## I. INTRODUÇÃO
ste trabalho trata de evidências derivadas da ciência de dados para políticas educacionais na realidade brasileira. O problema abordado é de que a geração de múltiplas evidências, tratando das mais diversas questões, pode gerar dispersão de questões essenciais, que perduram como fatores crônicos de desigualdade na garantia do Direito à Educação. Tal discussão é especialmente oportuna em razão da massificação do uso da Inteligência Artificial (IA) para gerar evidências relativas a políticas públicas. A relevância é configurada pela proposição de mecanismo para garantir que os fatores predominantes nas questões sociais do Brasil não sejam deixados de lado sem que isso repercuta na confiabilidade do estudo ou proposta de evidência.
Foram Definidos os Seguintes Objetivos: i) discutir técnicas que a matemática utiliza para tratar as perdas de informação e dimensionar erros quando ocorre a transição da matemática (abstrata) para o dado (digital); ii) argumentar que, na construção de evidências para políticas educacionais, é necessário explicitar os erros decorrentes da perda de informação quando se transpõe a realidade para o dado; iii) analisar a potencialização do uso de evidências em razão da massificação da inteligência artificial; iv) propor mecanismo de análise da razoabilidade de evidências, quando tratam de questões educacionais na realidade brasileira.
O Brasil possui história particular e dela decorre a persistente desigualdade estrutural do país. Quando nos afastamos deste conhecimento, são frustrados muitos esforços para reduzi-la, a qual segue amparada por nosso modelo social e mental. Como alerta Morin (2014), pensar reformas exige que primeiro se reforme o pensamento. Sem uma nova perspectiva cognitiva, as propostas de interpretação ou de mudança social serão pensadas a partir dos mesmos modelos que construíram a desigualdade. Isso apenas fará com que ela perdure como problema público (Oliveria; Silva, 2019; Silveira; Palomo, 2023).
O papel das políticas públicas é tratar de problemas públicos e, para isso, é preciso analisar as grandes questões e modelos hegemônicos ou emergentes, sendo que, para essas identificações "nitidez não é uma opção" (BALL, 2014, p. 44). Sem a compreensão das bases de problemas públicos, os esforços tendem a tratar de aspectos decorrentes do problema, não dele propriamente.
Em razão do dissenso de opiniões e perspectivas para a configuração de políticas educacionais, há forte movimento para que sejam utilizadas evidências produzidas em estudos específicos, ou em precedentes da experiência internacional, a despeito de especialistas alertarem para o equívoco de transposições simplificadoras no campo da Educação Comparada (Bray et. al., 2015; Wathier, 2016). Evidências correspondem a constatações objetivas, em regra, baseadas em vasta gama de dados. Tais assertivas são caracterizadas pela "curiosa e ao mesmo tempo reveladora mescla de descrição e prescrição" (Ball, 2011, p. 103).
Consideremos a política pública como um "fluxo de decisões públicas, orientado a manter o equilíbrio social ou a introduzir desequilíbrios destinados a modificar essa realidade" (Saravia, 2006, p. 28). Em seguida, reconheçamos que o Brasil equilibra (sustentado e sustentando) a desigualdade crônica. Portanto, é essencial praticar políticas que gerem desequilíbrios, a fim de viabilizar efetivas reorganizações. Para isso, análises elementares e conhecimento mínimo da história brasileira trazem robustas evidências de bases que combinam racismo, machismo e desigualdade socioeconômica (Matias; Barros, 2022), na qual é essencial incluir renda e patrimônio. Apesar das fortes narrativas em relação à importância de adotar políticas baseadas em evidências, muitas vezes a seleção das evidências que serão consideradas parece negligenciar a relevância desses aspectos.
A proposta deste artigo requer questionar se, nesses casos, o que se está apresentando são evidências para aprimorar a política pública, para justificar crenças precedentes, ou para camuflar a manutenção do status quo. Há conhecimento suficiente dos problemas estruturais crônicos, o que torna inadmissível desconsiderar os fatores (múltiplos e conjuntos) de nossa desigualdade. Buscar outros conhecimentos é saudável, desde que o deleite de aplicar técnicas requintadas e linguajar rebuscado não seja utilizado como subterfúgio para desconsiderar questões essenciais de nossa sociedade.
