Lenat (1979). Automated Theory Formation in Mathematics.
S Liao (2005). Expert system methodologies and applications-a decade review from 1995 to 2004.
M Liberatore,B Pollack-Johnson (2003). Factors influencing the usage and selection of project management software.
R Lipsey,K Carlaw,C Bekar (2005). Economic transformations: general purpose technologies and long-term economic growth.
C Manning,S Zhuma,S Nagrecha,T Koutogui,M Yessoufou,R Gruetzemacher (2023). Streamlining Science: Recreating Systematic Literature Reviews with AI-Powered Decision Tools.
J Merkert,M Mueller,M Hubl (2015). A survey of the application of machine learning in decision support systems.
K Metaxiotis,Dimitris Askounis,John Psarras (2002). Expert systems in production planning and scheduling: A state-of-the-art survey.
V Mnih,K Kavukcuoglu,D Silver,A Rusu,J Veness,M Bellemare,A Graves,M Riedmiller,A Fidjeland,G Ostrovski,S Petersen (2015). Human-level control through deep reinforcement learning.
Joel Mokyr,Chris Vickers,Nicolas Ziebarth (2015). The History of Technological Anxiety and the Future of Economic Growth: Is This Time Different?.
Stefania Montani,Manuel Striani (2019). Artificial Intelligence in Clinical Decision Support: a Focused Literature Survey.
J Moore,W Swartout (1988). Explanation in expert systems: A survey.
(2019). Reproducibility and Replicability in Science.
E Ngai,Y Hu,Y Wong,Y Chen,X Sun (2011). The application of data mining techniques in financial fraud detection: A classification framework and an academic review of literature.
(2015). Frascati Manual 2015.
J Okerlund,E Klasky,A Middha,S Kim,H Rosenfeld,M Kleinman,S Parthasarathy (2022). What Should We Do About Slavery?.
Openai (2022). Introducing ChatGPT.
Openai (2023). Unknown Title.
A Paszke,S Gross,F Massa,A Lerer,J Bradbury,G Chanan,T Killeen,Z Lin,N Gimelshein,L Antiga,A Desmaison (2019). Pytorch: An imperative style, high-performance deep learning library.
D Patel (2023). Dario Amodei (Anthropic CEO) -Scaling, Alignment, & AI Progress.
K Popper (1963). Conjectures and refutations: The growth of scientific knowledge.
A Ramesh,P Dhariwal,A Nichol,C Chu,M Chen (2022). Hierarchical text-conditional image generation with clip latents.
S Reed,K Zolna,E Parisotto,S Colmenarejo,A Novikov,G Barth-Maron,M Gimenez,Y Sulsky,J Kay,J Springenberg,T Eccles (2022). A generalist agent.
Jane Robertson,Emily Walkom,Sallie‐anne Pearson,Isla Hains,Margaret Williamson,David Newby (2010). The impact of pharmacy computerised clinical decision support on prescribing, clinical and patient outcomes: a systematic review of the literature.
N Romano,Fang Chen,J Nunamaker (2002). Collaborative Project Management Software.
Jonathan Sachs (2007). Recollections: Developing Lotus 1-2-3.
S Sahin,M Tolun,R Hassanpour (2012). Hybrid expert systems: A survey of current approaches and applications.
M Scott,M Scott (1998). Dewey decimal classification.
Robert Service (2020). ‘The game has changed.’ AI triumphs at protein folding.
Jaime Sevilla,Lennart Heim,Anson Ho,Tamay Besiroglu,Marius Hobbhahn,Pablo Villalobos (2022). Compute Trends Across Three Eras of Machine Learning.
T Shevlane,S Farquhar,B Garfinkel,M Phuong,J Whittlestone,J Leung,D Kokotajlo,N Marchal,M Anderljung,N Kolt,L Ho (2023). Model evaluation for extreme risks.
K Shvachko,H Kuang,S Radia,R Chansler (2010). The hadoop distributed file system.
David Silver,Aja Huang,Chris Maddison,Arthur Guez,Laurent Sifre,George Van Den Driessche,Julian Schrittwieser,Ioannis Antonoglou,Veda Panneershelvam,Marc Lanctot,Sander Dieleman,Dominik Grewe,John Nham,Nal Kalchbrenner,Ilya Sutskever,Timothy Lillicrap,Madeleine Leach,Koray Kavukcuoglu,Thore Graepel,Demis Hassabis (2016). Mastering the game of Go with deep neural networks and tree search.
D Sittig,M Krall,R Dykstra,A Russell,H Chin (2006). A survey of factors affecting clinician acceptance of clinical decision support.
J Wei,Y Tay,R Bommasani,C Raffel,B Zoph,S Borgeaud,D Yogatama,M Bosma,D Zhou,D Metzler,E Chi (2022). Emergent abilities of large language models.
E Wilson (1999). Consilience: The unity of knowledge.
Adam Wright,Thu-Trang Hickman,Dustin Mcevoy,Skye Aaron,Angela Ai,Jan Andersen,Salman Hussain,Rachel Ramoni,Julie Fiskio,Dean Sittig,David Bates (2016). Analysis of clinical decision support system malfunctions: a case series and survey.
M Zaharia,M Chowdhury,T Das,A Dave,J Ma,M Mccauly,M Franklin,S Shenker,I Stoica (2012). Resilient distributed datasets: A {Fault-Tolerant} abstraction for {In-Memory} cluster Leveraging Foundation Models for Scientific Research Productivity Global Journal of Computer Science and Technology ( D ).
Z Zhai,J Martínez,V Beltran,N Martínez (2020). Decision support systems for agriculture 4.0: Survey and challenges.
C Zopounidis,M Doumpos,N Matsatsinis (1997). On the use of knowledge-based decision support systems in financial management: A survey.
M Zynda (2013). The first killer app: A history of spreadsheets.
No ethics committee approval was required for this article type.
Data Availability
Not applicable for this article.
How to Cite This Article
Ross Gruetzemacher. 2026. \u201cLeveraging Foundation Models for Scientific Research Productivity\u201d. Global Journal of Computer Science and Technology - D: Neural & AI GJCST-D Volume 23 (GJCST Volume 23 Issue D3): .
Explore published articles in an immersive Augmented Reality environment. Our platform converts research papers into interactive 3D books, allowing readers to view and interact with content using AR and VR compatible devices.
Your published article is automatically converted into a realistic 3D book. Flip through pages and read research papers in a more engaging and interactive format.
The objective of this work was to elucidate paths for expediting and enhancing scientific research productivity from the emerging AI paradigm of foundation models (e.g., ChatGPT). Faster scientific progress can benefit mankind by speeding up progress toward solutions to shared human problems like cancer, aging, climate change, or water scarcity. Challenges to foundation model adoption in science threaten to slow progress in such research areas. This study attempted to survey decision support systems and expert system literature to provide insights regarding these challenges. We first reviewed extant literature on these topics to try to identify adoption patterns that would be useful for this purpose. However, this attempt, using a bibliometric approach and a very high level traditional literature review, was unsuccessful due to the overly broad scope of the study. We then surveyed the existing scientific software domain, finding there to be a huge breadth in what constitutes scientific software. However, we do glean some lessons from previous patterns of adoption of scientific software by simply looking at historical examples (e.g., the electronic spreadsheet)
Our website is actively being updated, and changes may occur frequently. Please clear your browser cache if needed. For feedback or error reporting, please email [email protected]
Thank you for connecting with us. We will respond to you shortly.




































