A partir dessa problemática, nossa contribuição, aqui, é desenvolver uma análise que coloque em diálogo a perspectiva social e os mecanismos da matemática, apresentando técnicas que ela própria adota para gerir as perdas de informação e, por consequência, os erros causados pela transposição do número abstrato para o dado. Em seguida, problematizaremos o movimento da realidade para o dado, analisando o quanto a inteligência artificial pode potencializar erros de análise. Por fim, propomos uma estratégia para gerir os erros de evidências quando não se consideram fatores essenciais, ao menos quando aplicadas à realidade brasileira.
### a) De Onde Partimos
Para este ensaio, dois termos são essenciais: o de evidência e o de interseccionalidade, ambos especialmente quando associados a políticas educacionais. Tais termos estão em voga no debate nacional e internacional, sendo que sua intersecção é um terreno de tensões e disputas, explicitando a complexa governança das políticas educacionais (Saura; Adrião, 2024; Bortot; Da Silva Scaff, 2023; Sakata, 2023).
Levantamento do estado da arte mostra que há diversas análises acerca da relevância e da criticidade do tema de políticas baseadas em evidências, sobretudo quanto aos critérios de construção e interpretação. A temática é abordada por diversas perspectivas no cenário global (Souza et al., 2021; Howlett et al., 2022; Camargo; Yonekura, 2023; Oliveira; Pereira, 2024; Lichand; Christen, 2020).
Estudos situados no Brasil abordam desde a necessidade de definição conceitual (Pinheiro, 2020), passando pelos desafios metodológicos (Fernandes; Senhoras, 2022), até efeitos de questões específicas como exclusão digital (Sorj; Guedes, 2005), trajetórias educacionais (Soares; Alves; Fonseca, 2021), o Ensino Médio (Silva; Carvalho, 2024), informática na educação (Bittencourt; Isotani, 2018), recursos educacionais para estudantes do espectro autista (Andrade et al, 2024), relação entre financiamento e desempenho (Panassol, 2020), fechamento de escolas do campo (Dos Santos, 2025), educação socioemocional no ambiente escolar (Da Silva et al, 2025). De mapeamentos (De Souza; Dos Santos Silva; Nunes, 2020) a análises críticas (De Faria, 2022), percebe-se um tema em pauta e um consenso distante. Além das essenciais discussões sobre o fato de que ao tempo que não se pode colocar resultados quantitativos em pedestais, também não se pode avançar em políticas com pensamento baseado em negacionismo científico, como alerta Da Costa (2024), em razão de correntes conservadoras no Brasil e no mundo.
No contexto internacional, distintos agentes, das mais diversas perspectivas, têm investigado a interseccionalidade (Clacso, 2022; Corrigan et al., 2023; OECD, 2023; Prior et al., 2022), fato que demonstra a força do conceito. No Brasil, a discussão também é presente, ao se tratar de políticas públicas, incluindo as educacionais. Abordagens construídas por diferentes perspectivas trazem em comum o reconhecimento da interseccionalidade (Dias, 2022; Faria, 2022; Farranha; Silva, 2021; Fonseca, 2024; Henriques, 2015; Oliveira; Valentim, 2023; Santos et al., 2023; Silveira; Nardi, 2017).
Com isso, parece-nos que os autores têm assimilado a perspectiva interseccional como um fator de credibilidade, no entendimento de que ignorá-la é fragilizar seus estudos. Tem-se, assim, o reconhecimento de Crenshaw (2002) ao apresentar a interseccionalidade como uma ferramenta analítica que ajuda a compreender como diferentes formas de discriminação se sobrepõem e se reforçam mutuamente.
A premência destes dois conceitos, oriundos de diferentes correntes, leva à necessidade de análise crítica quanto à interação, de modo que técnicas de ciência de dados reconheçam a relevância da interseccionalidade, ao invés de ofertarem múltiplas outras variáveis potencialmente explicativas, essencialmente por serem as que estão presentes nos dados de curtas séries históricas. O'Neil (2016) mostra como modelos matemáticos imprecisos podem se tornar armas de destruição algorítmica, ao codificar e perpetuar desigualdades estruturais.
Como já defendemos antes, trata-se de ferramentas, cujas finalidades assumidas são outras, mas que podem se converter em armas a depender do uso que fazemos delas. Tal tipo de ferramenta é também chamado de arma branca. A ciência de dados pode facilmente converter-se em uma arma branca (Wathier et al, 2023), ainda que em outra acepção, pois, como enfatizam Garcia e Silva (2023), a omissão desses fatores nas análises computacionais pode constituir um racismo algorítmico silencioso. Noble (2018) explicita que os algoritmos operam sobre bases de dados enviesadas, o que frequentemente resulta em reforço de estereótipos sociais.
Apontamentos feitos especialmente por pesquisadoras indicam a relevância de aspectos que, em geral, não estão comportados nos dados. Como exemplo, podemos citar que a ausência de uma metaética feminina na IA pode agravar lacunas de responsabilidade ética (Siapka, 2023), ou que múltiplas opressões interseccionais refletem na solidão da mulher negra, as quais são negligenciadas pelas análises objetivas (Mizael, Barrozo e Hunziker, 2023). Como expressa Mitchell (2024, p. 271), as tecnologias que aprendem com dados "se limitan a captar el sexismo y otros sesgos de nuestro lenguage, y nuestro lenguage refleja los prejuicios de nuestra sociedad".
As justificativas muitas vezes baseiam-se nos limites dos dados disponíveis, mas nem por isso deixase de, com esses dados, fazer prescrições. Mais sério: sem indicar expressamente essas limitações, que podem levar a erros de inferência e, se as conclusões forem utilizadas como evidências, os equívocos nas políticas públicas educacionais podem ser catastróficos.
### b) Um Olhar Pela Lente Matemática: Gerenciar Erros
Um exemplo elementar de como a realidade não cabe no número pode ser percebido na relação entre o comprimento da circunferência e seu diâmetro. Há muitos séculos sabe-se que existe uma relação direta e proporcional entre o comprimento de uma circunferência e o seu diâmetro. Convencionou-se chamar este resultado de pi, representado pela letra grega (tt). Ocorre que, embora representada internacionalmente por este símbolo comum, até hoje não se conhece o resultado numérico preciso desta relação. Alguns cálculos já especificaram dezenas de trilhões de casas decimais. Pelos nossos padrões numéricos atuais, perduraremos sem conhecer este número de forma precisa (Barros; De Sá, 2022).
Portanto, embora conheçamos círculos, comprimentos de circunferências e diâmetros, eles não podem ser medidos com precisão nem representados numericamente com exatidão. Embora muitos de nós saibamos disso, temos dificuldade em reconhecer e agir a partir das verdades decorrentes (ou corolários). Essa negligência revela-se na recorrente tentativa de falar de números como se refletissem a realidade, a verdade sobre os fatos, ou uma suposta exatidão.
O pi é um único número, mas não há computador capaz de armazená-lo com precisão. Prevendo que essa afirmação possa causar estranheza e desconfiança, cabe consultar uma fonte de informação que usualmente argumenta em favor do potencial das tecnologias digitais, o ChatGPT. A Figura 1a a seguir apresenta uma pergunta feita ao ChatGPT e a resposta dada por esse mecanismo de Inteligência Artificial:
Algum computador existente pode armazenar infinitas casas decimais de um número?
Não — nenhum computador existente (nem mesmo teórico) pode armazenar infinitas casas decimais de um número. Vamos entender por quê:
Fonte: ChatGPT-Pro.
#### Figura 1a: Exemplificação de questão apresentada ao ChatGPT
Para ratificar, foi apresentada uma variação da pergunta ao Gemini, que respondeu conforme Figura a seguir:
Algum computador existente pode armazenar o número conhecido como Pi com exatidão?
Não, nenhum computador existente pode armazenar o número Pi com exatidão (precisão infinita).
Figura 1b: Exemplificação de questão apresentada ao Gemini
Não se trata de argumento especulativo, mas de uma questão fática que é reconhecida tanto pela matemática quanto pela computação. Números que não podem ser representados como razão de dois números inteiros, chamados de irracionais na matemática, não podem ser utilizados para a realização de cálculos numéricos, apenas algébricos (quando a precisão numérica é abstraída e simbolizada por uma letra). Além disso, é reconhecido na matemática que existem mais números irracionais do que números racionais. Portanto, no conjunto dos números que são chamados de Reais, a maioria não pode ser trabalhada com precisão, não pode ser armazenada em nossos potentes computadores digitais, apenas na abstração.
É em razão disso que a matemática assume que a transposição de um número abstrato para o dado gera erro (Ferreira, 2024). Na imagem a seguir, apresentamos as 200 primeiras casas decimais de Pi, destacando as primeiras 50. Supondo que utilizemos estas primeiras para realizar cálculos, todas as casas seguintes gerarão aquilo que chamamos de erro (valor que, conhecida sua existência, é descartado):
3,1415926535897932384626433832795028841971693993751058209749445923078164062862089986280348253
42117067982148086513282306647093844609550582231725359408128481117450284102701938521105559644
62294895493038196 (primeiras 200 casas decimais de pi)
É importante destacar a que se refere este tipo de erro: parcela do número cuja existência é reconhecida, mas que é descartada por limitações técnicas. Neste tipo de erro, há um atenuante, pois quanto mais à direita da unidade o dígito está, menor é seu valor. Especificamente, cada dígito representa apenas $10\%$ do seu antecessor, à esquerda. Mesmo assim, sempre que houver truncamento ou arredondamento, reduzindo-se o número de casas decimais do número, haverá um erro. Portanto, embora saibamos que $\mathsf { P i } = \mathsf { P i }$, a matemática reconhece que Pi não é igual a 3,14.., não importa quantas casas decimais tentemos escrever.
Trazendo a questão para o campo social, é preciso considerar um axioma elementar da matemática: o da identidade formal. Por esse axioma, qualquer sentença é igual a si mesma, ou para qualquer valor de x, teremos que ${ \sf x } = { \sf x }$ Portanto, para qualquer unidade, teremos $1 ~ = ~ 1$; $2 \ = \ 2; \ldots$ É vital perceber que isso não é uma verdade absoluta: é um axioma, ou seja, uma afirmação que convencionou-se aceitar como verdadeira para que todas as demais relações matemáticas sejam válidas. Se não aceitamos que $1 = 1$, nada na matemática elementar funcionará.
Na realidade social, assumir de antemão que $1 \: = \: 1$, quando a unidade é o ser humano ou qualquer tipo de relação social, é decidir pela anulação de todas as desigualdades e diferenças, por mais evidentes que sejam. Tem-se, portanto, um relevante dilema entre o axioma matemático de que $1 ~ = ~ 1$ e a realidade social em que $1 ~ \neq ~ 1$. Há quem argumente que se pode combinar parâmetros, também numéricos, para contemplar as diferenças: será mesmo razoável supor que podemos calibrar a realidade para que caiba em um dado, que não é sequer capaz de comportar a maioria dos números reais?
Ainda, na matemática reconhecemos e estudamos problemas de transposição do número para o registro numérico computacional. No Cálculo Numérico (Arenales; Darenzo Filho, 2015; Jarletti, 2023), OS erros decorrentes de truncamento e arredondamentos são reconhecidos, dimensionados e analisados, para que se avalie se comprometem os resultados ou não. Assim, sabemos, por exemplo, que se a medida de pi for armazenada em um byte (correspondente a 8 bits), teremos um erro de $1 {, } 32\%$. Se calcularmos o comprimento de uma circunferência adotando 3,14 como valor de pi, teremos na medida do seu comprimento um erro de aproximadamente $0,005\%$. Parece pouco, mas se isso for utilizado, por exemplo, para calcular a circunferência da Terra, este erro seria de $13,5 \mathsf { k m }$ Se avançarmos para o cálculo da superfície do nosso Planeta, admitindo duas casas decimais de pi, teremos o seguinte resultado:

#### Resultado final:
Utilizar $\pi = 3,14$ em vez do valor mais preciso gera um erro de aproximadamente $402.326 ~ \mathsf { k m } ^ { 2 }$ na estimativa da área da superfície da Terra.
Fonte: ChatGPT - Pro
Figura 2: Resultado de cálculo obtido no ChatGPT
Quando avançamos para a superfície da Terra, temos uma sequência de cálculos que utiliza um número impreciso para realizar operações com outros números imprecisos. Com isso, o erro se agrava. Percentualmente, ele chega a $0 {, } 079\%$, o que também parece pouco, mas representa uma área superior à da Alemanha. E, então, precisamos nos perguntar: tratar de dimensões da superfície terrestre, admitindo um erro do tamanho da área da Alemanha, é aceitável ou não?
O Cálculo Numérico, também a aritmética de ponto flutuante utilizada em computação, tem o cuidado de não violar a matemática ao transpor o número abstrato para o dado digital. Como vimos, o erro é admitido, calculado em sua expressão absoluta, relativa ou percentual. Em seguida, é avaliado para saber se compromete os resultados ou não, o que sempre dependerá da situação concreta em que se quer utilizar os resultados.
A prudência matemática reconhece e propõe estratégia para gerir a perda de informação na transposição de um número para o dado. Então, qual a razão para que, na transposição da realidade para o dado, a perda de informação não seja reconhecida? Se há preocupação com a integridade matemática, não seria fundamental que também fosse cobrada a preocupação com a inteireza humana?
Pode-se visualizar tal processo na intercomunicação entre três dimensões, ilustradas na Figura 3a:
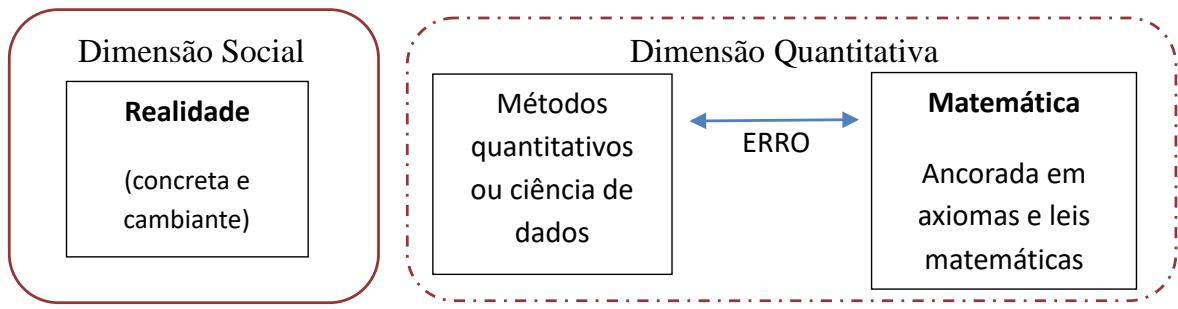
Figura 3a: Esquematização das Dimensões de Análise
Fonte: elaboração própria.
Quando dizemos que os números não mentem ou que a matemática pode oferecer infinitas respostas, estamos nos referindo estritamente à dimensão quantitativa, à direita na Figura 3a. E há diferença entre dizermos que matemática não mente e que ela dirá sempre a verdade. O conhecimento matemático ensinou a não dizer sobre aquilo que escapa ao domínio da matemática. Este talvez seja o principal ponto a ser aprendido na ciência de dados: não extrapolar suas conclusões para a dimensão social sem reconhecer o erro assumido.
Ao fazer a captação de dados da realidade para a dimensão quantitativa, quando são desconsiderados aspectos relativos a raça/cor, gênero, nível socioeconômico, região, características familiares, entre diversos outros fatores que caracterizam um indivíduo e seu contexto, estamos também incorrendo em erro. Se consideramos cada pessoa como uma unidade matemática, estamos lhe negando o valor e a influência dos múltiplos fatores que caracterizam uma pessoa em sua inteireza.
O erro causado, por assumir a premissa de que $1 = 1$, é replicado em todas as unidades transformadas em dados. Se cada uma das variáveis humanas e sociais que são transformadas em dados possui erro, ao desenvolvermos análises, ocorrerá a propagação do erro, movimento no qual ele tende a ser substancialmente modificado, incluindo possível ampliação elevada.
Um primeiro movimento necessário é que a representação numérica da realidade também seja reconhecida como parte do domínio social. Mais do que isso, os métodos quantitativos são definidos, operados e utilizados de forma não neutra, pois são construções humanas, aplicadas em contextos sociais. Por isso, propomos o reconhecimento das dimensões quantitativas como parte do domínio social, negando as tentativas de associá-lo a alguma verdade suprema. Aqui, nos limitamos ao primeiro passo: reconhecer o erro, considerando a informação perdida ao recolher a complexidade do real ao objetivismo do número com dígitos limitados.
O segundo passo é aquele ao qual convidamos a ciência de dados: assumir e dimensionar o erro e sua propagação, reconhecendo e comunicando do início ao final dos tratamentos e análises de dados. Com isso, a ciência de dados é convidada a aproximar-se mais da realidade e ter com a dimensão social a mesma responsabilidade que demonstra com a Matemática (Figura 3b):
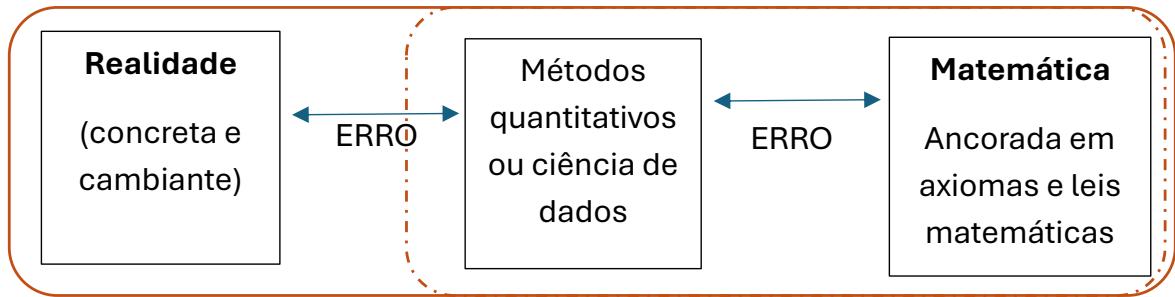
Figura 3b: Esquematização ampliada das Dimensões de Análise
Fonte: elaboração própria.
Ao adotarem axiomas matemáticos, muitos analistas deixam de explicitar que não estão considerando múltiplas diferenças: de gênero, de nível socioeconômico, de idade, de cor da pele, de localidade de residência. Na matemática, fala-se em erro admitido, o que é definido arbitrariamente. Nas evidências de políticas, propomos que seja explicitado que os resultados são verdades se considerado, por exemplo: todo estudante é igual a outro estudante; ou cada estudante pardo de qualquer município do Brasil é igual a qualquer outro estudante pardo, de qualquer outro município; quanto às escolas rurais, um estudante da região amazônica é igual a um estudante da Serra Gaúcha. Os resultados apresentados são verdadeiros exclusivamente se não considerarmos que esses marcadores são relevantes. Seja por ingenuidade, seja por perspicácia de não gerar dúvida sobre o estudo, é usual que essas limitações não sejam admitidas expressamente.
Além disso, a aplicação dos resultados como evidência para elaboração de políticas educacionais somente caberá se considerarmos que os fenômenos vindouros terão essencialmente as mesmas características dos fenômenos passados. E, neste ponto, concluímos que evidências baseadas em ciências de dados essencialmente terão a capacidade de produzir alterações incrementais e tímidas na mudança social, que poderão servir mais para dar sustentabilidade ao status quo do que para embasar transformações sociais.
Para findar este tópico, propomos que, quando não assumidas expressamente as premissas adotadas e as diferenças que estão sendo ignoradas ou consideradas como iguais, cabe reconhecer tais estudos como não legítimos. A legitimidade só pode ser conferida às pesquisas que reconheçam suas limitações e parcialidades, pois conquanto o pesquisador possa e deva estar ciente, a ocultação dessa informação gera grande risco de compreensão equivocada pelo leitor.
## II. InteligÊncia Artificial
A inteligência artificial (IA) potencializa a Iógica aqui descrita, trazendo uma nova possibilidade, que é a de incluir grande número de variáveis. Por usar de técnicas pouco compreendidas, podemos questionar se é geração de evidências ou alquimia, como desafia Filgueiras (2024). Mais especialmente, Klein e D'Ignazio (2024) alertam sobre as forças desiguais e excludentes presentes na pesquisa e desenvolvimento da inteligência artificial.
Ao mesmo tempo que a ampliação dos dados pode permitir análises mais complexas, ela traz consigo o risco de propagar o erro de forma indiscriminada (e discriminatória), especialmente pelo fato de que este erro não é assumido. O erro matemático pode ser tratado pela IA, mas o erro gerado na transposição da realidade para o dado não será - exceto se adotadas as proposições aqui apresentadas, ou outras que tenham essa mesma finalidade.
Como evidenciado por Noble (2018), os algoritmos operam sobre bases de dados enviesadas, o que frequentemente resulta em reforço de estereótipos sociais. Não sendo viável aqui aprofundar a discussão teórica, o caráter aplicado deste trabalho requer a ilustração de casos concretos.
Por exemplo, se uma das finalidades da educação é a inserção dos estudantes no mercado de trabalho, vamos propor uma atividade de pesquisa: analisar duas escolas comparativamente, verificando a situação de trabalho e renda dos estudantes após 10 anos da conclusão da educação básica. Supondo que identifiquemos que os egressos de uma das escolas têm renda média de 10 vezes a renda média dos egressos da outra escola, isso tende a levar à conclusão de que uma escola é muito mais efetiva do que a outra. Mas essa afirmação ou seu questionamento apenas fará sentido se levarmos em conta algumas das infinitas características adicionais: da escola, dos estudantes, da formação e do patrimônio dos familiares, dos seus contextos de trabalho e renda. De fato, pode-se estar diante de uma escola transformadora, ou de um sistema reprodutor. A diferenciação não é trivial e o risco de erro ao se igualar desigualdades é de extrema relevância.
Ademais, a IA opera em termos probabilísticos. A probabilidade mais elementar é baseada no princípio da aleatoriedade (Mlodinow, 2009). Porém, em questões sociais, sabemos que há muitos condicionantes (e alguns determinantes), sendo a aleatoriedade uma exceção e não a regra. Mas, na IA, os algoritmos vão muito além da probabilidade elementar. Quando se avança, há diversos mecanismos probabilísticos, muitas vezes altamente contraintuitivos, que nos trazem respostas muito reveladoras em relação àquilo que não percebemos facilmente, mas cujas conclusões encontram total amparo nos dados analisados. Ao trazer constatações contraintuitivas e sem que seja factível rastrear todos os caminhos até as conclusões, a IA pode indicar alternativas que supostamente nos levariam a soluções, mas que de fato podem estar nos distanciando dos problemas estruturais e reproduzindo as desigualdades sociais, precisamente por ignorá-las.
Técnicas adotadas em IA permitem que as análises considerem múltiplas variáveis, mas não são capazes de considerar nada que não esteja presente nos dados disponíveis. E há poucos dados disponibilizados aos algoritmos sobre as heranças recebidas (materiais e imateriais), sobre a qualidade da água a que se teve acesso, sobre o quão alinhado com os valores econômicos atuais eram os valores cultivados em sua comunidade de origem, sobre quem era preferido para ser pego no colo nas creches, olhado com afeto, elogiado, menos ameaçado pela violência, com melhor acesso à saúde. Há inúmeros outros fatores que influenciam sobremaneira no desenvolvimento humano e social e, portanto, na educação. Fatores de desigualdades tão vastos que, se não podem ser equiparados a números irracionais, também dificulta trata-los como racionais.
## III. Uma ProposiçÃo
Se nos preocupamos quando ocorre a mutilação do número, pela incapacidade de ele ser representado em sua inteireza por mecanismos computacionais, não seria razoável que, no mínimo, tenhamos este cuidado também ao tratar de pessoas e questões sociais?
Então, propomos que essa perda de informação seja reconhecida e, em analogia ao que se aborda em cálculo numérico, passemos a colocar uma vírgula após a unidade genérica, para qualificarmos essa unidade:

Fonte: elaboração própria. Figura 4: Proposta de expressão para evidências em políticas educacionais
Como já tratado, na transposição da matemática para o dado, quanto mais à direita da unidade o dígito estiver, menor será seu valor. Na transposição da realidade para o dado, isso se modifica: quanto mais distantes da unidade padrão estiver uma característica humana ou social, mais ela tende a gerar erro caso seja desconsiderada. Por isso, aqui, não podemos utilizar características sucessivas, como se houvesse hierarquia entre as múltiplas dimensões do ser. Todavia, ao menos para estudos que compreendam a realidade brasileira, há elementos estruturantes que precisam ser colocados em evidência.
Assim, propomos que o "1, vírgula" seja seguido das características que tenham mais relevância no foco do estudo. No caso da educação aplicada à realidade brasileira, propõe-se que os elementos mínimos sejam: raça/cor, gênero, nível socioeconômico, região. Estudos que busquem construir evidências para fundamentar as políticas educacionais, mas que não considerem ao menos esses aspectos, tanto separadamente quanto de modo interseccional, não podem ser adotados como referência qualificada para orientar políticas educacionais que visem à qualidade com equidade.
Portanto, do mesmo modo que a divulgação de pesquisas de intenção de voto inclui informação sobre suas margens de erro, propomos que estudos que envolvam a transposição da realidade para o dado explicitem se adotam ou não os principais fatores interseccionais. Caso contrário, propõe-se que passe a ser explicitada essa ausência, com a indicação de que a validade do estudo está restrita à consideração de que $1 = 1$.
## IV. CONSIDERAÇÕES FINAIS
Pelas discussões aqui apresentadas, esperamos ter elucidado suficientemente a necessidade de que a perda de informação da transposição da realidade para o dado seja reconhecida como aspecto metodológico na ciência de dados, quando aplicada às ciências sociais e, mais especificamente, à educação. Como tal, que a pressuposição de que as unidades são todas iguais seja explicitada, indicando que, caso se considere que características individuais ou contextuais conferem a cada "1" condições diferentes, então as evidências devem ser consideradas como de menor confiabilidade.
Quando ocultamos as medidas do erro, ou não utilizamos, na ciência de dados, esse aprendizado para o diálogo com a outra dimensão (a realidade), assumimos o risco de estarmos mentido pela matemática e por nós mesmos. Podemos, também, estar engendrando técnicas apuradas, linguagem rebuscada e assertivas contundentes para construir um esconderijo para nossos próprios preconceitos, que não queremos que sejam vistos, mas não nos dispomos a abandonar.
Generating HTML Viewer...
Funding
No external funding was declared for this work.
Conflict of Interest
The authors declare no conflict of interest.
Ethical Approval
No ethics committee approval was required for this article type.
Data Availability
Not applicable for this article.
Dr. Valdoir Pedro Wathier. 2026. \u201cOne with an Asterisk A Request to the Creators of Quantitative Evidence in Educational Policies\u201d. Global Journal of Human-Social Science - G: Linguistics & Education GJHSS-G Volume 25 (GJHSS Volume 25 Issue G4): .
Our website is actively being updated, and changes may occur frequently. Please clear your browser cache if needed. For feedback or error reporting, please email [email protected]
×
This Page is Under Development
We are currently updating this article page for a better experience.
Thank you for connecting with us. We will respond to you shortly.



































































